







面向对象(12题)
面向对象的基本概念
Java是解释型语言,可以生成中间代码,后边再解释为目标代码执行,也就是即时编译,可以根据机器优化代码,采用的是多态优化编译。
Java程序最初都是通过解释器,进行解释执行的。虚拟机发现运行频繁的代码,会把这些代码定义为热点代码,为了提高热点代码的执行效率,在运行时会把他们编译成本地机器码,进行优化,这个就叫即时编译。

状态图
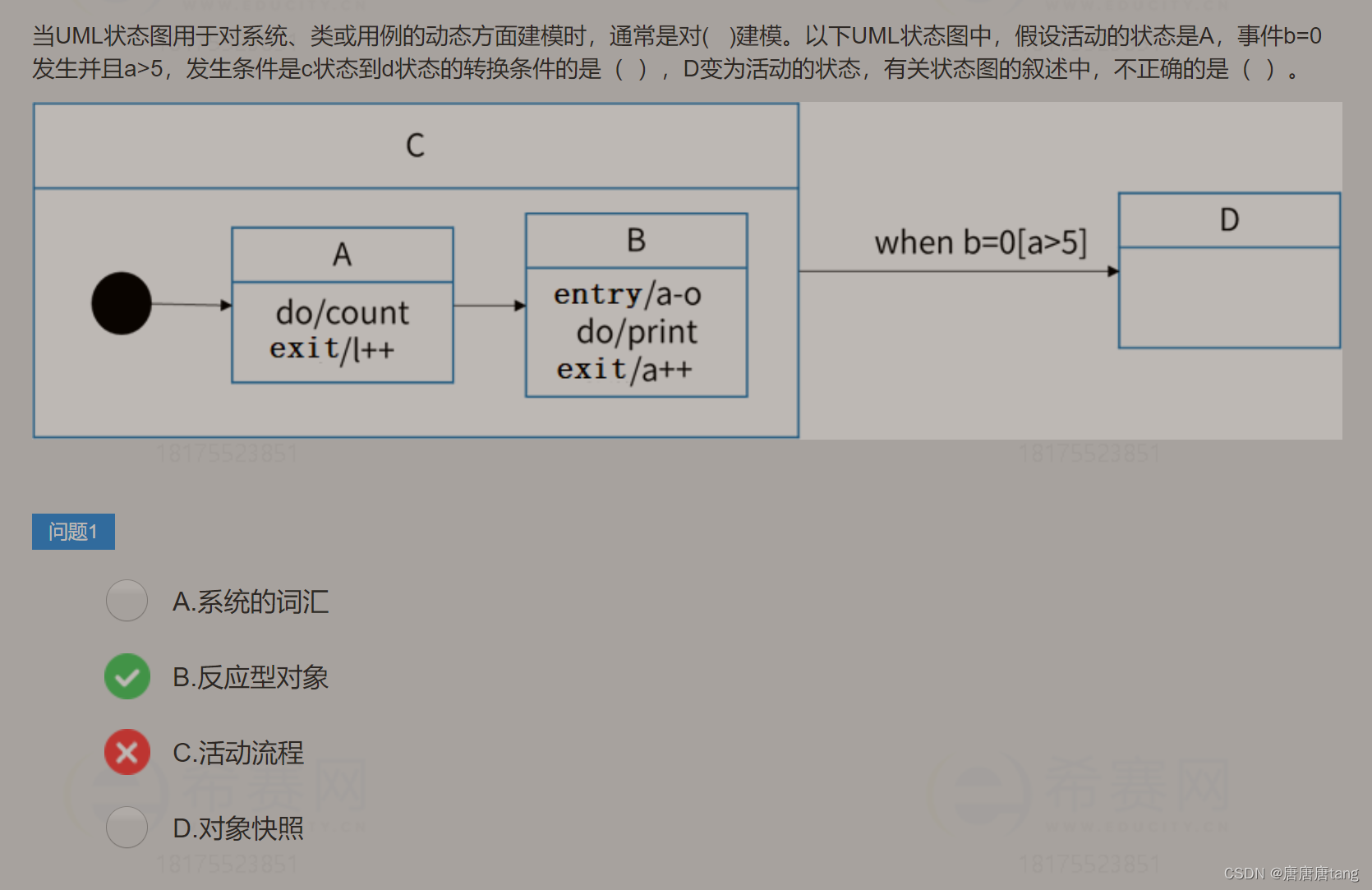
关注系统的动态视图,强调对象行为的事件顺序。可以用状态图对系统的动态方面建模,通常是对反应型对象建模。
状态是对象执行了一系列活动的结果,当某个事件发生后,对象的状态将发生变化。
转换是两个状态间的一种关系,表示对象将在源状态中执行一定的动作,并在某个特定事件发生二某个特定的监护条件满足时进入目标状态。
动作是一个可执行的原子操作,是不可中断的。


