







目的
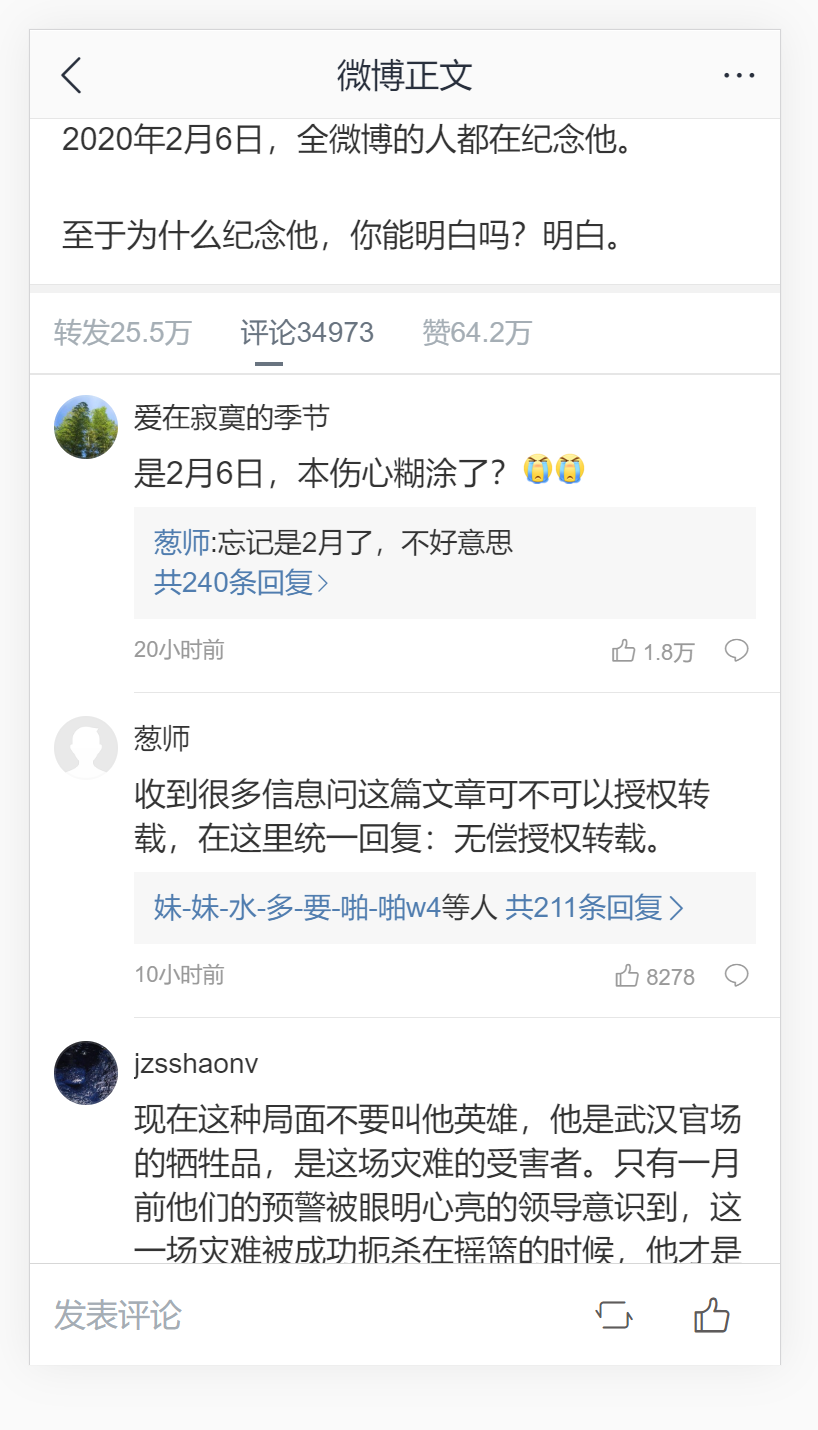
爬取微博移动端的评论数据(如下图),然后将数据保存到.txt文件和.xlsl文件中。
实现过程
实现的方法很简单,就是模拟浏览器发送ajax请求,然后获取后端传过来的json数据。
一、找到获取评论数据的ajax请求
按下F12,打开控制台,找到以下请求
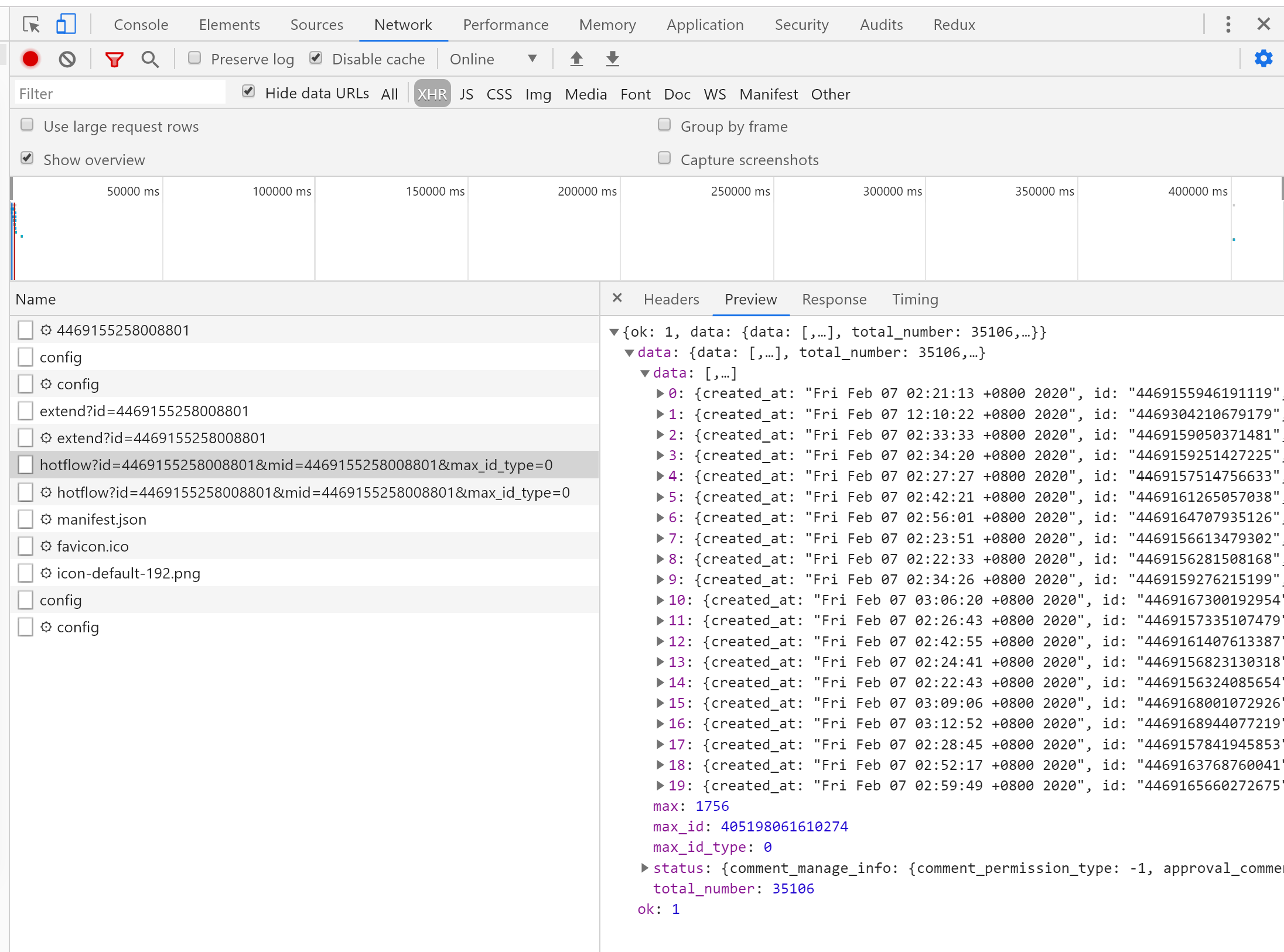
以 https://m.weibo.cn/detail/4467454577673256 为例,得到的ajax请求是这样的:
https://m.weibo.cn/comments/hotflow?id=4467454577673256&mid=4467454577673256&max_id_type=0
然后,我们往下滚动屏幕,再观察几个获取评论数据的ajax请求(篇幅有限,只看两个),看有什么规律。
https://m.weibo.cn/comments/hotflow?id=4467454577673256&mid=4467454577673256&max_id=142552137895298&max_id_type=0
https://m.weibo.cn/comments/hotflow?id=4467454577673256&mid=4467454577673256&max_id=139116183376416&max_id_type=0
可以看到这几个ajax都有几个共同的部分:
- https://m.weibo.cn/comments/hotflow?
