







1.错误1:
py4j.protocol.Py4JError: org.apache.spark.api.python.PythonUtils.getEncryptionEnabled does not exist in the JVM
需要在模型前加上两行
import findspark
findspark.init()
然后创建:
sc = SparkContext("spark://192.168.192.130:7077", "recommend")
应该没错了:
训练模型:


错误2:
(null) entry in command string: null ls -F D:\PC\PyCharm 2018.3.3\untitled2\recommend\recommendModel\metadata\part-0000
hadoop 的 input Path 设为文件夹路径时,需要读取文件夹路径下所有文件报如下错误:
报错提示的意思是说,Path这个路径需要是一个具体的文件,而不能是文件夹。
删掉
2.python使用文件
详细链接:https://blog.csdn.net/xrinosvip/article/details/82019844
open()
close()
with open(…) as …(可自动使用close)
open(file,'r') #读文件
open(file,'w') #写文件
open(file,'a') #追加文件。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。
open(file,'b') #读二进制数据,例如图片
3.点击次数
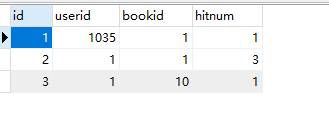
终于出来了!!!!
a.路径出错

b.Illegal mix of collations (latin1_swedish_ci,IMPLICIT) and (utf8_general

数据库对应类型应该一致

待改进…

























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









