







 本文介绍了Java8中Lambda表达式和StreamAPI在处理数据时的优势,包括简化代码、提高可读性,以及通过filter、map、collect等方法进行数据过滤、转换和收集的操作实例。
本文介绍了Java8中Lambda表达式和StreamAPI在处理数据时的优势,包括简化代码、提高可读性,以及通过filter、map、collect等方法进行数据过滤、转换和收集的操作实例。
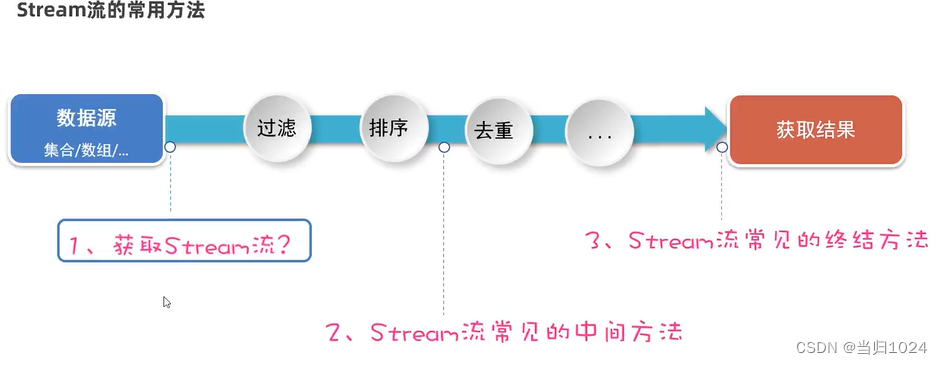
重要性
- jdk8最重要的两大特性:
lambda、stream- stream流:用于操作
数组([])或者集合(Collection)的数据- 优势:stream流大量的
结合了lambda的风格,代码更加简洁,可读性更好
使用步骤
代码示例List
- 一半在处理完数据之后,我们会重新把数据转换为Collection,所以就需要用到collect方法
- 此方法参数:一个Collector,用来转换为新集合
List<String> nameList = new ArrayList<>();
Collections.addAll(nameList, "张三丰", "张无忌", "张翠山", "张三", "赵敏", "周芷若", "张强");
// 1.过滤出姓张的 2.长度大于2的 3.转换为List
List<String> newNameList = nameList.stream().filter(name -> name.startsWith("张")).filter(name -> name.length() > 2)
.collect(Collectors.toList());
System.out.println(newNameList);
代码示例-Map
Map<String,Integer> nameMap = new HashMap<>();
nameMap.put("张三丰", 100);
nameMap.put("张无忌", 200);
nameMap.put("张翠山", 300);
nameMap.put("张三", 400);
nameMap.put("赵敏", 500);
nameMap.put("周芷若", 600);
// 1.过滤出key以张开头的 2.值大于200的 3.转换为Map
Map<String,Integer> newNameMap = nameMap.entrySet().stream(). // 获取stream流
filter(entry -> entry.getKey().startsWith("张")). // 过滤出key以张开头的
filter(entry -> entry.getValue() > 200) // 过滤出值大于200的
.collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue)); // 终结操作,转换为Map
System.out.println(newNameMap);
获取stream流

中间方法
- 中间方法:所谓的中间方法处理完数据之后,会
返回新的stream流,继续处理数据,这种编程方式又称为链式编程

数据
List<Student> studentList = new ArrayList<>();
studentList.add(new Student("张三丰", 100, 100, 1.80));
studentList.add(new Student("张三丰", 120, 80, 1.80));
studentList.add(new Student("张无忌", 20, 100, 1.70));
studentList.add(new Student("张翠山", 50, 40, 1.60));
studentList.add(new Student("张三", 30, 60, 1.70));
studentList.add(new Student("赵敏", 40, 80, 1.60));
studentList.add(new Student("周芷若", 60, 90, 1.70));
过滤和排序
// 1.过滤出年龄大于30的 2.分数大于60的 3.升序排序 4.转换为List
// filter() 过滤
// sorted() 排序 参数是Comparator接口
List<Student> newStudentList = studentList.stream()
.filter(student -> student.getAge() > 30)
.filter(student -> student.getScore() > 60)
.sorted((s1, s2) -> s1.getScore() - s2.getScore())
.collect(Collectors.toList());
System.out.println(newStudentList);
限制
// 2.找出成绩最高的3个学生
// limit(3) 限制最多3个元素
List top3StudentList = studentList.stream()
.sorted((s1, s2) -> s2.getScore() - s1.getScore())
.limit(3)
.collect(Collectors.toList());
System.out.println(top3StudentList);
去重
// 3.获取所有学生的名字 不可以重复 转为List<String>
// map() 转换 参数是Function接口
// distinct() 去重
List<String> nameList = studentList.stream()
.map(Student::getName)
.distinct()
.collect(Collectors.toList());
System.out.println(nameList);
自定义去重
// 4.去重之后找到年龄最大的4个学生(名字相同的视为同一个学生)
// 自定义去重
List<Student> max4StudentList = studentList.stream()
.filter(customDistinct())
.sorted((s1, s2) -> s2.getAge() - s1.getAge())
.limit(4)
.collect(Collectors.toList());
System.out.println(max4StudentList);
private static Predicate<Student> customDistinct() {
final Map<String,Student > map = new ConcurrentHashMap<>();
return student -> map.put(student.getName(), student) == null;
}
跳过
// 5.跳过
List skipStudentList = studentList.stream()
.skip(2)
.collect(Collectors.toList());
System.out.println(skipStudentList);
常见的终结方法-处理

// 1. 统计分数大于60的学生个数
long count = studentList.stream()
.filter(student -> student.getScore() > 60)
.count();
System.out.println(count);
// 2. 统计分数大于60的学生平均分
double average = studentList.stream()
.filter(student -> student.getScore() > 60)
.mapToInt(Student::getScore)
.average()
.getAsDouble();
System.out.println(average);
// 3. 统计分数大于60的学生总分
int sum = studentList.stream()
.filter(student -> student.getScore() > 60)
.mapToInt(Student::getScore)
.sum();
System.out.println(sum);
// 4. 统计分数大于60的学生最高分
int max = studentList.stream()
.filter(student -> student.getScore() > 60)
.mapToInt(Student::getScore)
.max()
.getAsInt();
System.out.println(max);
// 5. 统计分数大于60的学生最低分
int min = studentList.stream()
.filter(student -> student.getScore() > 60)
.mapToInt(Student::getScore)
.min()
.getAsInt();
System.out.println(min);
常见终结方法-收集stream流
- 把stream流中的
结果再次返回到数组或者集合中- stream流只能收集一次,
被收集过的流会被关闭,无法再收集

List<String> newNameList = nameList.stream().filter(name -> name.startsWith("张")).filter(name -> name.length() > 2)
.collect(Collectors.toList());
System.out.println(newNameList);
转换为Map的时候,有两个必要参数,
谁是键,谁是值
// 1.过滤出key以张开头的 2.值大于200的 3.转换为Map
Map<String,Integer> newNameMap = nameMap.entrySet().stream(). // 获取stream流
filter(entry -> entry.getValue() > 200) // 过滤出值大于200的
.collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue)); // 终结操作,转换为Map
toArray:转换为数组
//将所有名字转换为大写 转换为Array
String[] nameArray = nameList.stream().map(String::toUpperCase).toArray(String[]::new);















 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









