









一、 集群间数据拷贝
- scp实现两个远程主机之间的文件复制
scp -r hello.txt root@hadoop103:/user/atguigu/hello.txt // 推 push scp -r root@hadoop103:/user/atguigu/hello.txt hello.txt // 拉 pull scp -r root@hadoop103:/user/atguigu/hello.txt root@hadoop104:/user/atguigu //是通过本地主机中转实现两个远程主机的文件复制;如果在两个远程主机之间ssh没有配置的情况下可以使用该方式。
2.采用distcp命令实现两个Hadoop集群之间的递归数据复制
[atguigu@hadoop102 hadoop-2.7.2]$ bin/hadoop distcp hdfs://haoop102:9000/user/atguigu/hello.txt hdfs://hadoop103:9000/user/atguigu/hello.txt
二、小文件存档
2.1、HDFS存储小文件弊端
每个文件均按块存储u,每个块的元数据存储在NameNode的内存中,因此HDFS存储小文件非常低效,因为大量的小文件会耗尽NameNode中的大部分内存。但注意,存储小文件所需要的磁盘容量和数据块大小无关。
2.2、 解决方法之一
HDFS存档文件(har结尾的文件),是一个高效的文件存档工具,它将文件存入HDFS块,在减少NameNode对内存使用的同时,允许对为了将进行透明的访问。具体来说:HDFS存档文件对内还是一个一个独立的文件,对NameNode而言是一个整体,减少了NameNode的内存。
-
启动yarn进程
-
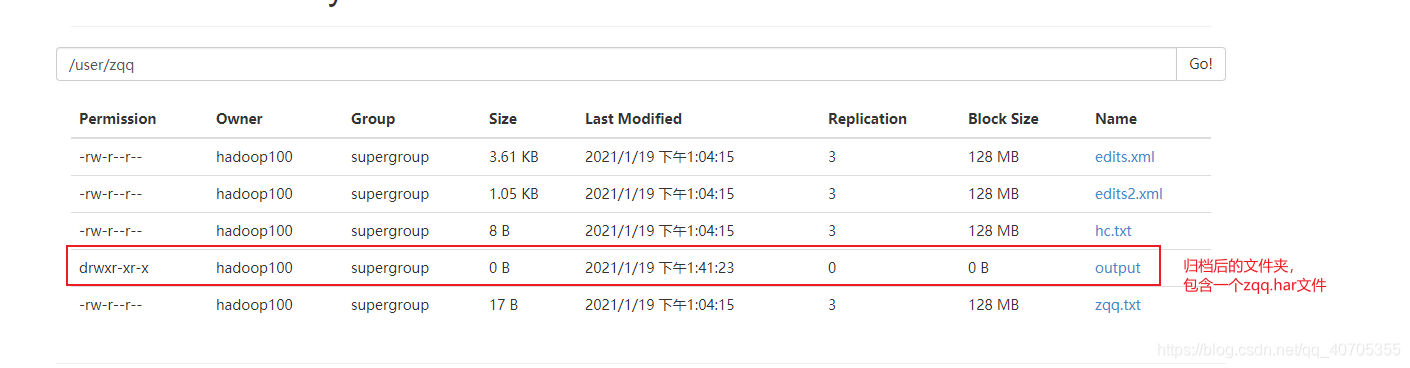
进行归档
