









1 背景
本文的目标是仅使用MySql一款中间件,解决10万人同一时间开始线上考试的场景,为了更好的量化场景,详细描述如下:
-
支持10万人同一时间进入同一场考试,开始答题
-
10万人做的试卷是同一套,题目内容相同,但是题目顺序不同
-
支持10万人同时提交试卷,并随即查看试卷答案,得多少分
仅使用MySql中间件,如何实现以上述求呢?
2 业务分析
基于背景分析,可知道有以下几个用户故事:
-
户故事1:用户进入考试,看到试卷
-
用户故事2:用户答题
-
用户故事3:用户提交试卷,等待后,系统展示答题成功,用户看到自己得分
以上三个故事中,1和3是有后端并发技术场景的,具体如下:
-
10万人同时打开同一个试卷,造成前端大量访问“试卷查询接口”(特点:读多、单点数据)
-
10万人同时提交各自的答卷,造成前端大量访问“试卷答案提交接口”(特点:写多)
我们就以上两个明确的技术场景进行技术方案设计。
3 技术方案
部署拓扑图如下:
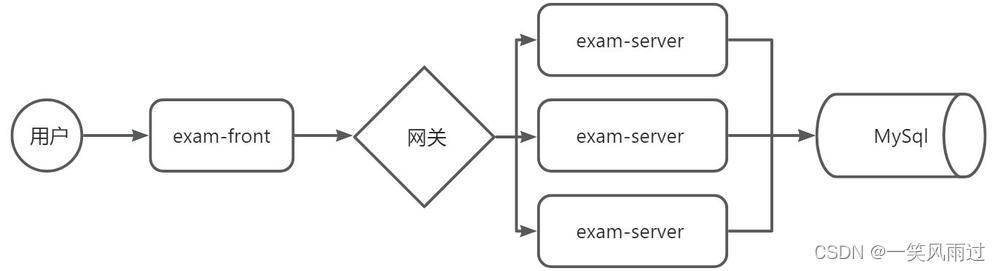
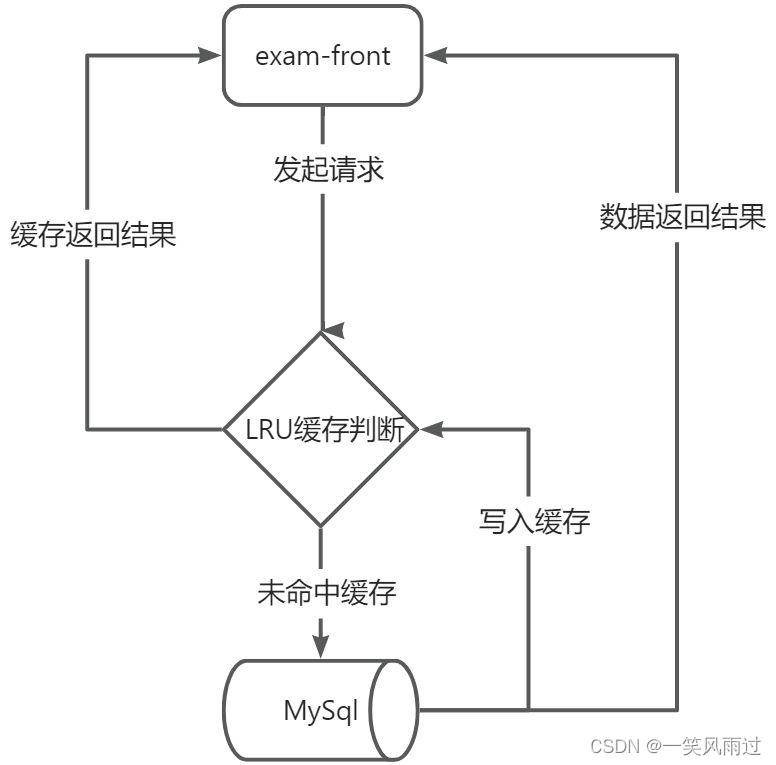
3.1 试卷查询接口
考试系统并不是常规意义上的高并发系统,而是有明确固定时间的业务高峰,并且热点数据不多、不分散,针对这样的场景,我们可以把热点数据方案缓存到应用实例的内存中,并通过LRU算法,保存最近的100条数据即可。接口流程如下:
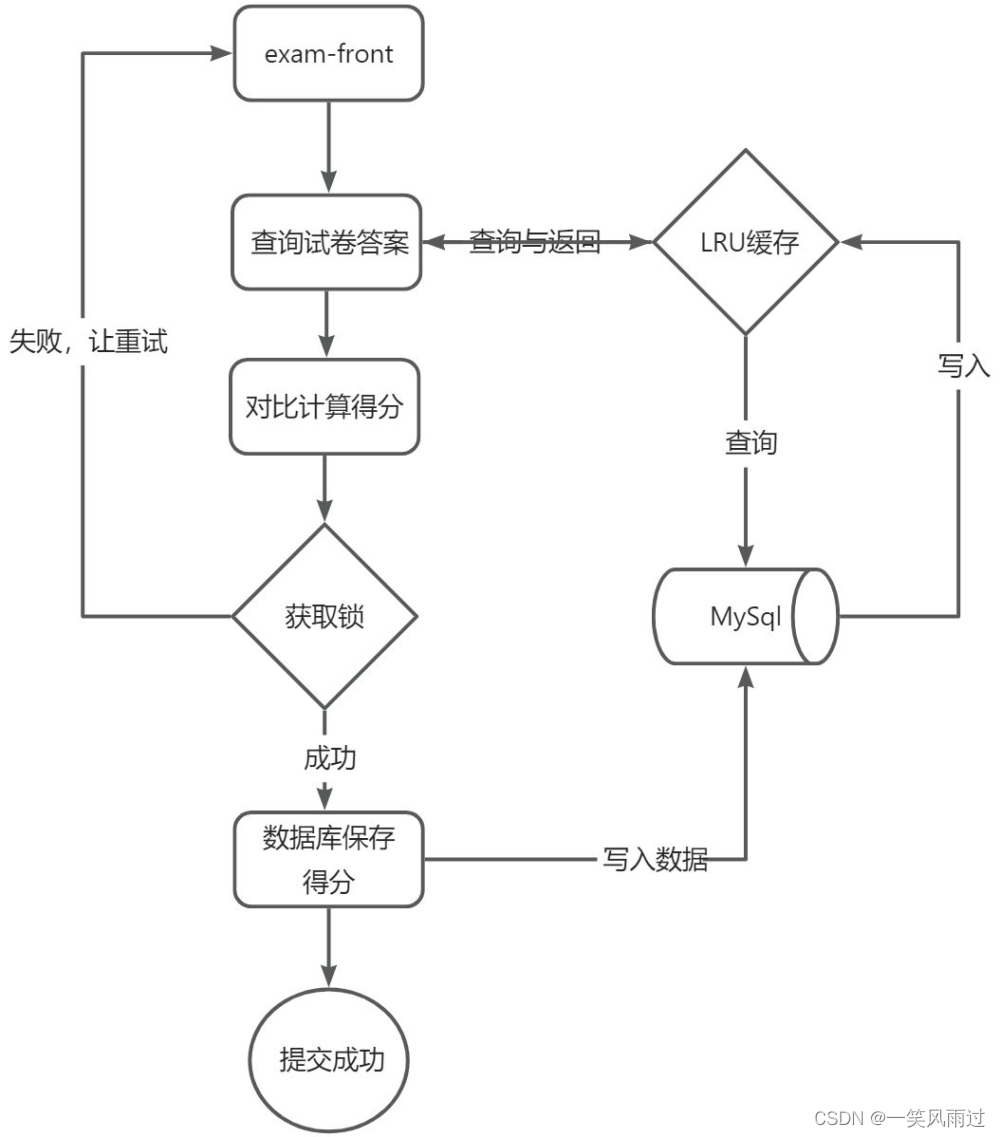
3.2 试卷答案提交接口
试卷答案提交接口内部存在两个与数据库的交互场景:
1、查询试卷答案 2、保存用户的答题与得分。针对第一点,继续使用LRU缓存即可,这样即可快速地在内存中计算出试卷得分。第二点略微棘手,只使用MySql会有点捉襟见肘,不过还是有思路的,如下:
-
评估出MySql支持的向数据库写的最大并发是n,假设部署8个exam-server实例,那么每一个exam-server实例的提交试卷答案最大并发是n/8
