






1.HiveQL官方说明地址
LanguageManual DDL - Apache Hive - Apache Software Foundation
2.操作数据库
2.1查看数据库(default为默认的数据库)
show databases;
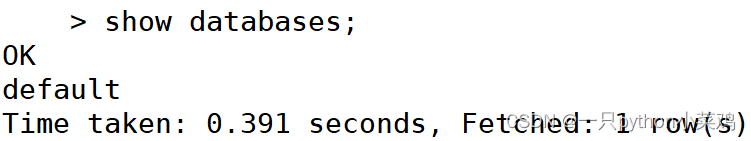
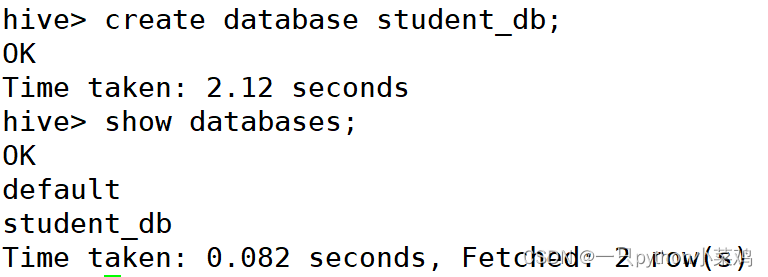
2.2创建数据库
create database database_name
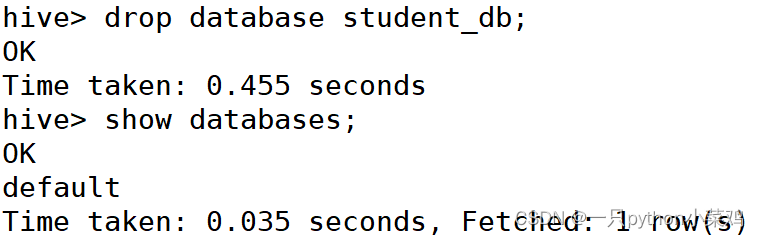
2.3删除数据库
drop database database_name;
2.4使用数据库(重新执行2.1命令,创建student_db库)
use database_name;

3.表操作
3.1查看表(由于新建的student_db数据库,故显示表为空)

3.2创建表
(1)常用创表语句
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name --EXTERNAL:创建外部表时使用
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] --创建分区表时,指定需要分区的字段
[CLUSTERED BY (col_name, col_name, ...) --创建分桶表时使用
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format] row format delimited fields terminated by --“指定字段之间的分隔符”
[STORED AS file_format]
[LOCATION hdfs_path] ;--指定表的存储路径(HDFS上的路径)
(2)创建临时表
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name
LIKE existing_table_or_view_name
[LOCATION hdfs_path];
(3)创建student_info表
CREATE TABLE STUDENT_INFO(
ID INT,
NAME STRING,
AGE INT,
SUBJECT ARRAY<STRING>,
SCORE MAP<STRING,FLOAT>,
HOME_ADDRESS STRUCT<ADDRESS_CODE:INT,ADDRESS_NAME:STRING>,
UPDATE_TIME DATE
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY "\t"
COLLECTION ITEMS TERMINATED BY '-'
MAP KEYS TERMINATED BY ':'
LINES TERMINATED BY '\n';
说明:
ROW FORMAT DELIMITED --分隔符开始语句
FIELDS TERMINATED BY "\t" --字段之间以制表符分隔
COLLECTION ITEMS TERMINATED BY '-' --数组和结构体各个数据之间以横杠分隔
MAP KEYS TERMINATED BY ':' --MAP的KEY和VALUE之间以冒号分隔
LINES TERMINATED BY '\n'; --行之间以换行符分隔

