










代码实现:GitHub:team79\Tree\KDTree
kd树是用来为求k临近而创建的数据结构,查询的平均复杂度是logN(和二叉树很像)
kd树的创建


这里在创建kd树的时候,这里的算法是循环依次采取各个维度来构建二叉树,也有做法是选取数据在该维度上方差最大的那一维,因为方差大代表数据较分散,会有更好的分辨率。
插入节点
insert(Point x, KDNode t, int cd) {
if t == null
t = new KDNode(x)
else if (x == t.data)
// error! duplicate
else if (x[cd] < t.data[cd])
t.left = insert(x, t.left, (cd+1) % DIM)
else
t.right = insert(x, t.right, (cd+1) % DIM)
return t
}FindMin in kd-trees(寻找第k维最小的节点)
FindMin(d): find the point with the smallest value in the dth dimension.
伪代码:
Point findmin(Node T,int dim,int cd):
// empty tree
if T == NULL:return NULL
// T splits on the dimension we’re searching
// => only visit left subtree
if cd == dim:
if t.left == NULL: return t.data
else return findmin(T.left, dim, (cd+1)%DIM)
// T splits on a different dimension
// => have to search both subtrees
else:
return minimum(
findmin(T.left, dim, (cd+1)%DIM),
findmin(T.right, dim, (cd+1)%DIM)
T.data
)删除节点
当有右节点的时候:

当没有右节点有左节点的时候:
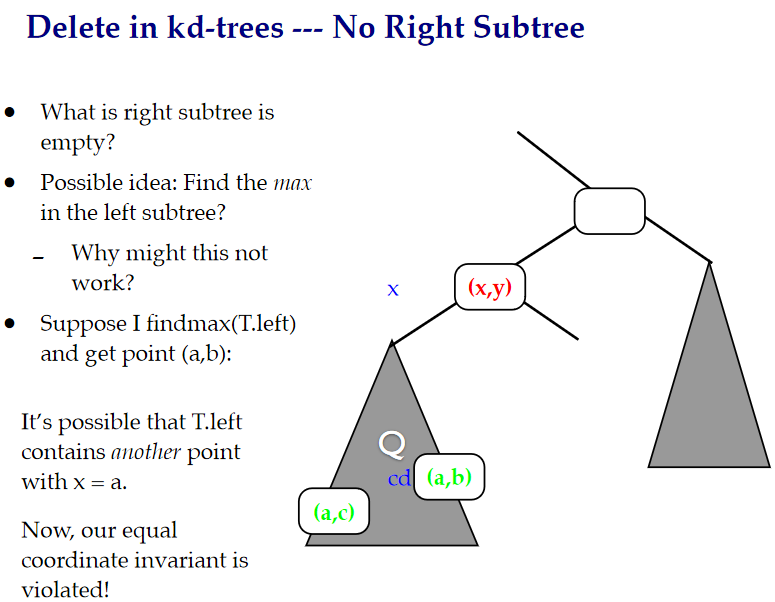
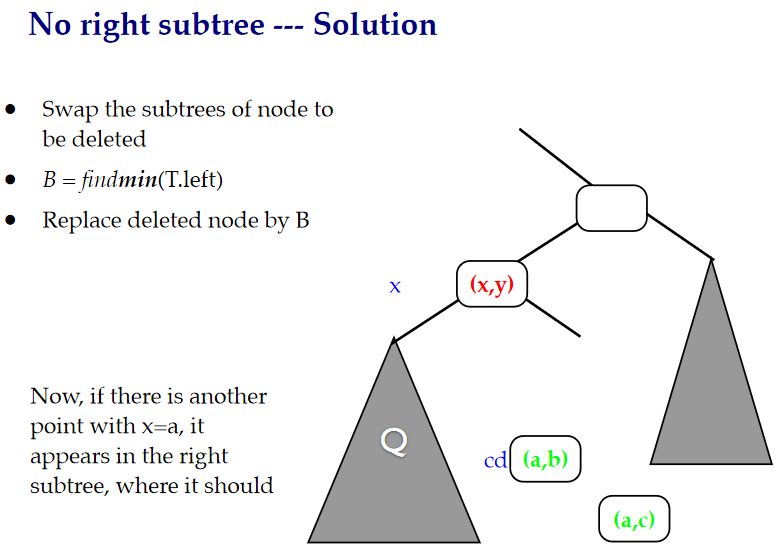
在这里,找到最小的一个节点来替代删除的节点,并将左节点变为右节点
当没有字节的时候直接设置为NULL返回
伪代码:
Point delete(Point x, Node T, int cd):
if T == NULL: error point not found!
next_cd = (cd+1)%DIM
// This is the point to delete:
if x = T.data:
// use min(cd) from right subtree:
if t.right != NULL:
t.data = findmin(T.right, cd, next_cd)
t.right = delete(t.data, t.right, next_cd)
// swap subtrees and use min(cd) from new right:
else if T.left != NULL:
t.data = findmin(T.left, cd, next_cd)
t.right = delete(t.data, t.left, next_cd)
t.left = null
else
t = null // we’re a leaf: just remove
// this is not the point, so search for it:
else if x[cd] < t.data[cd]:
t.left = delete(x, t.left, next_cd)
else
t.right = delete(x, t.right, next_cd)
return t查询最近邻节点
k-d树最邻近搜索的过程如下:
- 从根节点开始,递归的往下移。往左还是往右的决定方法与插入元素的方法一样(如果输入点在分区面的左边则进入左子节点,在右边则进入右子节点)。
- 一旦移动到叶节点,将该节点当作”目前最佳点”。
- 解开递归,并对每个经过的节点运行下列步骤:
- 如果目前所在点比目前最佳点更靠近输入点,则将其变为目前最佳点。
- 检查另一边子树有没有更近的点,如果有则从该节点往下找
- 当根节点搜索完毕后完成最邻近搜索