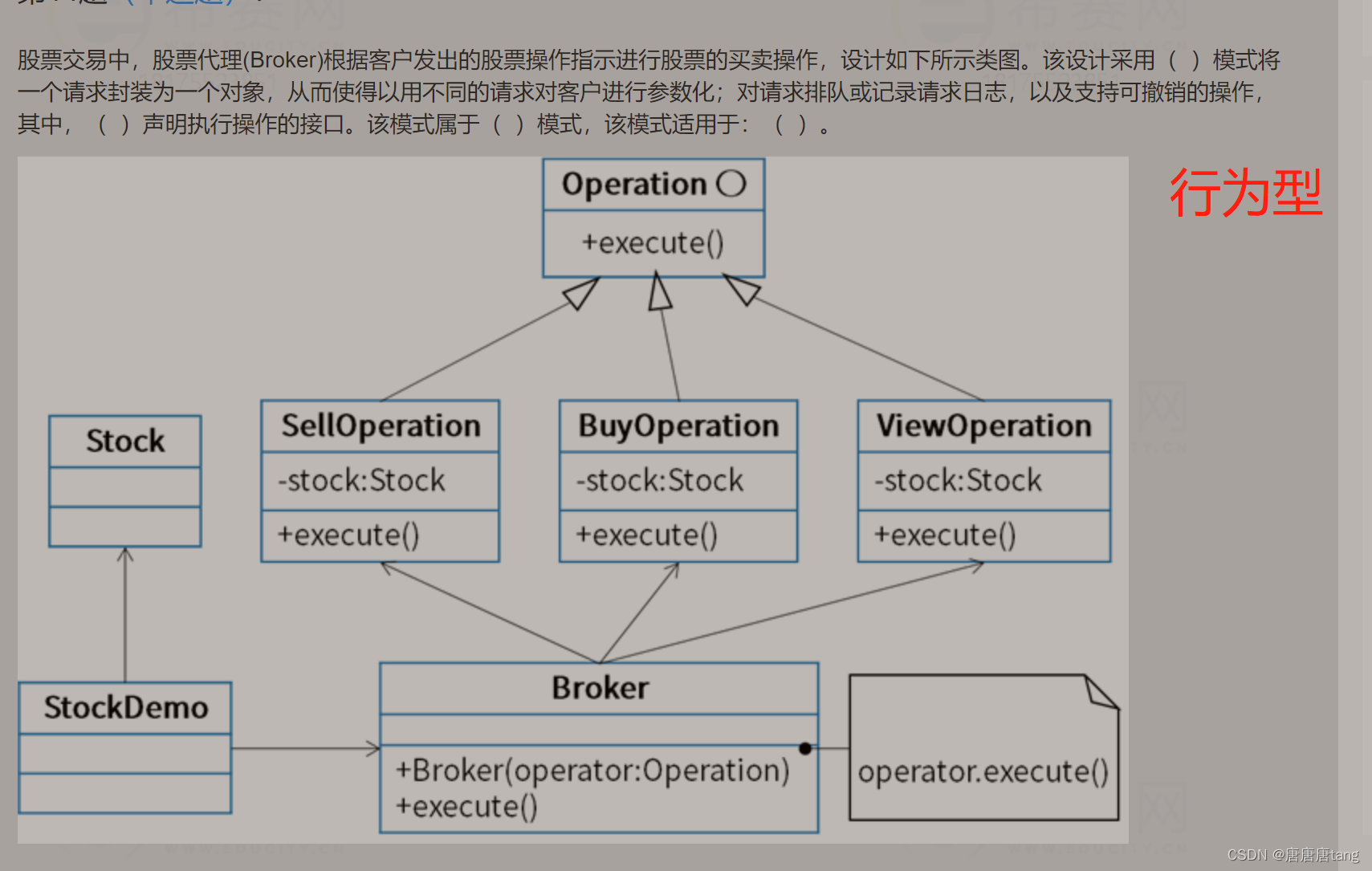
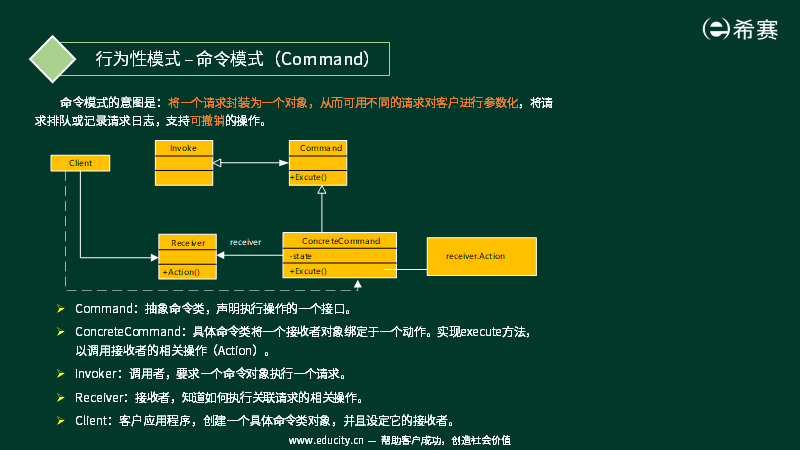
命令模式
软件工程(11题)
结构化设计
作用范围应该在其控制范围之内(作用域在其模块之内)