- id=4467454577673256
- mid=4467454577673256
- max_id_type=0
其中,id和mid的数值为微博链接的最后一串数字,max_id_type都为0(但事实上,不总为0,后面会讲)。到这一步,我们可以模拟获取评论数据的第一个ajax请求了,因为它就是由上面这些组成的。而后面的那些ajax请求,则是多了一个max_id参数。经过观察,该参数是从前一个ajax请求返回的数据中得到的。以前面第二个ajax请求为例:
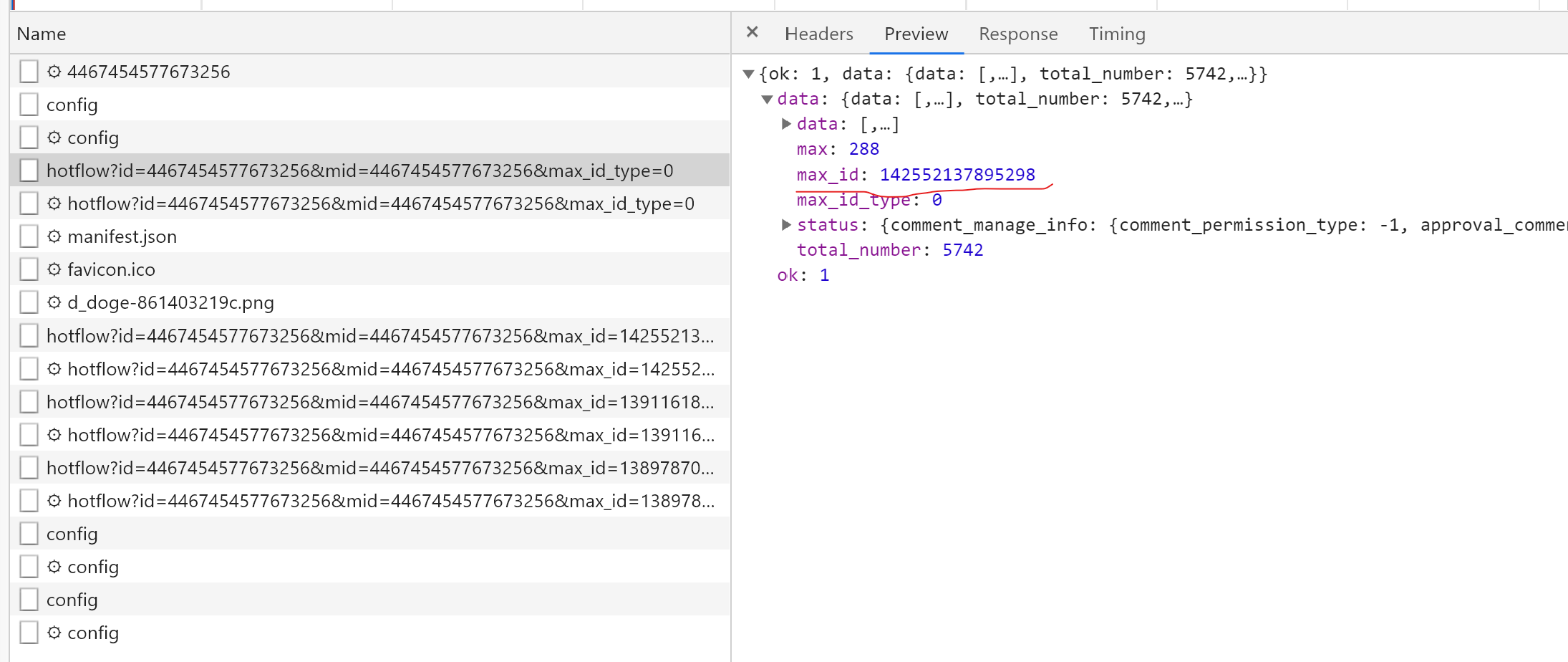
该请求中的max_id参数就是由从第一个ajax请求的max_id字段中得到。所以,后续的操作就是:
- 根据baseurl,id,mid,获取第一个ajax请求中的数据,然后将有用的评论信息数据保存到数组中,并返回一个max_id字段。
- 模拟浏览器,根据前面获得的max_id字段,以及baseurl,id,mid发送下一个ajax请求,将评论数据结果append到前一次的结果中。
- 循环第2步max次,其中max为发送ajax的次数(好像是错的,循环次数应该是≤max,自行打印试试),该字段由上面截图的max字段可得,初始值为1。
- 最终,将评论数据结果保存到.txt和.xlsx文件中。
二、获取ajax请求的数据
获取数据的方式有很多,我选择了request.get()来获取。
web_data = requests.get(url, headers=headers,timeout=5)
js_con = web_data.json()
使用以上代码,我们可以很轻松的获取第一个请求的数据。但是到获取第二第三个请求的数据时,就会报错。原因是没有加入Cookies。于是乎,我就在Request Headers中找含有Coookies的数据信息,结果全部文件找了一遍都没有。因此,我决定把微博站点的所有Cookies字段值都敲进去。如下。
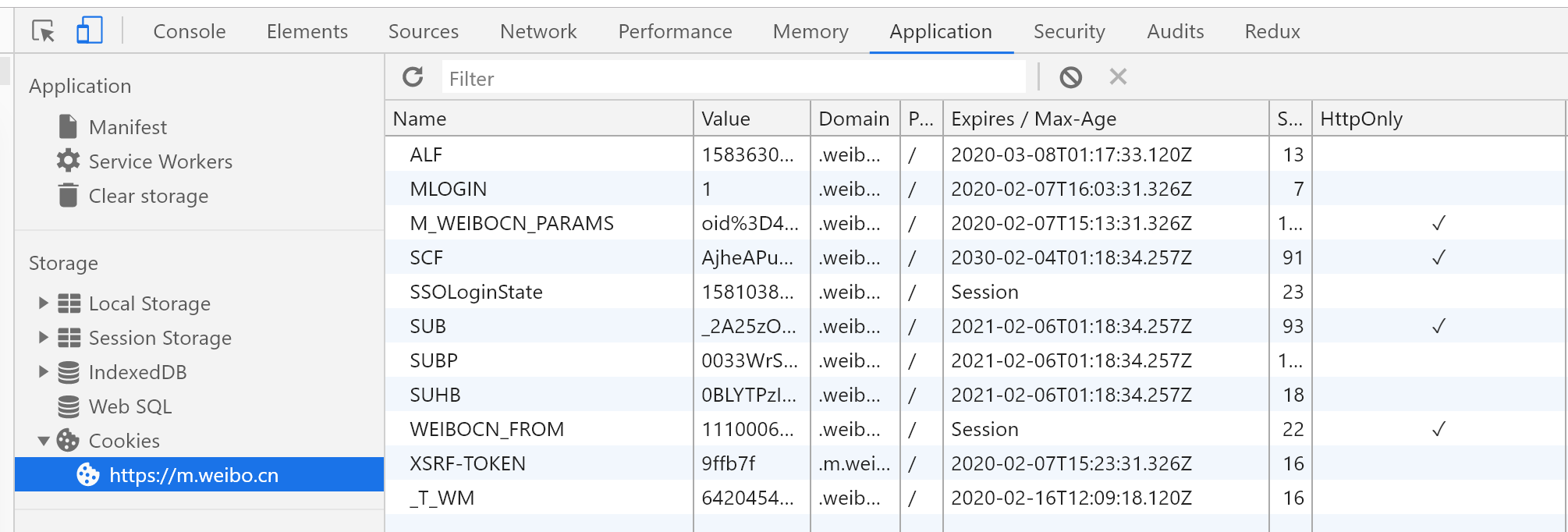
因此,解决了cookie问题之后,我们测试一下看是否能获取后面所有ajax请求的数据。答案是:no.
经无数次测试,在爬取第17次请求的数据时,总是抛出异常。而原因则是我们前面所提及的,max_id_type不总是等于0,当发送第17次请求时max_id_type等于1。

于是到这一步,我们基本就可以爬取所有的数据了。但还是有一个小问题。就是有些微博的评论开启了精选模式,只显示回复数最多的几个评论。比如这个示例:
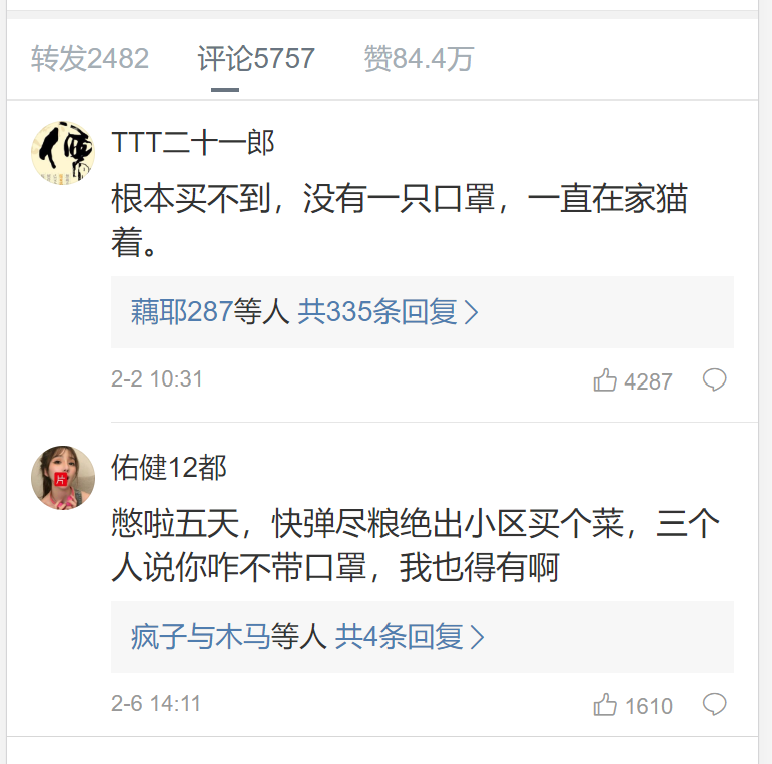
虽然上面写着有5757条评论,但是后端只返回17条数据到前端。因此,如果按照前面的思维,循环max次发送ajax请求的话是会报错的,因此解决该问题的方法就是判断该ajax请求返回的数据中是否包含{ok: 0}(其他有效的返回结果都为ok:1)。如果有,则说明这个请求及之后的请求是无效的,不用一直循环下去,直接将结果保存到.txt和.xlsx文件即可。
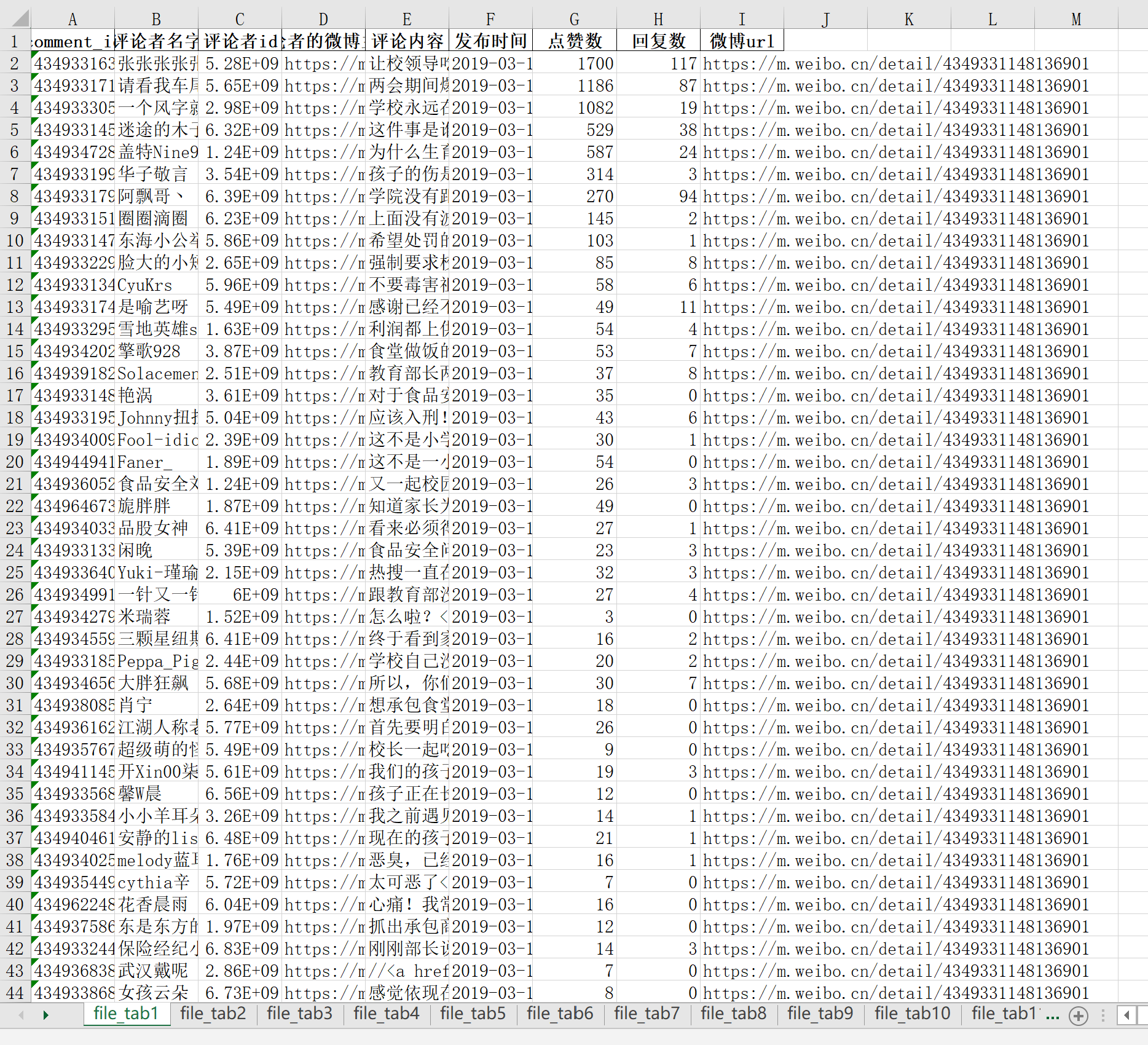
三、将数据保存到txt和excel中