$ hadoop archive -archiveName zqq.har -p /user/zqq/ /user/zqq/output/
-
查看归档
[hadoop100@hadoop102 hadoop-2.7.2]$ hdfs dfs -lsr /user/zqq/output/zqq.har lsr: DEPRECATED: Please use 'ls -R' instead. -rw-r--r-- 3 hadoop100 supergroup 0 2021-01-19 13:54 /user/zqq/output/zqq.har/_SUCCESS -rw-r--r-- 5 hadoop100 supergroup 376 2021-01-19 13:54 /user/zqq/output/zqq.har/_index -rw-r--r-- 5 hadoop100 supergroup 23 2021-01-19 13:54 /user/zqq/output/zqq.har/_masterindex -rw-r--r-- 3 hadoop100 supergroup 4797 2021-01-19 13:54 /user/zqq/output/zqq.har/part-0 # 普通方式是查看不了的,要通过har协议 [hadoop100@hadoop102 hadoop-2.7.2]$ hdfs dfs -ls -R har:///user/zqq/output/zqq.har -rw-r--r-- 3 hadoop100 supergroup 3699 2021-01-19 13:04 har:///user/zqq/output/zqq.har/edits.xml -rw-r--r-- 3 hadoop100 supergroup 1073 2021-01-19 13:04 har:///user/zqq/output/zqq.har/edits2.xml -rw-r--r-- 3 hadoop100 