






K邻近算法的伪代码
机器学习实战 李锐等译
对未知类别属性的数据集的每一个点依次进行如下操作:
1.计算已知类别数据集中的点与当前点之间的距离;
2.按照距离递增次序排序
3.选取与当前点距离最小的k个点;
4.确定前k个点所在类别的出现频率;
5.返回前k个点出现频率最高的类别作为当前点的预测分类
python源码:
import numpy as np
import math
def classify0(inX,dataSet,labels,k):
"""
inX:初始值,用于分类的输入向量;
dataSet :训练数据集,
labels:标签向量
k:表示用于选择最近邻居的数目
"""
dataSetSize=dataSet.shape[0]
diffMat=np.tile(inX,(dataSetSize,1))-dataSet #np.tile先将初始向量扩展成和dataSet形状相同的矩阵
sqDiffMat=diffMat**2
sqDistances=sqDiffMat.sum(axis=1)
distances=sqDistances**0.5
sortedDistIndicies=distances.argsort()#从小到大排序
classCount={}
for i in range(k):
votelLabel=labels[sortedDistIndicies[i]] #确定前k个距离最小的元素
classCount[votelLabel]=classCount.get(votelLabel,0)+1#最小元素的类,键值对应的为频率
sortedClassCount=sorted(classCount.items(),key=lambda x:x[1],reverse=True)#从大到小排序
return sortedClassCount[0][0]
注:
#np.argsort()理解
rawArray=np.array([1.48,1.41,0,0.1])
#rawArray_Index: 0 1 2 3
#sortedRawArray=array([0,0.1,1.41,1.48])
sortedRawArray_index: 2 3 1 0
统计学习方法 李航著
K近邻模型的三个基本要素:距离度量、k值的选择、和分类规则决定。
- 距离度量。
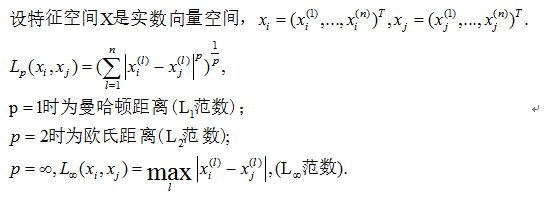
-
k值选择。
K值较小:相当于用较小的邻域中的训练实例进行预测,学习的近似误差会减小,但缺点是学习的估计误差会增大,预测结果会对近邻的实例点非常敏感。如果近邻点恰巧是噪声,预测就会出错。即k的减小会让模型变得复杂,容易发生过拟合。
K值较大:相当于用较大邻域中的实例进行预测,其优点是较少学习的估计误差。但是缺点是学习的近似误差会增大。
K值的选择,一般选取比较小的值,通常采用交叉验证法来选择最优的k值。 -
分类规则。
多数表决规则:由输入实例中的k个邻近的训练实例中的多数类决定输入实例的类。如:分类函数是0-1损失函数,要使误分率最小即经验风险最小。多数表决规则等价于经验风险最小。

k近邻法最简单的实现方法是线性扫描,当训练集很大时,计算比较耗时,这种方法不可行。
k邻近的实现——kd树
Kd树是一种对k维空间中的实例点记性存储以便其进行快速检索的树形数据结构。
Kd树是二叉树,表示对k维空间的一个划分,构造kd树相当于不断地用垂直于坐标轴的平面将k维空间划分,构成一系列的k维超矩形区域。Kd树的每一个结点对应于k维超矩形区域。
算法:
算法:构造平衡的kd树
输入:k维空间数据集 ,其中 ;
输出:Kd树
(1).开始:构造根结点,根结点对应于包含T的k维空间的超矩形区域。
选择x(l) 为坐标轴,以T中的所有实例的 x(l)坐标的中位数为切分点,将根结点对应的超矩形区域切分为两个子区域。切分由通过切分点并与坐标轴 垂直的超平面实现。
由根结点生成深度为1的左、右子结点:左子结点对应坐标x(l) 小于切分点的子区域,右子结点对应于x(l) 大于切分点的子区域。
(2)重复:对深度为j的结点,选择x(l) 为切分的坐标轴, l=j(mod k)+1以该结点的区域中所有实例的 坐标的中位数为切分点,将该结点对应的超矩形区域分为两个子区域,切分由通过切分点并与坐标轴 垂直的超平面实现。
由根结点生成深度为(j+1)的左、右子结点:左子结点对应坐标 小于切分点的子区域,右子结点对应于 大于切分点的子区域。
(3).直到两个子区域再没有实例点存在时停止,从而形成kd树的区域划分。
关于kd树的相关问题梳理:
-
子空间划分维度的选择:
根据l=j(mod k)+1或者最大方差法(使用较多);
第一种方法的解释 -
kd树中常用案例(统计学习方法 p42 例3.2)中位数为7。
中位数为7的解释
案例的每一步具体解释
kmeans与k近邻算法的区别和联系。
kmeans是无监督的聚类算法;k近邻是有监督的分类和回归算法。
















 1842
1842

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









