







全程root用户操作
一、准备工作
1.安装jdk
可以参考:https://blog.csdn.net/qq_29244221/article/details/80403772
记得设置jdk环境变量
2.安装hadoop
(一)下载Hadoop
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.9.2/hadoop-2.9.2.tar.gz
(二)解压
wget默认下载到登陆路径~也就是/home/user,linux下安装路径一般是/usr/local,所以解压到那里。
sudo tar -zxf ~/hadoop-2.9.2.tar.gz -C /usr/local
(三)检查
cd /usr/local/hadoop-2.9.2
./bin/hadoop version
(四)将Hadoop添加到环境变量
vi /etc/profile
#hadoop
export HADOOP_HOME=/usr/local/hadoop-2.9.2
export PATH=$PATH:$HADOOP_HOME/bin:$PATH
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_OPTS="- Djava.library.path=$HADOOP_HOME/lib:$HADOOP_COMMON_LIB_NATIVE_DIR"
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
(五)让修改后的文件生效
source /etc/profile
(六)测试是否安装成功
hadoop version
 如果hadoop版本正常出现,配置错误,找找细节
如果hadoop版本正常出现,配置错误,找找细节
3.阿里云控制台,修改安全组


二、本地(单机配置)``
官方WordCount案例
在hadoop-2.9.2文件下面创建一个wcinput文件夹
mkdir wcinput
在wcinput文件下创建一个wc.input文件
cd wcinput
编辑wc.input文件
vi wc.input
在文件中输入如下内容
hadoop yarn
hadoop mapreduce
atguigu
atguigu
回到Hadoop目录
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar wordcount wcinput wcoutput
查看结果
cat wcoutput/part-r-00000
三、伪分布
配置/etc/hadoop目录下的 vi core-site.xml
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://0.0.0.0:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop-2.9.2/data/tmp</value>
</property>
配置/etc/hadoop目录下的 vi hdfs-site.xml
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>0.0.0.0:50070</value>
</property>
格式化NameNode
bin/hdfs namenode -format
启动NameNode
sbin/hadoop-daemon.sh start namenode
启动DataNode
sbin/hadoop-daemon.sh start datanode
查看是否启动成功
jps
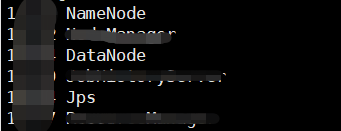
表示启动成功,接下来可以使用web访问hadoop界面
http://[阿里云公网ip]:50070/
















 1212
1212











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