将数据导出到这两种文件的代码,网上应有尽有,这里不加赘述。但是,这里要说明的是:因为要存储多个微博的评论数据,所以excel中要分不同sheet来存储;而txt中的数据仅仅是为了随便看看,所以微博的评论数据都追加到这里面。

四、源代码
comment.py(主文件)
import requests
import pandas as pd
import time
import openpyxl #导出excel需要用到
from config import headers,url,Cookie,base_url,weiboComment,excel_name,txt_name
#将中国标准时间(Sat Mar 16 12:12:03 +0800 2019)转换成年月日
def formatTime(time_string, from_format, to_format='%Y.%m.%d %H:%M:%S'):
time_struct = time.strptime(time_string,from_format)
times = time.strftime(to_format, time_struct)
return times
# 爬取第一页的微博评论
def first_page_comment(weibo_id, url, headers):
try:
url = url + str(weibo_id) + '&mid=' + str(weibo_id) + '&max_id_type=0'
web_data = requests.get(url, headers=headers,cookies = Cookie,timeout=20)
js_con = web_data.json()
# 获取连接下一页评论的max_id
max_id = js_con['data']['max_id']
max = js_con['data']['max']
comments_list = js_con['data']['data']
for commment_item in comments_list:
Obj = {
'commentor_id':commment_item['user']['id'],
'commentor_name':commment_item['user']['screen_name'],
'commentor_blog_url':commment_item['user']['profile_url'],
'comment_id':commment_item['id'],
'comment_text':commment_item['text'],
'create_time':formatTime(commment_item['created_at'],'%a %b %d %H:%M:%S +0800 %Y','%Y-%m-%d %H:%M:%S'),
'like_count':commment_item['like_count'],
'reply_number':commment_item['total_number'],
'full_path':base_url+str(weibo_id),
'max_id': max_id,
'max':max
}
commentLists.append(Obj)
print("已获取第1页的评论")
return commentLists
except Exception as e:
print("遇到异常")
return []
#运用递归思想,爬取剩余页面的评论。因为后面每一页的url都有一个max_id,这只有从前一个页面返回的数据中获取。
def orther_page_comments(count,weibo_id, url, headers,max,max_id):
if count<=max:
try:
if count<15:
urlNew = url + str(weibo_id) + '&mid='+ str(weibo_id) + '&max_id=' + str(max_id) + '&max_id_type=0'
else:
urlNew = url + str(weibo_id) + '&mid=' + str(weibo_id) + '&max_id=' + str(max_id) + '&max_id_type=1'
web_data = requests.get(url=urlNew, headers=headers,cookies = Cookie,timeout=10)
#成功获取数据了,才执行下一步操作
if web_data.status_code == 200:
js_con = web_data.json()
# print('js_con:', js_con)
#评论开启了精选模式,返回的数据为空
if js_con['ok']!=0:
# 获取连接下一页评论的max_id
max_id = js_con['data']['max_id']
max = js_con['data']['max']
comments_list = js_con['data']['data']
# print('comments_list:',comments_list)
for commment_item in comments_list:
Obj = {
'commentor_id':commment_item['user']['id'],
'commentor_name':commment_item['user']['screen_name'],
'commentor_blog_url':commment_item['user']['profile_url'],
'comment_id':commment_item['id'],
'comment_text':commment_item['text'],
'create_time':formatTime(commment_item['created_at'],'%a %b %d %H:%M:%S +0800 %Y','%Y-%m-%d %H:%M:%S'),
'like_count':commment_item['like_count'],
'reply_number':commment_item['total_number'],
'full_path':base_url+str(weibo_id),
'max_id': max_id,
'max':max
}
commentLists.append(Obj)
count += 1
print("已获取第" + str(count+1) + "页的评论。")
orther_page_comments(count,weibo_id,url,headers,max,max_id)#递归