内聚与耦合

软件工程的六个阶段
一、项目计划阶段
二、项目需求分析阶段
编写成软件需求设计书
三、项目设计阶段
概要设计:( 1 )软件系统总体结构设计,将系纷刻分成模块;确定每个模块的功能;确定模块之间的调用关系;确定模块之间的接口,即模块之间传递的信息;评价模块结构的质量. ( 2 )数据结构及数据库设计
详细设计:对模块内的数据结构进行没计;对数据库进行物理设计;对每个模块进行详细的算法设计;代码设计、输入输出设计、用户界面设计等其他设计。
四、编码阶段
五、软件测试阶段
六、 维护阶段
编写软件的维护报告
可靠性: 系统对于给定时间间隔内、在给定条件下无失效运作的概率,MTTF/(1+MTTF),MTTF(平均无故障时间)
可用性: 给定时间点上,一个系统,能够按照规格说明正确运行的概率。MTBF/(1+MTBF),MTBF(平均失效间隔时间)
可维护性: 给定条件下,在规定时间间隔内,使用规定的过程和资源完成维护活动的概率。1/(1+MTTR),MTTR(平均修复时间)

算法

数据库:
1NF,每个属性都不可再分
2NF,每一个非主属性都完全依赖于码
3NF,消除了非主属性对码的传递函数依赖
函数依赖可以分为
部分函数依赖:
完全函数依赖:在一个关系中,若某个非主属性数据项依赖于全部关键字
冗余函数依赖:比如我依赖于鸡蛋仔,还依赖于鱿鱼串,就是冗余函数依赖。
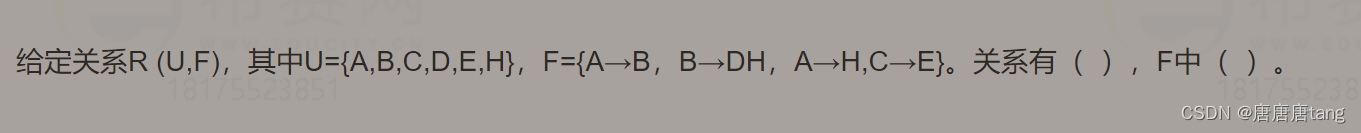