-
在单个exam-server内部设置计数器,确保单实例同时最多只能处理n/8个请求,超出的请求直接报错返回
-
前端检测ajax接口提交失败,并且是因为计数器超出,界面继续提示“答案提交中,请勿刷新页面…”,实际等待1秒后继续发起接口请求,提交答案
如此反复,直至提交成功
4.整个流程设计如下:
4 非业务需求
4.1 如何计算n
诚然我们可以准确的知道数据库的配置,例如2C4G或者4C8G等,进而推导出写入的最高并发n是多少。
但我个人认为最好的办法,还是将以上架构设计编码出来后,实际中进行压测,通过反复对n值、数据库配置、部署实例数进行调整,获得应对10万用户并发提交能够较好处理时,n值是多少。
这也是在日常工作中的一个窍门,面对高并发,最后一定要通过实战压测,验证是否能够满足要求。
4.2 如何设计锁
我们可以使用JDK中的原子计数器,如AtomicInteger、AtomicLong等,通常使用AtomicInteger即可。获取锁的逻辑也非常简单,如下:
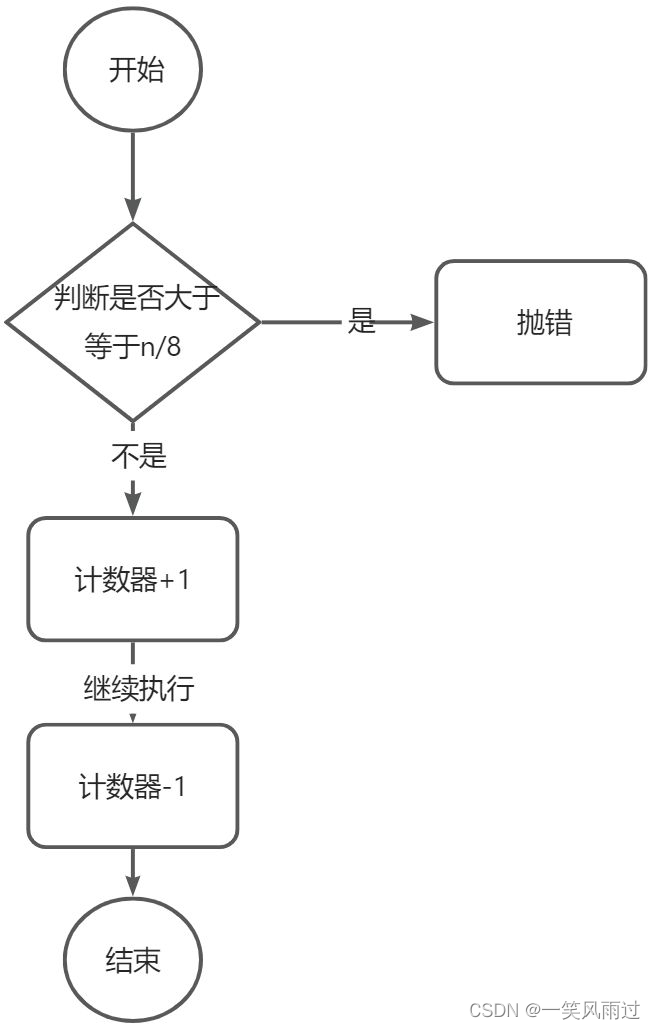
伪代码如下:
@ExtendWith(MockitoExtension.class)
public class LockTest {
final static Integer max = 60; // 假设最多60个线程同时写
final AtomicInteger lock = new AtomicInteger(0);
@Test
void calculateAndCommit() {
// 判断是否大于max
if (lock.incrementAndGet() > max) {
lock.decrementAndGet();
throw new RuntimeException("并发过大,请重新提交");
}
try {
// todo 业务逻辑
} catch (Exception e) {
e.printStackTrace();
} finally {
lock.decrementAndGet();