return commentLists
else:
return []
except Exception as e:
if count==1:
print("遇到异常,爬虫失败") #假设连第一条数据都没有爬到,我就认为是爬虫失败
else:
return
#将数据保存到excel中的不同sheet中
def export_excel(exportArr,id,sheetName):
#创建sheet
# wb = openpyxl.load_workbook(excel_name)
# wb.create_sheet(title=sheetName, index=0)
# wb.save(excel_name)
#将数据保存到sheet中
pf = pd.DataFrame(exportArr) #将字典列表转换为DataFrame
order = ['comment_id','commentor_name','commentor_id','commentor_blog_url','comment_text','create_time','like_count','reply_number','full_path'] #指定字段顺序
pf = pf[order]
#将列名替换为中文
columns_map = {
'comment_id':'comment_id',
'commentor_name':'评论者名字',
'commentor_id':'评论者id',
'commentor_blog_url':'评论者的微博主页',
'comment_text':'评论内容',
'create_time':'发布时间',
'like_count':'点赞数',
'reply_number':'回复数',
'full_path':'微博url',
}
pf.rename(columns=columns_map, inplace=True)
pf.fillna(' ',inplace = True) # 替换空单元格
pf.to_excel(file_path,encoding = 'utf-8',index = False,sheet_name=sheetName) #输出
print('----------第',id,'篇微博的评论已经保存了---------------')
return 'true'
#将数据保存到txt文件中
def export_txt(list,txtId):
arr = [str(txtId),' ',list['full_path'],' ',list['commentor_name']]
commentorNameMaxLen = 20 #假设最大的长度为20,不足20的以空格代替,确保长度一致,避免参差不齐
lenGap = commentorNameMaxLen - len(list['commentor_name'])
for i in range(lenGap):
arr.append('-')
arr.append(list['comment_text'])
arr.append('\n') #每一行结束要换行
file_handle.writelines(arr)
if __name__ == "__main__":
output = []
