




0.简介
在软件开发领域,哈希表作为一种重要的数据结构,广泛应用于各种场景中,尤其是在后端开发中,高效的查找和插入操作是不可或缺的。近年来,SwissTable作为一种改进的哈希表实现,因其出色的性能和可扩展性而备受关注。本文将深入探讨SwissTable的工作原理、特点及其在实际应用中的优势。
1.基础概念说明
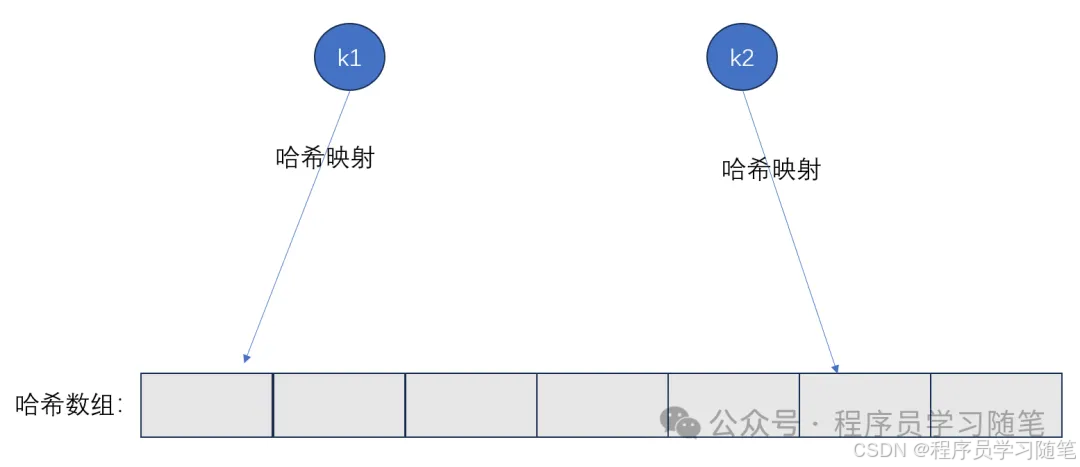
要了解新式的哈希表SwissTable首先要对普通哈希表有所了解,传统哈希表一般由哈希表数组和哈希函数组成,由哈希函数计算存储位置。其空间复杂度为O(n),查找,删除,插入的平均时间复杂度为O(1)。
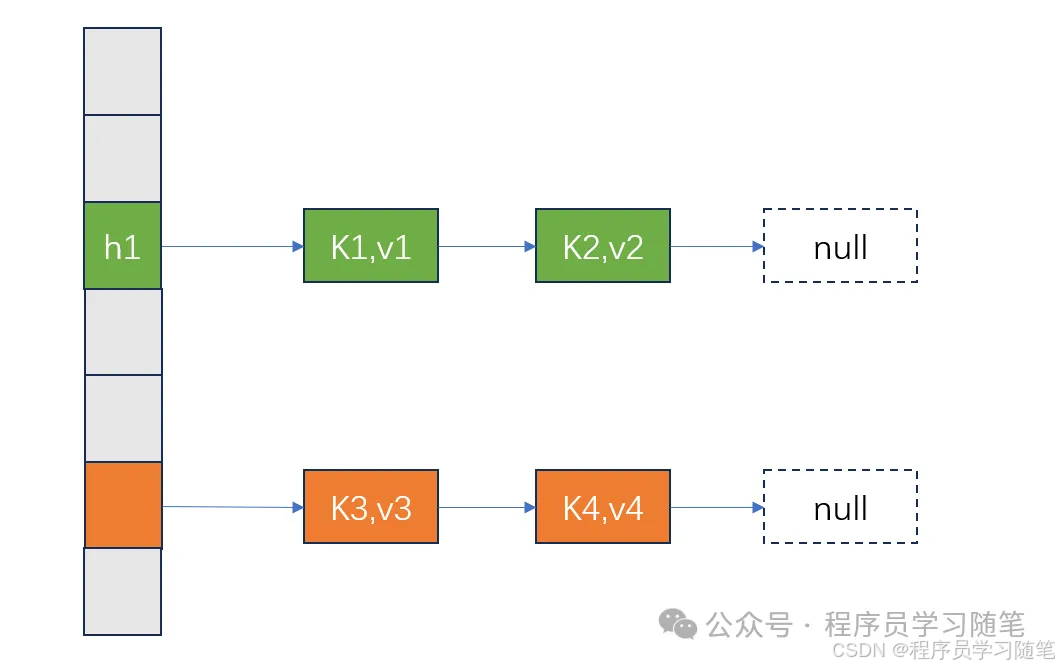
但是即使是产生的hash值足够随机,依然不能避免冲突,为了解决这种冲突,常见的处理方式有拉链法(通过链表方式来解决冲突),其优点是实现简单,插入删除操作简单;缺点在于链表本身对应缓存并不友好,局部性较差。
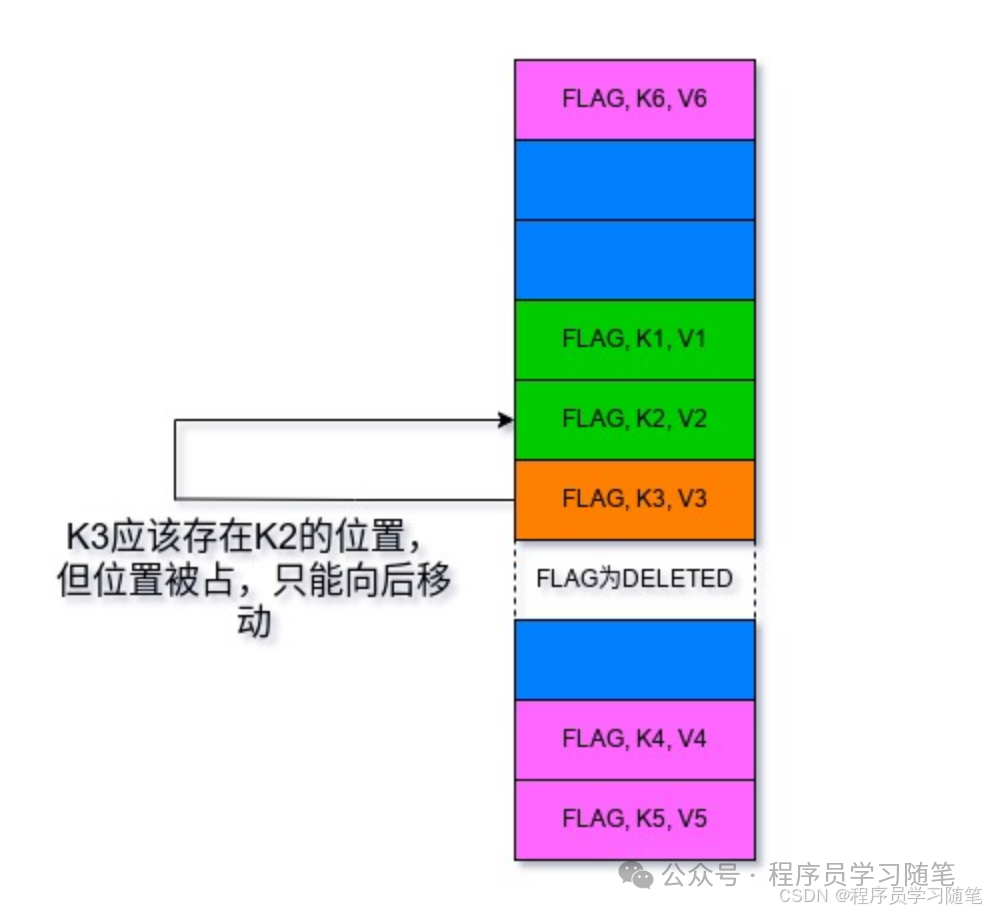
另外一种常见的处理哈希冲突的方式是通过线性探测法,其再遇到冲突时,会从冲突位置向后查找直到找到一个空位,如果没找到则会扩容。其优点在于对缓存友好,哈希数组利用率高;缺点在于实现比较复杂,且一处冲突可能影响多个key。
上面两种方式都有着较为明显的缺陷,于是一个在性能,缓存友好和内存使用量上尽可能平衡的结构,SwissTable产生了。
2.SwissTable结构和原理
