







 本文介绍了三种时间复杂度为O(nlgn)的排序算法:希尔排序、堆排序和归并排序。希尔排序通过设置增量步长进行分组排序,最终实现整体效率提升。堆排序利用大顶堆或小顶堆结构进行排序,时间复杂度稳定在O(nlogn)。归并排序采用分治策略,通过两两归并确保排序效果,非递归实现能有效减少空间复杂度。
本文介绍了三种时间复杂度为O(nlgn)的排序算法:希尔排序、堆排序和归并排序。希尔排序通过设置增量步长进行分组排序,最终实现整体效率提升。堆排序利用大顶堆或小顶堆结构进行排序,时间复杂度稳定在O(nlogn)。归并排序采用分治策略,通过两两归并确保排序效果,非递归实现能有效减少空间复杂度。
希尔排序
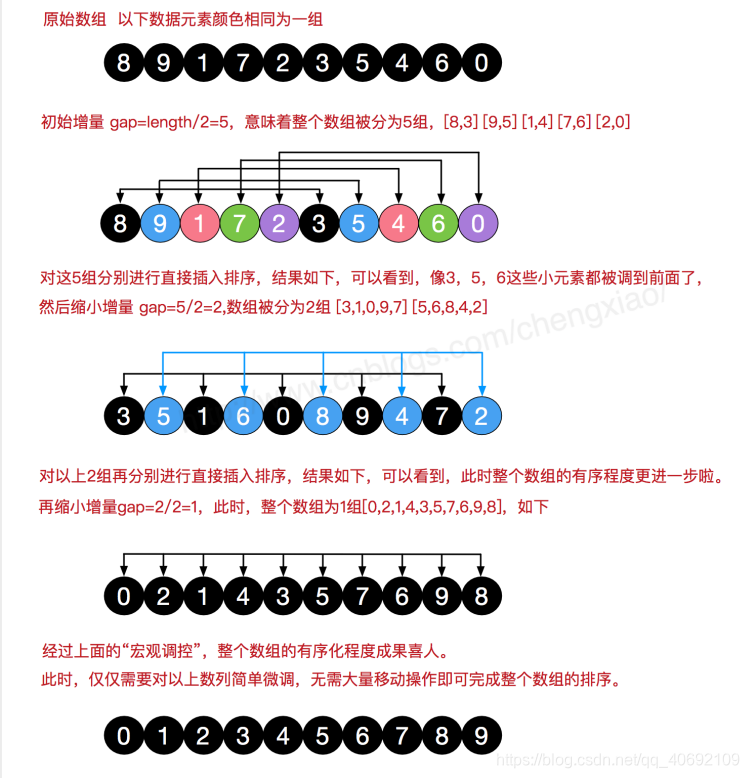
我们前面讲的直接插入排序, 应该说,它的效率在某些时候是很高的,比如,我们的记录本身就是基本有序的,我们只需要少量的插入操作,就可以完成整个记录集的排序工作,此时直接插入很高效。还有就是记录数比较少时,直接插入的优势也比较明显。可问题在于,两个条件本身就过于苛刻,现实中记录少或者基本有序都属于特殊情况。有条件当然是好,条件不存在,我们创造条件也是可以去做的。于是科学家希尔研究出了一种排序方法,对直接插入排序改进后可以增加效率。
如何让待排序的记录个数较少呢?很容易想到的就是将原本有大量记录数的记录进行分组。分割成若千个子序列,此时每个子序列待排序的记录个数就比较少了,然后在这些子序列内分别进行直接插入排序,当整个序列都基本有序时,注意只是基本有序时,再对全体记录进行一次直接插入排序。这就是希尔排序的基本思想。
希尔排序也是一种插入排序,它是简单插入排序经过改进之后的一个更高效的版本,也称为缩小增量排序,同时该算法是冲破O(n2)的第一批算法之一。它与插入排序的不同之处在于,它会优先比较距离较远的元素。希尔排序又叫缩小增量排序。
首先确定一个增量步长step,将整个数据每相隔step的数分为一组,则一共有step个组,对每个组分别插入排序,之后再减小step的值重复之前的操作,直至step为1。
void shell_sort(int a[], int n) {
int k,j;
int step = n;
do {
step = step / 3; //设置增量,标准不唯一,这里设置为除以3,很多地方都是除以2
for (int i = step; i < n; i++)
{
if (a[i] < a[i - step])
{ //将相隔step的数看作一组进行插入排序(即一共step个组,每个组分别插入排序)
k = a[i];
for (j = i - step; j >= 0 && k < a[j]; j -= step)
{
a[j + step] = a[j];
}
a[j + step] = k;
}
}
}
while (step > 1);
}
复杂度分析
希尔排序是一种插入排序,只需要O(1)的复杂空间,最好时间复杂度为O(n^1.3),最坏时间复杂度为O(n^2),平均时间复杂度为O(nlogn)。(不太懂,不同地方说的都不一样)
堆排序
什么是堆
通俗来讲堆其实就是利用完全二叉树的结构来维护的一维数组。
大顶堆:每个结点的值都大于或等于其左右孩子结
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