SQL动词及语法
数据定义:Create、Drop、Alter
数据控制:Grant、Revork
数据库授权
grant <权限>,<权限> [on <对象类型><对象名>] to <用户>,<用户>
属性列和视图有四种权限:增删改查(all privileges四种权限的总和),表还增加了两种权限:alter、index(all privileges六种权限的总和)
with grant option:获得了权限的用户还可以把权限赋给其他用户
grant insert on gendb.s1 to tang@;
grant all privileges on gendb.s1 to tang@ with grant option;
revoke insert on gendb.s1 from tang@;建表语句
create table s1(--创建表s1
sno char(5) not null unique,--编号
sname char(30) unique,--名字
primary key(sno,sname),--复合主键,如果要创建单一主键就只写sno
foreign key(sno) references s(sno)--外键,前面的‘sno ’是此表字段,后面的‘sno’是它表字段
);
修改表语句
alter table s1 add sex int;
alter table s1 drop sex;
alter table s1 modify sex int(22);
删除表 :drop table s1
索引的建立与删除
create unique index ssex on s1(sex);
create unique index fuhe on s1(sno,sname,sex);
drop INDEX ssex on s1;
视图的创建与删除
create view n as
select sname,sex from s1
where sex=1
with check option;
select * from n;
drop view n;修改数据
insert into s1 values (2,'张三',1);
delete from s1 where sno=1;
update s1 set sno='李四' where sno=2;数据库设计过程
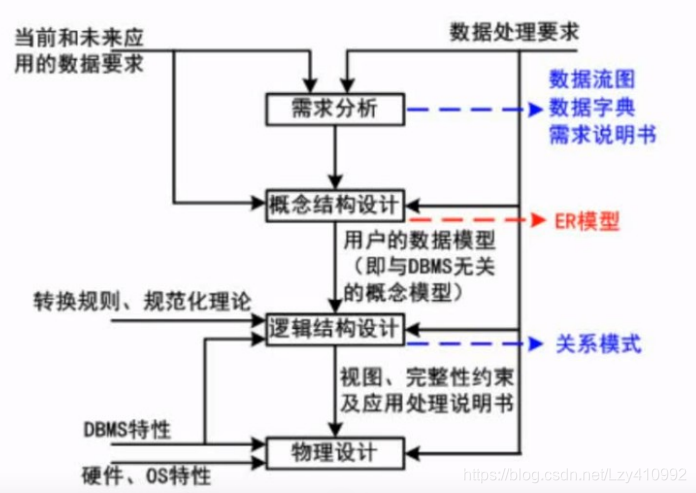
分布式数据库特点
物理分布性:数据不是存储再一个场地上,而是存储再计算机网络的多个场地上。
逻辑整体性:数据物理分布在各个场地,但逻辑上是一个整体,它被所有用户共享,并由一个DDBMS统一管理。
场地自治性:各场地上的数据有本地DBMS管理,具有自治处理能力,完成本场地的应用。
场地之间协作性:各场地之间虽然有高度的自治性,但是相互协作构成一个整体。
分片透明: 用户或应用程序不需要知道逻辑上访问的表具体是怎么分块存储的。
复制透明: 采用复制技术的分布方法,用户不需要知道数据是复制到那些节点,如何复制的。
位置透明: 用户无需知道数据存储的物理位置。
逻辑透明: 局部数据模型透明,用户或应用程序无需知道局部场地使用的是那种数据模型。
价值与用途
非规范化的关系模式,可能存在的问题包括:数据冗余、更新异常、插入异常、删除异常
超键、候选键、主键、外键
超键:
学生表中含有学号或者身份证号的任意组合都为此表的超键。如:(学号)、(学号,姓名)、(身份证号,性别)等。
候选键:
候选键属于超键,它是最小的超键,就是说如果再去掉候选键中的任何一个属性它就不再是超键了。学生表中的候选键为:(学号)、(身份证号)。
主键:
主键就是候选键里面的一个,是人为规定的,例如学生表中,我们通常会让“学号”做主键,教师表中让“教师编号”做主键。
外键:
外键比较简单,学生表中的外键就是“教师编号”。外键主要是用来描述两个表的关系。
并发控制
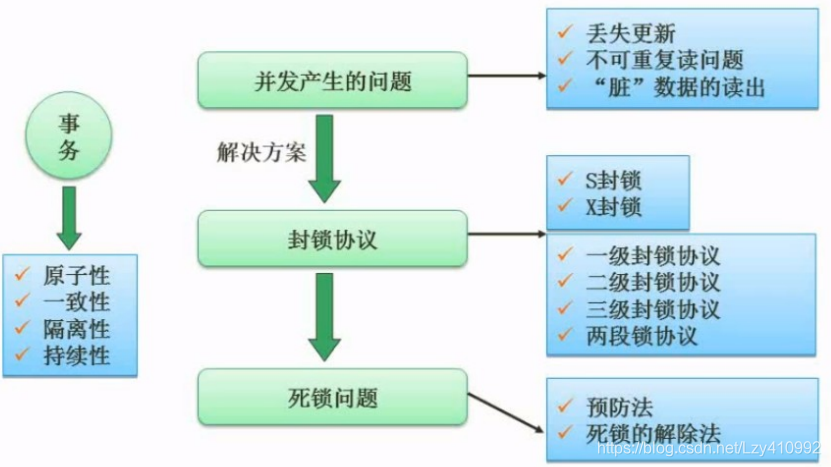
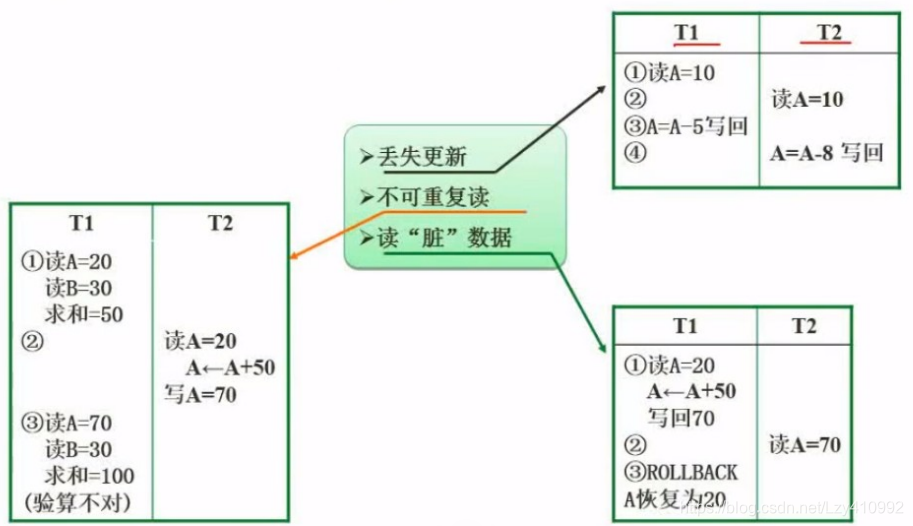