commentLists = [] # 初始化存储一个微博评论数组
weibo_comment = weiboComment
file_path = pd.ExcelWriter(excel_name) # 指定生成的Excel表格名称
txt_id = 1 # 用于记录txt数据的id
file_handle = open(txt_name, mode='w',encoding='utf-8') # 打开txt文件
file_handle.writelines(['id ','微博链接 ','评论者',' ','评论内容\n']) #写入头部的字段名字
#存储每一篇微博的评论数据
for ind,item in enumerate(weibo_comment):
output = first_page_comment(item['weibo_id'], url, headers)
if len(output)>0:
maxPage = output[-1]['max']
maxId =output[-1]['max_id']
#如果结果不只一页,就继续爬
if(maxPage!=1):
ans = orther_page_comments(0,item['weibo_id'], url, headers,maxPage,maxId)
# 如果评论开启了精选模式,最后一页返回的数据是为空的
if ans!=[]:
bool = export_excel(ans,item['id'],item['sheet_name'])
else:
bool = export_excel(commentLists,item['id'],item['sheet_name'])
if bool=='true':
commentLists = [] #将存储的数据置0
for list in ans:
txt_id = txt_id + 1 # 用于记录txt数据的id
export_txt(list, txt_id)
else:
print('----------------该微博的评论只有1页-----------------')
file_path.save() #保存到表格
file_handle.close() #保存到txt
config.py
base_url = 'https://m.weibo.cn/detail/'
url = 'https://m.weibo.cn/comments/hotflow?id='
excel_name = r'weibo_comments.xlsx'
txt_name = 'weibo_comments.txt'
# 参考代码:https://www.cnblogs.com/pythonfm/p/9056461.html
ALF = 1583630252
MLOGIN = 1
M_WEIBOCN_PARAMS = 'oid%3D4469046194244186%26luicode%3D10000011%26lfid%3D102803%26uicode%3D10000011%26fid%3D102803'
SCF = 'AjheAPuZRqxmyLT-kTVnBXGduebXE6nZGT5fS8_VPbfADyWHQ_WyoRzZqAJNujugOFYP1tUivrlzK2TGTx83_Qo.'