}
}
}
`
4.3 应用实例到底部署几个
首先是要确保流量是均匀代理到各个应用实例的,这个通常是默认的。
我们要知道,tomcat默认线程池200,因此每台实例的计数器最大通常不应该超过200,再结合有其他一些请求,就不建议超过150吧。
假设n是800,那么800/150约等于6,那就得部署6台实例。
4.4 性能冗余
在数据库配置不变的情况下,我们应当考虑多冗余一些性能,有哪些地方可以冗余呢?
把每台实例的计数器最大值设置小一些,确保数据库不会因为高并发蹦掉,确保大部分用户是可用的。
并发写总数不超过n的前提下,多部署几台实例
多部署几个网关,避免网关出问题
5 总结
以上便是仅用MySql解决十万人同时在线考试并发场景的解决思路,核心就是牺牲部分用户的体验,通过限流的策略,确保高并发不会冲垮MySql,直至处理
完所有的请求。 肯定还有更好的方案,大家多多讨论。
至于为什么只用MySql,而没有用redis、kafka这些中间件,第一个原因是成本,第二个原因是因为认为10万人考试,还到不了用这些中间件的地步。
这个方案总结起来就是:本地缓存 + 漏斗限流(文中的到锁)
-
锁机制的实现能放到网关吗?放到网关就是网关做限流
-
如果引入redis,如何实现呢?结合Reids可以做热数据的二级缓存。但如果每个人的题目只是顺序不同(包括题目顺序不同、选项顺序不同),那么本
质上只有一套题,本地缓存应该是够了,可以在前端打乱顺序
有办法让用户体验更好、更快吗?用户体验主要是提交答案可能不成功的等待,受限单库写入性能,可以设计多库写入来提升写并发
6 思考
1.锁机制的实现能放到网关吗?
2.如果引入redis,如何实现呢?
3.有办法让用户体验更好、更快吗?(本文方案,实际是牺牲了部分用户的体验)
4.列举各个方案,对比优缺点
5…















 1054
1054











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