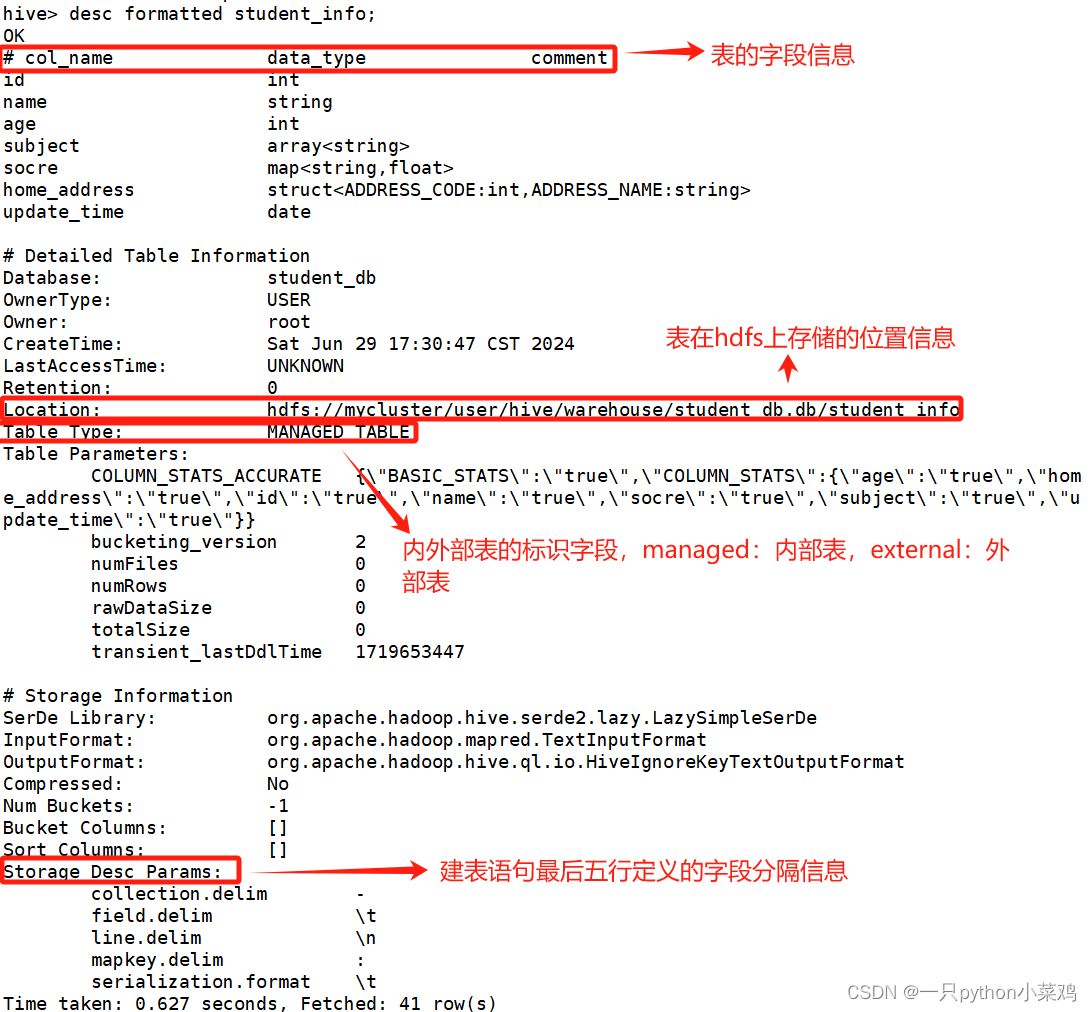
3.3查看表描述信息
desc formatted table_name;
3.4删除表
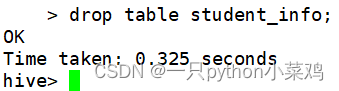
drop table table_name;
4.数据操作
4.1从本地向表中加载数据
(1)源数据

(2)加载数据命令:LOAD DATA LOCAL INPATH 'local_filepath' INTO TABLE table_name;

(3)查询结果,数据加载成功

注:SCORE的值定义为FLOAT类型,源数据中含有INT类型数据,查询结果中,自动补充一位数字0
4.2从HDFS上的文件向表中加载数据
(1)源数据
 (2)上传student_info_addsrc.txt文件到hdfs上
(2)上传student_info_addsrc.txt文件到hdfs上
(3)加载数据命令:LOAD DATA INPATH 'hdfs_filepath' INTO TABLE table_name