supergroup 8 2021-01-19 13:04 har:///user/zqq/output/zqq.har/hc.txt -rw-r--r-- 3 hadoop100 supergroup 17 2021-01-19 13:04 har:///user/zqq/output/zqq.har/zqq.txt -
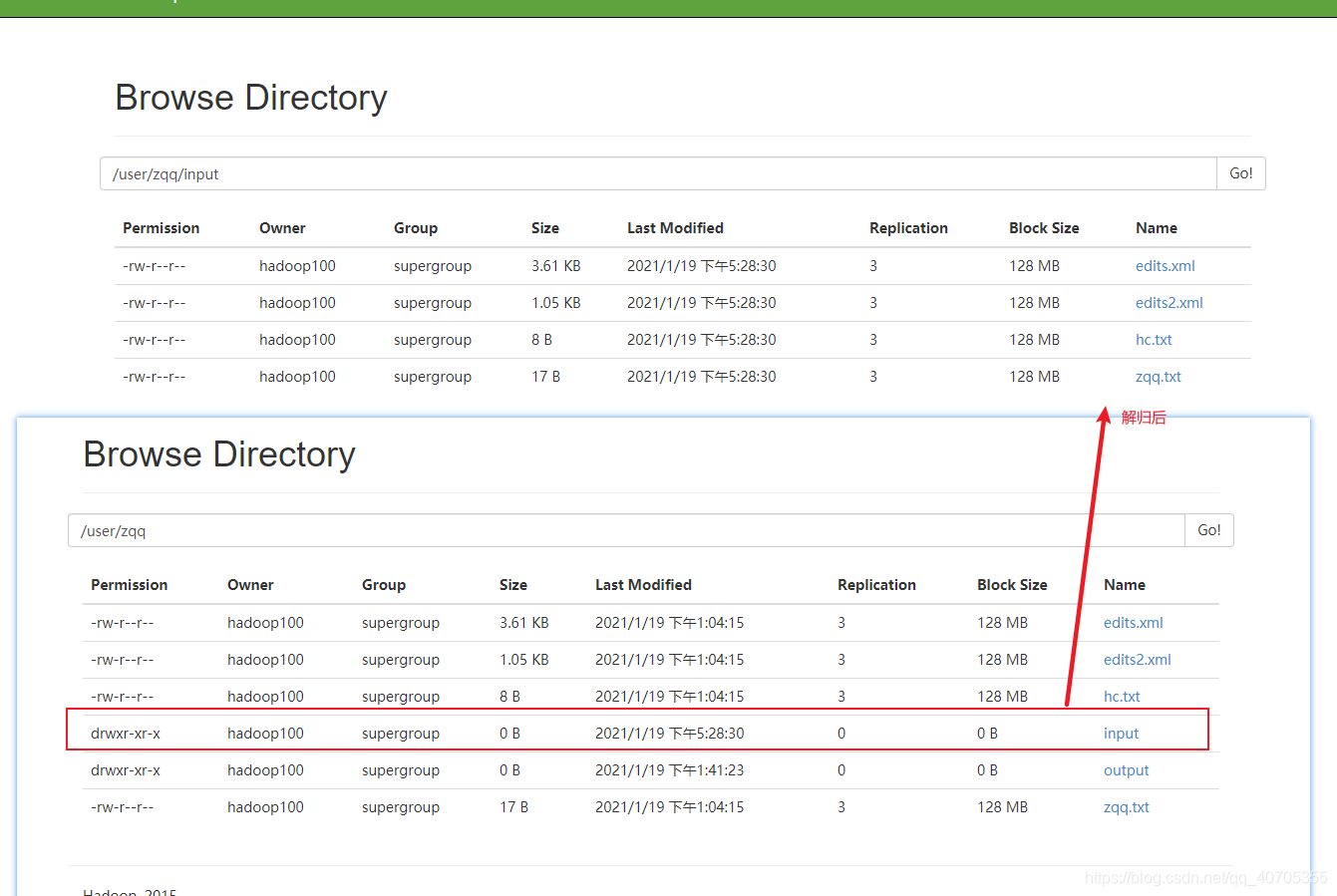
解归档文件
$ hdfs dfs -cp har:///user/zqq/output/zqq.har/* /user/zqq/input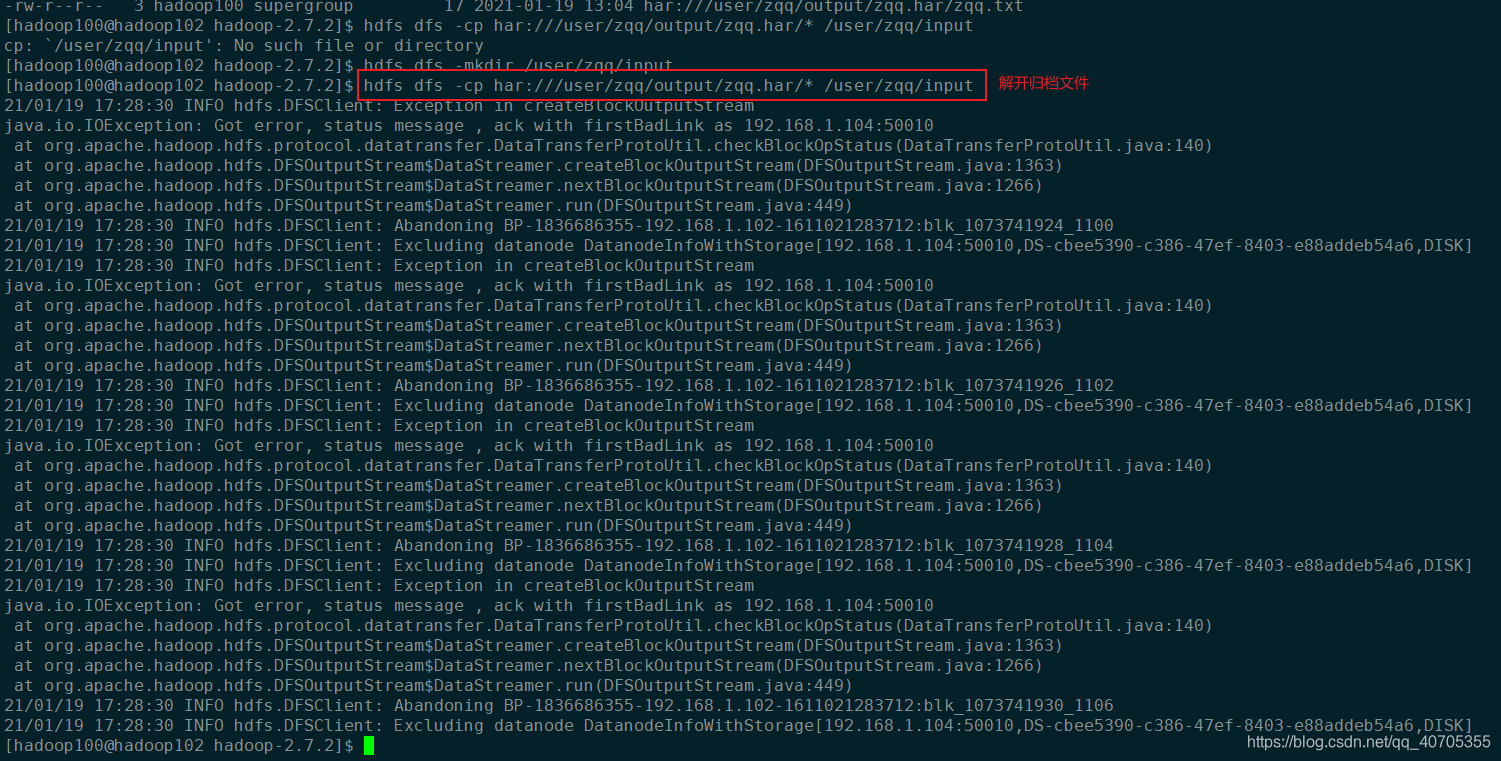
2.3、回收站
开启回收站功能,可以将删除的文件在不超时的情况下,恢复原数据,起到防止误删除、备份等作用。
相关参数
1、默认值fs.trash.interval=0,0表示禁用回收站;其他值表示设置文件的存活时间。
2、默认值fs.trash.checkpoint.interval=0,检查回收站的间隔时间。如果该值为0,则该值设置和fs.trash.interval的参数值相等。
3、要求fs.trash.checkpoint.interval<=fs.trash.interval。
-
启用回收站:修改
core-site.xml,配置垃圾回收时间为1分钟。 -
修改访问垃圾回收站用户名:
core-site.xml<property> <name>hadoop.http.staticuser.user</name> <value>hadoop100</value> </property> -
删除一个文件,查看回收站