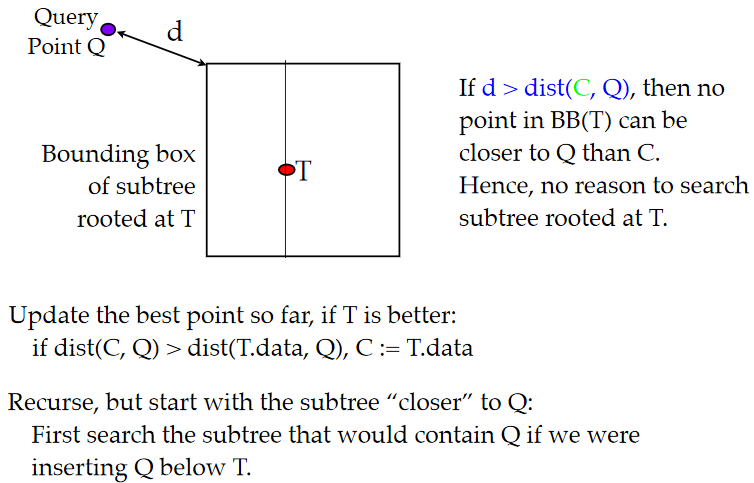
其实对kd树的搜索是一个剪枝问题,本来我们是要遍历树上所有的点的,但是当当前区域不可能有点比之前搜到的最小距离小的时候直接就剪枝不搜了。
怎么求这个最小距离呢:
设max[i]为当前一些点第i维的最大值,min[i]为当前一些点第i维的最小值,point表示当前要找的点
double getdist():
dist = 0
for i = 0 to dim:
if point[i] < min[i]:
dist += (point[i] - min[i]) * (point[i] - min[i])
else if point[i] > max[i]:
dist += (point[i] - max[i]) * (point[i] - max[i])
return dist伪代码:
def NN(Point Q, kdTree T, int cd, Rect BB):
// if this bounding box is too far, do nothing
if T == NULL or distance(Q, BB) > best_dist: return
// if this point is better than the best:
dist = distance(Q, T.data)
if dist < best_dist:
best = T.data
best_dist = dist
// visit subtrees is most promising order:
if Q[cd] < T.data[cd]:
NN(Q, T.left, next_cd, BB.trimLeft(cd, t.data))
NN(Q, T.right, next_cd, BB.trimRight(cd, t.data))
else:
NN(Q, T.right, next_cd, BB.trimRight(cd, t.data))
NN(Q, T.left, next_cd, BB.trimLeft(cd, t.data))查询K近邻节点
这个查询最近的k个节点的算法是我自己想的,还有实验验证
在上面找最近邻节点的时候判断条件是当前搜索区域不可能有节点比之前搜到的近的时候就剪枝:
if T == NULL or distance(Q, BB) > best_dist: return那么我们在找最近的k个节点的时候做一下改变,首先用一个最大堆来保存已经找到的k个节点,当当前区域不可能有节点比堆上最大的距离小的时候就剪枝:
我们用queue来表示这个堆
if T == NULL or distance(Q, BB) > queue.MAX: return //queue.MAX表示堆上的最大值那么最后的伪代码是:
def NN(Point Q, kdTree T, int cd, Rect BB):
// if this bounding box is too far, do nothing
if T == NULL or distance(Q, BB) > queue.MAX: return //queue.MAX表示堆上的最大值
// if this point is better than the best:
dist = distance(Q, T.data)
if dist < queue.MAX:
queue.updata(dist,T.data);//用这个新找到的比较小的距离dist来更新这个最大堆
// visit subtrees is most promising order:
if Q[cd] < T.data[cd]:
NN(Q, T.left, next_cd, BB.trimLeft(cd, t.data))
NN(Q, T.right, next_cd, BB.trimRight(cd, t.data))
else:
NN(Q, T.right, next_cd, BB.trimRight(cd, t.data))
NN(Q, T.left, next_cd, BB.trimLeft(cd, t.data))

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









