







1.内嵌对象nested object
1)初始化mapping
PUT /user_index
{
"mappings": {
"properties": {
"login_name": {
"type": "keyword"
},
"age": {
"type": "short"
},
"address": {
"type": "nested",
"properties": {
"province": {
"type": "keyword"
},
"city": {
"type": "keyword"
},
"street": {
"type": "keyword"
}
}
}
}
}
}2)初始化数据
PUT /user_index/_doc/1
{
"login_name": "jack",
"age": 25,
"address": [
{
"province": "北京",
"city": "北京",
"street": "枫林三路"
},
{
"province": "天津",
"city": "天津",
"street": "华夏路"
}
]
}
PUT /user_index/_doc/2
{
"login_name": "rose",
"age": 21,
"address": [
{
"province": "河北",
"city": "廊坊",
"street": "燕郊经济开发区"
},
{
"province": "天津",
"city": "天津",
"street": "华夏路"
}
]
}3)搜索 (需要使用nested对应的搜索语法来执行搜索了),语法如下:
GET /user_index/_search
{
"query": {
"nested": {
"path": "address",
"query": {
"bool": {
"must": [
{
"match": {
"address.province": "天津"
}
}
],
"should": [
{
"match": {
"address.city": "北京"
}
}
]
}
}
}
}
} 2.父子关系数据建模(父子文档)
1)概念
父文档和子文档是两个独立的文档。ES 提供了类似关系型数据库中 Join 的实现。使用 Join 数据类型实现,可以通过 Parent / Child 的关系,从而分离两个对象。
nested object的建模,有个不好的地方,就是采取的是类似冗余数据的方式,将多个数据都放在一起了,维护成本就比较高,每次更新,需要重新索引整个对象(包括根对象和嵌套对象)。而父子文档中更新父文档无需重新索引整个子文档。子文档被新增,更改和删除也不会影响到父文档和其他子文档。
要点:父子关系元数据映射,用于确保查询时候的高性能,但是有一个限制,就是父子数据必须存在于一个shard中,而且还有映射其关联关系的元数据,那么搜索父子关系数据的时候,不用跨分片,一个分片本地自己就搞定了,性能当然高。
2.定义父子文档步骤
-
- 设置索引的 Mapping
- 索引父文档
- 索引子文档
- 按需查询文档
1)设置 Mapping