[hadoop100@hadoop103 hadoop]$ hdfs dfs -rm /user/zqq/zqq.txt 21/01/19 18:24:38 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 1 minutes, Emptier interval = 0 minutes. Moved: 'hdfs://hadoop102:9000/user/zqq/zqq.txt' to trash at: hdfs://hadoop102:9000/user/hadoop100/.Trash/Current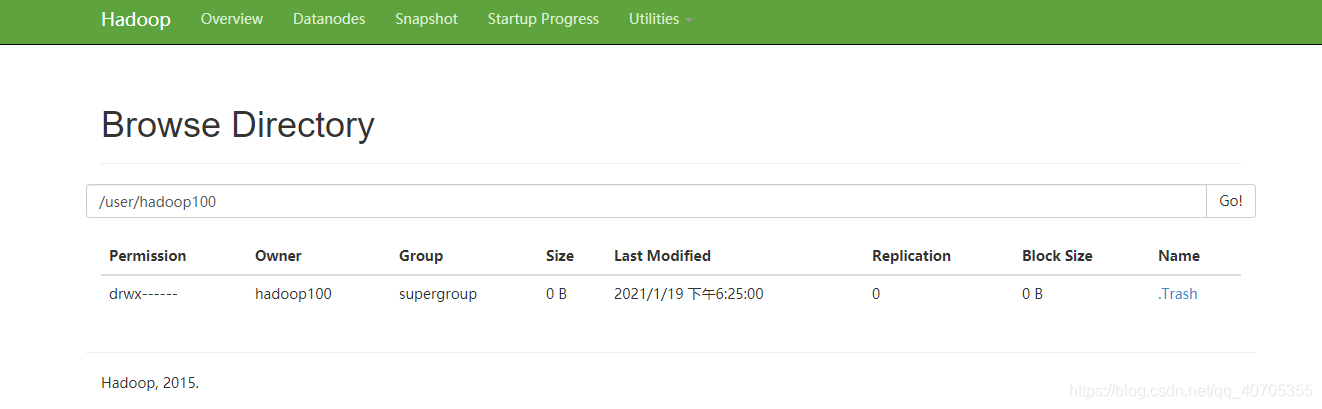
-
恢复回收站数据
hadoop fs -mv /user/hadoop100/.Trash/Current/user/atguigu/input /user/hadoop100/input -
清空回收站
hadoop fs -expunge
三、快照管理
快照相当于对目录做一个备份。并不会立即复制所有文件,而是记录文件变化。
- 开启指定目录的快照功能
hdfs dfsadmin -allowSnapshot 路径 - 禁用指定目录的快照功能,默认是禁用
hdfs dfsadmin -disallowSnapshot 路径 - 对目录创建快照
hdfs dfs -createSnapshot 路径 - 指定名称创建快照
hdfs dfs -createSnapshot 路径 名称 - 重命名快照
hdfs dfs -renameSnapshot 路径 旧名称 新名称 - 列出当前用户所有可快照目录
hdfs lsSnapshottableDir - 比较两个快照目录的不同之处
hdfs snapshotDiff 路径1 路径2 - 删除快照
hdfs dfs -deleteSnapshot <path> <snapshotName>















 8435
8435











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