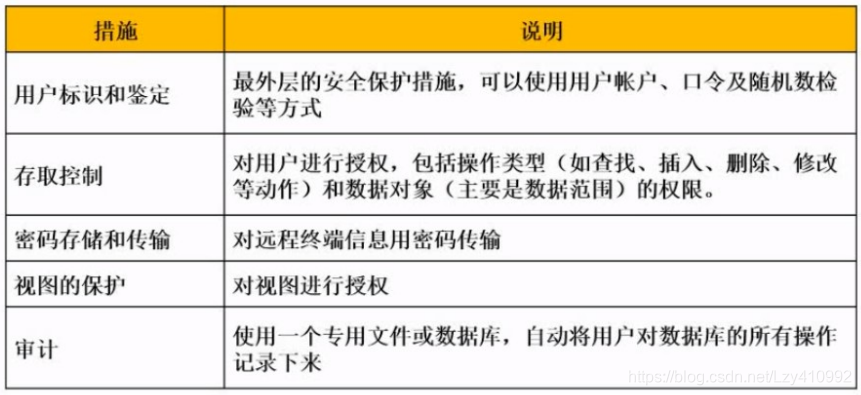
数据库安全
为了保证数据安全可靠、正确有效,数据库管理系统 提供 数据库恢复、并发控制、数据完整性保护、数据安全性保护
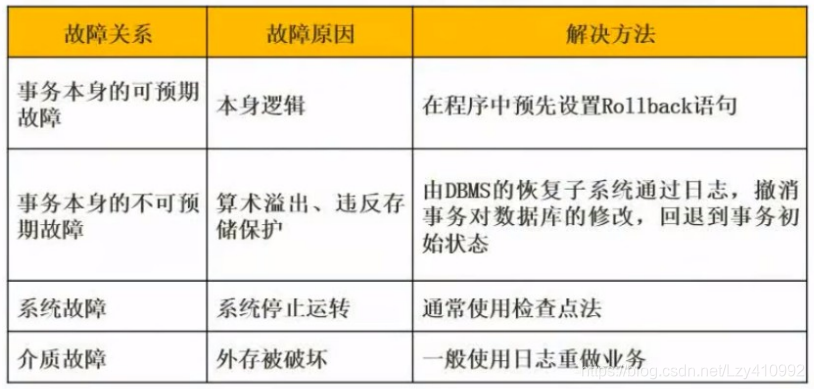
数据存储与恢复
定期将数据进行备份;
在进行事务处理时,将数据更新的相关内容写入日志文件,当系统正常运行时,按一定时间间隔设定检查点文件,把内存缓冲区内容还未写入到磁盘中的数据记录到检查点文件中
当发生故障时,根据现场 数据内容、日志文件的故障前映像、检查点文件 来恢复系统的状态
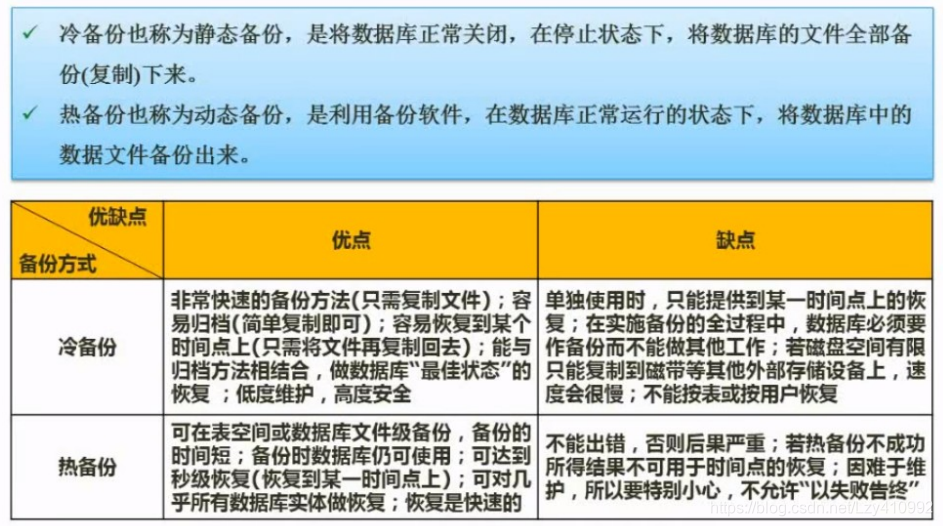
数据备份

大数据
基本概念:数据量、速度、多样性、值
区分于传统数据:数据量PG、深度分析需求(关连分析、回归分析)、集群硬件平台
特点:高度可扩展性、高性能、高度容错、支持异构环境、较短的分析延迟、易用且开放的接口、较低成本、向下兼容性
数据挖掘方法:决策树、神经网络、遗传算法、关联规则挖掘算法
数据挖掘分类
关联分析:挖掘出隐藏在数据间的相互关系
序列模式分析:分析数据间的前后关系(因果关系)
分类分析:为每一个记录赋予一个标记再按标记分类
聚类分析:分类分析法的逆过程
















 1273
1273











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









