







一、Socket数据源
1、添加依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>3.0.0</version>
</dependency>2、在本地启动程序,读取虚拟机发送的数据
package SparkStream
import SparkSQL.UDF.UdfDemo.getStreamingContext
import org.apache.log4j.{Level, Logger}
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
object SocketStreaming extends App {
Logger.getLogger("org").setLevel(Level.ERROR)
//准备sparkStreaming环境
private val ssc = getStreamingContext()
//socket获取端口处理
private val socketLines: ReceiverInputDStream[String] = ssc.socketTextStream("hadoop01", 9999)
//进行rdd处理
private val resultDS: DStream[(String, Int)] = socketLines.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_ + _)
resultDS.print()
ssc.start()
ssc.awaitTermination()
}
3、在虚拟机发送数据
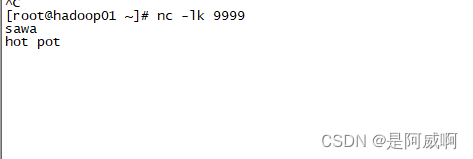
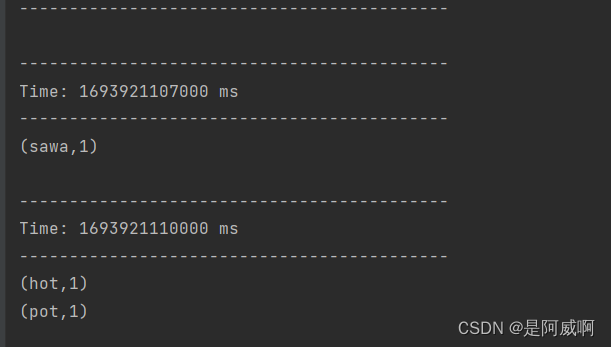
4、结果展示
读取到数据
二、kafka数据源
通过 SparkStreaming 从 Kafka 读取数据,并将读取过来的数据做简单计算,最终打印到控制台
1、导入依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>2.12.7</version>
</dependency>2、程序消费kafka数据
package SparkStream
import SparkSQL.UDF.UdfDemo.getStreamingContext
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.log4j.{Level, Logger}
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
object MyReceiverStreaming extends App {
Logger.getLogger("org").setLevel(Level.ERROR)
private val ssc: StreamingContext = getStreamingContext()
//定义 Kafka 参数
val kafkaPara: Map[String, Object] = Map[String, Object](
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG ->"hadoop01:9092,hadoop02:9092,hadoop03:9092",
ConsumerConfig.GROUP_ID_CONFIG -> "mySparkTopic",
"key.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer",
"value.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer"
)
private val value: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](Set("mySparkTopic"), kafkaPara)
)
value.map(_.value()).print()
ssc.start()
ssc.awaitTermination()
}
3、kafka操作
启动kafka,注意要关闭防火墙,或者放行相关端口
./bin/kafka-server-start.sh config/server.properties1>新建主题
bin/kafka-topics.sh --bootstrap-server hadoop01:9092 --create --topic mySparkTopic --partitions 3 --replication-factor 2
2>查看主题列表
bin/kafka-topics.sh --bootstrap-server hadoop01:9092 --list
3>生产数据
bin/kafka-console-producer.sh --broker-list hadoop01:9092 --topic mySparkTopic
4>消费数据结果
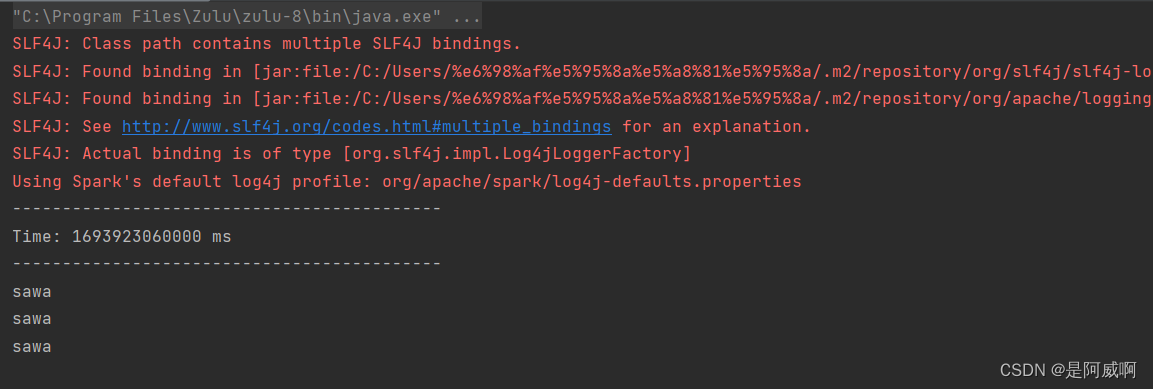
















 845
845











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