DELETE my_blogs
# 设定 Parent/Child Mapping
PUT my_blogs
{
"mappings": {
"properties": {
"blog_comments_relation": {
"type": "join",
"relations": {
"blog": "comment"
}
},
"content": {
"type": "text"
},
"title": {
"type": "keyword"
}
}
}
}2)索引父文档
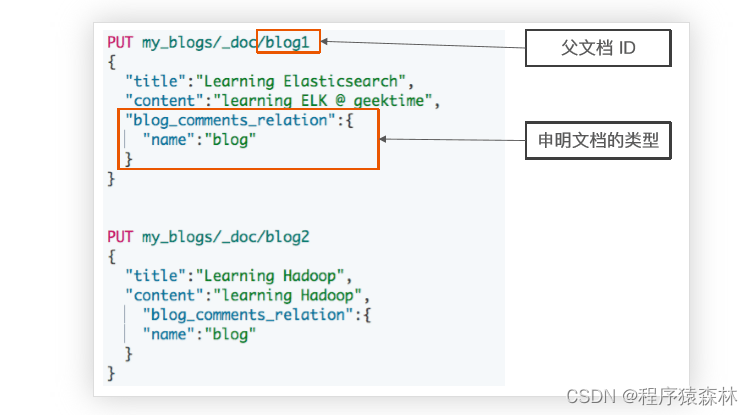
#索引父文档
PUT my_blogs/_doc/blog1
{
"title": "Learning Elasticsearch",
"content": "learning ELK is happy",
"blog_comments_relation": {
"name": "blog"
}
}
PUT my_blogs/_doc/blog2
{
"title": "Learning Hadoop",
"content": "learning Hadoop",
"blog_comments_relation": {
"name": "blog"
}
}3)索引子文档
- 父文档和子文档必须存在相同的分片上
- 确保查询 join 的性能
- 当指定文档时候,必须指定它的父文档 ID
- 使用 route 参数来保证,分配到相同的分片
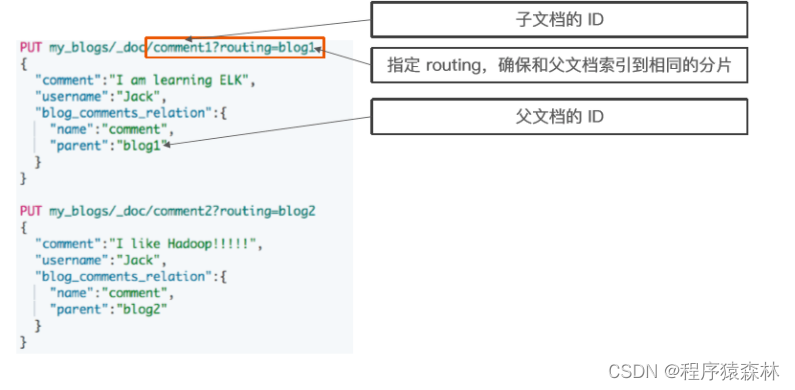
#索引子文档
PUT my_blogs/_doc/comment1?routing=blog1
{
"comment": "I am learning ELK",
"username": "Jack",
"blog_comments_relation": {
"name": "comment",
"parent": "blog1"
}
}
PUT my_blogs/_doc/comment2?routing=blog2
{
"comment": "I like Hadoop!!!!!",
"username": "Jack",
"blog_comments_relation": {
"name": "comment",
"parent": "blog2"
}
}
PUT my_blogs/_doc/comment3?routing=blog2
{
"comment": "Hello Hadoop",
"username": "Bob",
"blog_comments_relation": {
"name": "comment",
"parent": "blog2"
}
}4)Parent / Child 所支持的查询
- Parent Id 查询
- Has Child 查询
- Has Parent 查询
# Parent Id 查询
GET my_blogs/_search
{
"query": {
"parent_id":{
"type":"comment",
"id": "blog2"
}
}
}
# Has Child 查询
GET my_blogs/_search
{
"query": {
"has_child": {
"type": "comment",
"query": {
"match": {
"username": "Jack"
}
}
}
}
}
# Has Parent 查询
GET my_blogs/_search
{
"query": {
"has_parent": {
"parent_type": "blog",
"query": {
"match": {
"title": "Learning Elasticsearch"
}
}
}
}
}5)更新子文档
PUT my_blogs/_doc/comment3?routing=blog2
{
"comment": "Hello Hadoop??",
"blog_comments_relation": {
"name": "comment",
"parent": "blog2"
}
}更新子文档不会影响到父文档
6)嵌套对象 v.s 父子文档对比
Nested Object Parent / Child
优点:文档存储在一起,读取性能高、父子文档可以独立更新
缺点:更新嵌套的子文档时,需要更新整个文档、需要额外的内存去维护关系。读取性能相对差,适用场景子文档偶尔更新,以查询为主、子文档更新频繁。
3.分页查询
1)使用from和size来进行分页
在执行查询时,可以指定from(从第几条数据开始查起)和size(每页返回多少条)数据,就可以轻松完成分页。l from = (page – 1) * size
GET cars/_search
{
"from": 0,
"size": 2,
"query": {
"term": {
"brand": "大众"
}
}
}2)使用scroll方式进行分页
前面使用from和size方式,查询在1W条数据以内都是OK的,但如果数据比较多的时候,会出现性能问题。Elasticsearch做了一个限制,不允许查询的是10000条以后的数据。如果要查询1W条以后的数据,需要使用Elasticsearch中提供的scroll游标来查询。
在进行大量分页时,每次分页都需要将要查询的数据进行重新排序,这样非常浪费性能。使用scroll是将要用的数据一次性排序好,然后分批取出。性能要比from + size好得多。使用scroll查询后,排序后的数据会保持一定的时间,后续的分页查询都从该快照取数据即可。
2.1)第一次使用scroll分页查询
让排序的数据保持1分钟,所以设置scroll为1m
GET cars/_search?scroll=1m
{
"size": 2,
"query": {
"term": {
"brand": {
"value": "大众"
}
}
}
}
# 返回参数
{
"_scroll_id" : "FGluY2x1ZGVfY29udGV4dF91dWlkDXF1ZXJ5QW5kRmV0Y2gBFldmdGQ2Z2g3VDZTaDEzUVh1UGtFMEEAAAAAASy0whZQQTFUeW00clNQS1FQa1VVQkUyM3BR",
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 0.9444616,
"hits" : [
{
"_index" : "cars",
"_type" : "_doc",
"_id" : "f1o-vYMB5Zg4i2dd7WIh",
"_score" : 0.9444616,
"_source" : {
"price" : 258000,
"color" : "金色",
"brand" : "大众",
"model" : "大众迈腾",
"sold_date" : "2021-10-28",
"remark" : "大众中档车"
}
},
{
"_index" : "cars",
"_type" : "_doc",
"_id" : "gFo-vYMB5Zg4i2dd7WIh",
"_score" : 0.9444616,
"_source" : {
"price" : 123000,
"color" : "金色",
"brand" : "大众",
"model" : "大众速腾",
"sold_date" : "2021-11-05",
"remark" : "大众神车"
}
}
]
}
}
执行后,我们注意到,在响应结果中有一项:"_scroll_id" : "FGluY2x1ZGVfY29udGV4dF91dWlkDXF1ZXJ5QW5kRmV0Y2gBFldmdGQ2Z2g3VDZTaDEzUVh1UGtFMEEAAAAAASy0whZQQTFUeW00clNQS1FQa1VVQkUyM3BR" 后续,我们需要根据这个_scroll_id来进行查询
2.2)第二次直接使用scroll id进行查询
GET _search/scroll?scroll=1m
{
"scroll_id": "FGluY2x1ZGVfY29udGV4dF91dWlkDXF1ZXJ5QW5kRmV0Y2gBFldmdGQ2Z2g3VDZTaDEzUVh1UGtFMEEAAAAAASy0whZQQTFUeW00clNQS1FQa1VVQkUyM3BR"
}














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