SwissTable和普通的线性探测法的区别在于多了一个用于标识slot状态的控制结构。可以看到,其控制bytes是8位,第一位是状态位,结合后续是不是都是0判断信息,而算出的hash值分成了两段,第一段是用来进行slot确定的值,第二段是七位,用来放入control byte的后七位,这样就可以进行位运算进行初步定位。

其查找过程可以分为两步,第一步先根据算出的slot的位置找到初始的位置(因为其本质还是通过线性检测的方法去实现的,所以第一个位置一定是开始的位置)。第二步就是从算出的位置开始进行group的比较,如果相等说明可能是对应的值,进行比较然后直到找到对应key或到达最后位置。在第二步时其一般使用smid指令进行优化,一次可以比较16个control byte(因为smid操作128位,而一个byte是8位,这样一次就可以比较16个位置,如果不支持可以使用位运算来进行计算),通过比较可以将这16个位置比较输出为32位的int,其内为1的位即为符合的位置,进行下一步比较。
对于写入来说,也是通过控制信息探测位置是否存在空位,按照group进行操作,提升操作效率。
下面对其相比于线性探测的优化进行一个简单的总结,分析设计中可以借鉴的点:
1)通过元数据信息来进行初步过来而不是每次都挨个比较数据,对于cpu缓存更为友好。也就是通过更小的控制信息来代替数据比较。
2)通过simd来进行批量比较,减少比较次数,增大cpu缓存命中率。也就是增大扇入扇出,批量处理。



















 975
975

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











