










在阿里云上部署Hadoop集群报错,无法启动namenode
org.apache.hadoop.hdfs.server.namenode.NameNode: Failed to start namenode.
java.net.BindException: Problem binding to [Namenode:9000] java.net.BindException: Cannot assign requested address; For more details see: http://wiki.apache.org/hadoop/BindException
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
Fast-forwarding stream '/opt/modules/hadoop-2.5.0/data/tmp/dfs/name/current/edits_0000000000000000001-0000000000000000002' to transaction ID 1
2019-09-30 19:43:43,084 INFO org.apache.hadoop.hdfs.server.namenode.FSImage: Edits file /opt/modules/hadoop-2.5.0/data/tmp/dfs/name/current/edits_0000000000000000001-0000000000000000002 of size 42 edits # 2 loaded in 0
解决办法:(之前在虚拟机部署的时候,只是把三个集群的ip和映射名部署好了,但是使用云服务器部署的时候要配置)
在vi /etc/hosts 里面配置公网和内网的ip
内网IP地址 你的hostname
公网IP地址 别的hostname
(类似这种,如果部署的是伪分布式直接hostname填写相同就行)
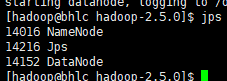
之后重新启动















 706
706











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