(4)查询结果,数据加载成功
 4.3加载数据小结见图片
4.3加载数据小结见图片

4.4删除数据
HiveQL中没有delete语句,删除数据需要用truncate语句:truncate table table_name;
5.复合数据类型查询
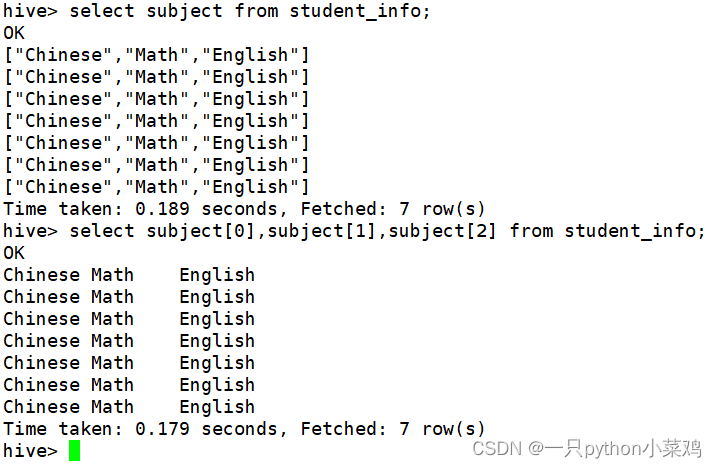
(1)array类型字段查询:array_name[index]
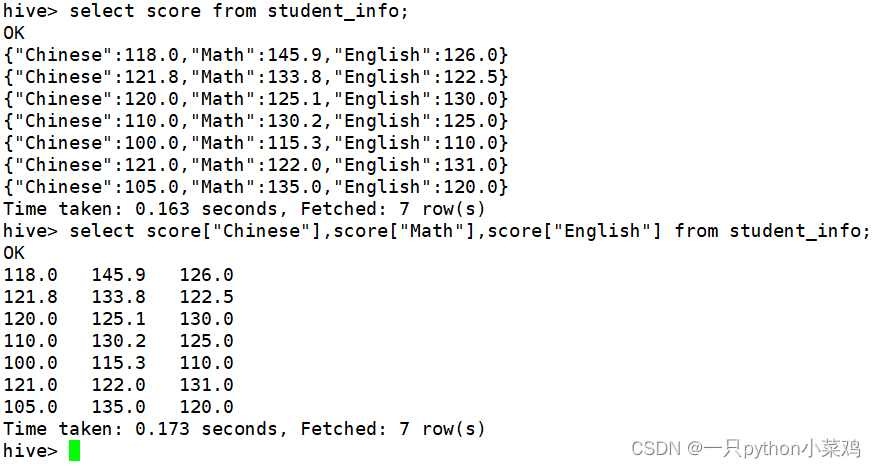
(2)MAP类型字段查询:map_name["键"]
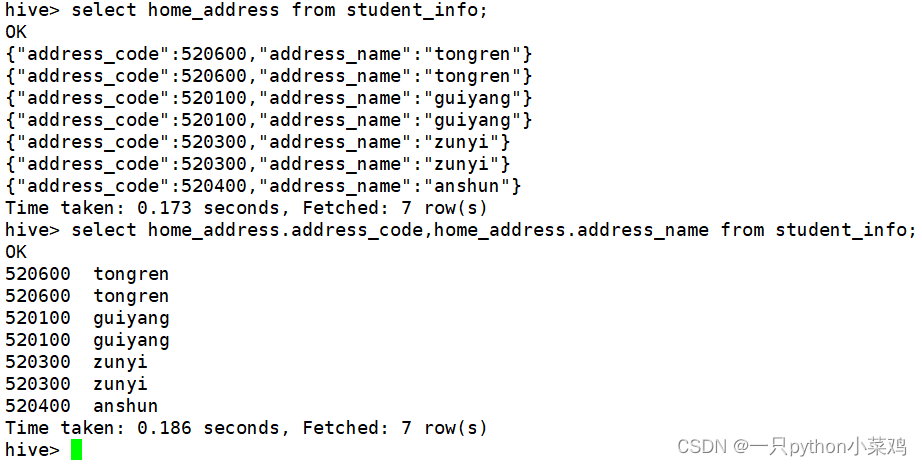
(3)struct类型字段查询:struct_name."键"















 487
487

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









