






欢迎来到统计世界。
统计数据不仅仅是计算平均值、中位数和众数。它是收集、组织、评估和推断事实以便做出判断的科学。
描述性统计是一种通过生成有关数据样本的摘要来描述数据集特征的方法。它有助于改进数据分析和识别数据集的趋势。
描述性统计分为集中趋势度量和变异性(传播)度量。
均值、中位数和众数是集中趋势的度量;
标准差、方差、最小和最大变量、峰度和偏度是变异性的度量。
描述性统计的类型
集中趋势
我们使用平均值、中位数和众数来量化数据的“中心”。它用于假设检验、回归等等。集中趋势度量描述了数据集分布的中心位置。
变异性度量
变异性度量(或分布度量)有助于分析一组数据的分布分散程度。
例如,虽然集中趋势的度量可以为一个人提供一组数据的平均值,但它不能表征数据集内数据的分布。
频率分布
它是一种图形或表格格式的表示形式,显示给定间隔内的观测值数。
让我们从最基本的构建块开始。
意味 着:它是数据中所有观测值的平均值。平均值用 x̄ 表示。
平均值,x̄ = (∑xi fi) /(∑fi)
中位数: 当观测值为奇数时,中位数为中间观测值;当存在偶数时,中位数是两个中间值的平均值。
如果 n 为奇数,则中位数 = 第(n+1)/2 个观测值;
如果 n 为偶数,则中位数 = [(n/2)th obs.+ ((n/2) + 1)th obs.]/2,排序后取中间位置第n/2和n/2+1相邻 2 个元素的平均值;
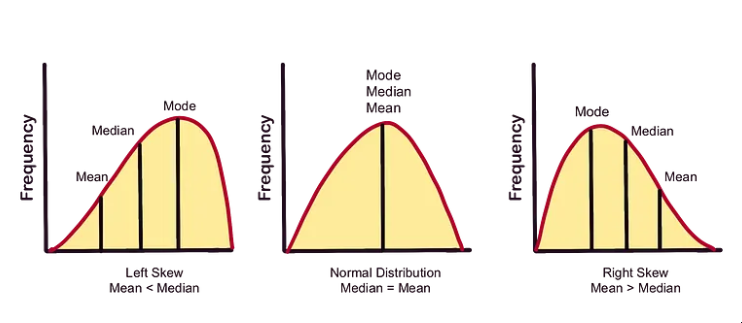
模式:最常出现的观察结果。数据集可以具有一种模式、多种模式或根本没有模式。
警告:与数据集中其他观测值不同的极端异常值(低和/或高)可能会对平均值产生影响。
在这些情况下,中位数可以用来更精确地反映我们数据收集的中间值。
在这些情况下,我们还可以使用 TRIMMED MEAN,它的计算方式与中位数非常相似。
在数据升序后,我们从集合的两端删除相同百分比的数据。但我们必须记住,修整均值对于单个变量(单变量)更好。
让我们看一个简单的例子,用两个极值找到员工的平均工资和中位数工资,看看会发生什么。
Staff 1 2 3 4 5 6 7 8 9 10
Salary 14$ 18$ 16$ 14$ 15$ 15$ 12$ 17$ 90$ 95$
Mean: 306/10 = 30.6 $
Median:(5ᵗʰ+6ᵗʰ)/2 (Ascd order -> 12,14,14,15,15,16,17,18,90,95)
31/2 = 15.2 $
Mode: 14, 15
这些工作人员的平均工资为30.6美元,而中位数为15.2美元。
然而,在仔细检查原始数据后,鉴于多数雇员的收入在 12 美元到 18 美元之间,平均数字可能无法准确反映雇员的典型工资。
因此,两项巨额收入正在扭曲均值。在这种情况下,取出中位数将作为集中趋势的更好指标。
均值、中位数和众数之间的关系
以下关系在三者之间,平均值、中位数和模式之间建立了密切的联系,称为经验关系:
2×平均数 + 众数 = 3×中位数
单变量与双变量
描述性统计中的单变量数据只是调查一个变量。它不评估任何关系或原因;相反,它用于确定构成单个特征的特征。

另一方面,双变量数据通过寻找相关性来努力将两个变量联系在一起。在获取两种形式的数据后,将研究它们之间的关系
。此方法也可以称为多变量,因为检查了多个变量。
本文由 mdnice 多平台发布


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









