







 超级会员免费看
超级会员免费看
提前声明:该专栏涉及的所有案例均为学习使用,如有侵权,请联系本人删帖!
一、环境配置
- 环境:python3.6
- 开发工具:pycharm
- 模块:requests
二、请求头中的cookie
我们使用Python的requests模块请求网站的一个接口时,通常需要携带headers模拟浏览器的正常请求。其中cookie是网站登录或者不登录下发的一个用户凭证。
但是对于一些网站,我们如果不登录,那么我们就无法请求进入网站内部的一些接口或页面,因此就需要登录,登录后下发的cookie就可以请求我们网站内部信息了。那么登录又分为两类情况:
- 对于临时抓取或者登录后可以保持很长时间的情况,不需要模拟登录,直接copy那个cookie值
- 需要程序模拟登陆的流程,然后自动获取cookie
在这里我们不进行模拟登陆,我们只简单使用一下cookie和session,先简单介绍一下cookie和session
1.cookie和session的区别
- cookie在客户的浏览器上,session存在服务器上
- cookie是不安全的,且有失效时间
- session是在cookie的基础上,服务端设置session时会向浏览器发送设置一个设置cookie的请求,这个cookie包括session的id当访问服务端时带上这个session_id就可以获取到用户保存在服务端对应的session
2.爬虫处理cookie和session
- 带上cookie和session的好处:能够请求到登录后的界面
- 带上cookie和session的弊端:一个cookie和session往往和一个用户对应,访问太快容易被服务器检测出来爬虫
- 不需要cookie的时候尽量不要用
三、cookie请求页面
网站:https://codechina.csdn.net/explore/welcome
进入网址后登录

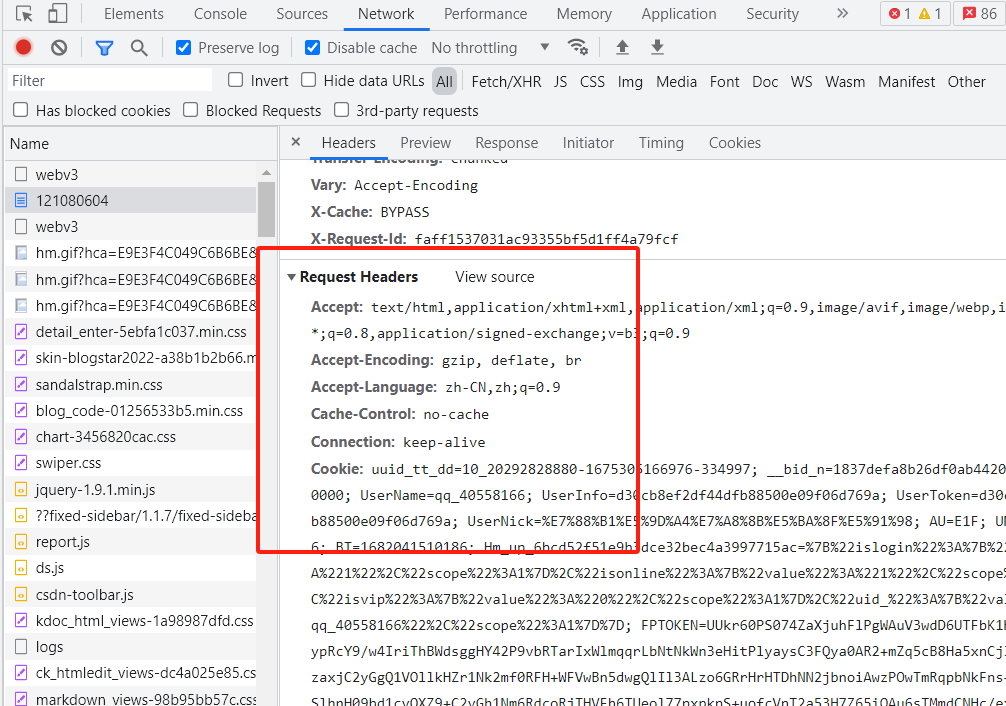
因此我们需要手动登录后,然后看到已经有了cookie


因此我们直接在请求的时候携带自己的cookie,如果我们登陆后,可以看到自己的用户名

那么看一下代码
# -*- coding: utf-8 -*-
import requests
url = 'https://codechina.csdn.net/explore/welcome'
headers = {
'Cookie': '...',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36'
}
# 请求,verify=False 跳过ssl验证
response = requests.get(url, headers=headers, verify=False)
response.encoding = 'utf-8'
if '不愿透露姓名の网友' in response.text:
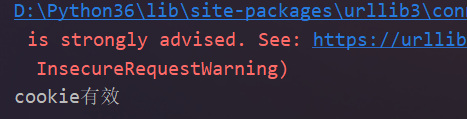
print('cookie有效')
else:
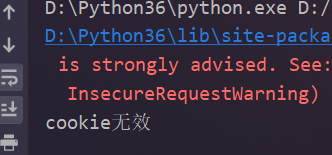
print('cookie无效')

成功!
四、session请求页面
使用session的话,就是使用requests的session方式,他会记录请求携带的cookie状态
session = requests.Session()
url = 'https://codechina.csdn.net/explore/welcome'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36'
}
response = session.get(url, headers=headers, verify=False)
response.encoding = 'utf-8'
if '不愿透露姓名の网友' in response.text:
print('cookie有效')
else:
print('cookie无效')
然后我们塞入cookie,session中的cookie不能传入字符串,需要按键值对传入
session.cookie[key]=value
将字符串变成字段的方法
def cookie_to_dic(cookie_str):
"""将cookie字符串转为cookie字典"""
dic = {}
for i in cookie_str.split('; '):
dic[i.split('=')[0]] = i.split('=')[1]
return dic
放入一个登录的cookie

然后再使用该session访问其他的页面,可以直接访问成功

简单写下代码
# -*- coding: utf-8 -*-
import requests
def cookie_to_dic(cookie_str):
"""将cookie字符串转为cookie字典"""
dic = {}
for i in cookie_str.split('; '):
dic[i.split('=')[0]] = i.split('=')[1]
return dic
# 不放入cookie
session = requests.Session()
url = 'https://codechina.csdn.net/explore/welcome'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36'
}
response = session.get(url, headers=headers, verify=False)
response.encoding = 'utf-8'
if '不愿透露姓名の网友' in response.text:
print('cookie有效')
else:
print('cookie无效')
# 放入cookie
cookie_str = '...'
cookie_dict = cookie_to_dic(cookie_str)
for key, value in cookie_dict.items():
session.cookies[key] = value
response = session.get(url, headers=headers, verify=False)
response.encoding = 'utf-8'
if '不愿透露姓名の网友' in response.text:
print('cookie有效')
else:
print('cookie无效')
# 访问新页面
url_2 = 'https://codechina.csdn.net/courses'
response_2 = session.get(url)
response_2.encoding = 'utf-8'
if '不愿透露姓名の网友' in response_2.text:
print('cookie有效')
else:
print('cookie无效')

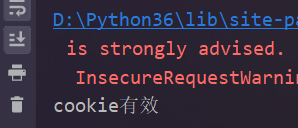
成功















 1459
1459











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