SSOLoginState = 1581038313
SUB = '_2A25zOMq5DeRhGeNM6FUX8S_EzDqIHXVQwtbxrDV6PUJbktAKLVPhkW1NTjKs6wgXZoFv2vqllQWpcwE-e9-8LlMs'
SUBP = '0033WrSXqPxfM725Ws9jqgMF55529P9D9W58TWlXMj17lMMvjhSsjQ1p5JpX5K-hUgL.Fo-Ee0MceK2RS0q2dJLoIEXLxKqLBozL1h.LxKML1-BLBK2LxKML1-2L1hBLxK-LBKqL12BLxK-LBKqL12Bt'
SUHB = '0BLYTPzIKSGsDo'
WEIBOCN_FROM = 1110006030
XSRF_TOKEN = '5dcf70'
_T_WM = 64204543757
Cookie = {
'Cookie': 'ALF={:d};MLOGIN={:d};M_WEIBOCN_PARAMS={};SCF={};SSOLoginState={:d};SUB={};SUBP={};SUHB={};WEIBOCN_FROM={:d};XSRF-TOKEN={};_T_WM={:d};'.format(
ALF,
MLOGIN,
M_WEIBOCN_PARAMS,
SCF,
SSOLoginState,
SUB,
SUBP,
SUHB,
WEIBOCN_FROM,
XSRF_TOKEN,
_T_WM
)
}
headers = {
'Sec-Fetch-Mode': 'cors',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest', # 通过ajax请求形式获取数据
'X-XSRF-TOKEN': 'aa8bed',
'Accept': 'application/json, text/plain, */*'
}
# 数据id号,要爬取的微博的id号,以及导出到excel对应的sheet名
weiboComment = [{
'id':1,
'weibo_id': 4349331148136901,
'sheet_name': 'file_tab1',
},{
'id':2,
'weibo_id': 4349336798569857,
'sheet_name': 'file_tab2',
},{
'id':3,
'weibo_id': 4349342632452485,
'sheet_name': 'file_tab3',
},{
'id':4,
'weibo_id': 4349359489249263,
'sheet_name': 'file_tab4',
},{
'id':5,
'weibo_id': 4349367202366649,
'sheet_name': 'file_tab5',
},{
'id':6,
'weibo_id': 4349409263609558,
'sheet_name': 'file_tab6',
},{
'id':7,
'weibo_id': 4349473562085041,
'sheet_name': 'file_tab7',
},{
'id':8,
'weibo_id': 4349476527153453,
'sheet_name': 'file_tab8',
},{
'id':9,
'weibo_id': 4349484396400084,
'sheet_name': 'file_tab9',
},{
'id':10,
'weibo_id': 4349520848132903,
'sheet_name': 'file_tab10',
},{
'id':11,
'weibo_id': 4349719763185960,
'sheet_name': 'file_tab11',
},{
'id':12,
'weibo_id': 4349801526543328,
'sheet_name': 'file_tab12',
},{
'id':13,
'weibo_id': 4350037775161542,
'sheet_name': 'file_tab13',
},{
'id':14,
'weibo_id': 4350053403309300,
'sheet_name': 'file_tab14',
},{
'id':15,
'weibo_id': 4350126740919864,
'sheet_name': 'file_tab15',
},{
'id':16,
'weibo_id': 4350129907409012,
'sheet_name': 'file_tab16',
},{
'id':17,
'weibo_id': 4350130469806786,
'sheet_name': 'file_tab17',
},{
'id':18,
'weibo_id': 4350133967955764,
'sheet_name': 'file_tab18',
},{
'id':19,
'weibo_id': 4350135909606542,
'sheet_name': 'file_tab19',
},{
'id':20,
'weibo_id': 4350218999265612,
'sheet_name': 'file_tab20',
},{
'id':21,
'weibo_id': 4350440310723864,
'sheet_name': 'file_tab21',
},{
'id':22,
'weibo_id': 4350520937742523,
'sheet_name': 'file_tab22',
},{
'id':23,
'weibo_id': 4350785468613341,
'sheet_name': 'file_tab23',
},{
'id':24,
'weibo_id': 4350785615363253,
'sheet_name': 'file_tab24',
},{
'id':25,
'weibo_id': 4350789927730012,
'sheet_name': 'file_tab25',
},{
'id':26,
'weibo_id': 4350789751053448,
'sheet_name': 'file_tab26',
},{
'id':27,
'weibo_id': 4350780188153079,
'sheet_name': 'file_tab27',
},{
'id':28,
'weibo_id': 4350791797481716,
'sheet_name': 'file_tab28',
},{
'id':29,
'weibo_id': 4350797737493161,
'sheet_name': 'file_tab29',
},{
'id':30,
'weibo_id': 4350798441501055,
'sheet_name': 'file_tab30',
},{
'id':31,
'weibo_id': 4350800991931397,
'sheet_name': 'file_tab31',
},{
'id':32,
'weibo_id': 4350974611001741,
'sheet_name': 'file_tab32',
},{
'id':33,
'weibo_id': 4351283193709752,
'sheet_name': 'file_tab33',
}]















 714
714











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









