







一、MySQL进阶查询
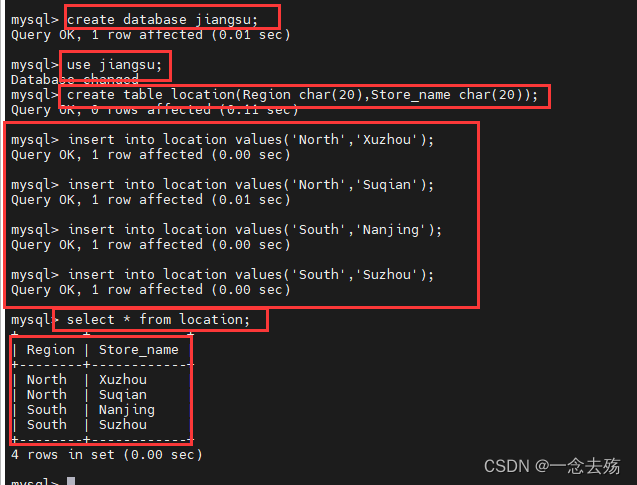
首先先创建两张表
mysql -u root -pXXX #登陆数据库,XXX为密码
create database jiangsu; #新建一个名为jiangsu的数据库
use jiangsu; #使用该数据库
create table location(Region char(20),Store_name char(20)); #创建location表,字段1为Region,数据类型为char,数据长度为20;字段2为Store_name,数据类型为char,长度为20.
insert into location values('North','Xuzhou'); #插入4条数据
insert into location values('North','Suqian');
insert into location values('South','Nanjing');
insert into location values('South','Suzhou');
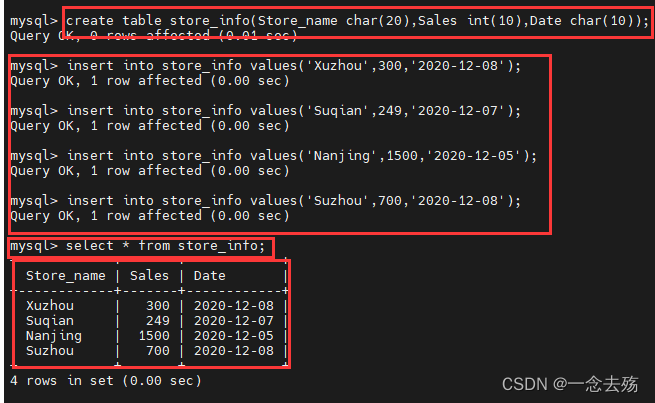
create table store_info(Store_name char(20),Sales int(10),Date char(10)); #再创建一张store_info表
insert into store_info values('Xuzhou',300,'2020-12-08'); #插入4条数据
insert into store_info values('Suqian',249,'2020-12-07');
insert into store_info values('Nanjing',1500,'2020-12-05');
insert into store_info values('Suzhou',700,'2020-12-08');
----------------select-------------------
select用于查询表格中的一个或多个字段的数据记录
语法格式:select 字段1,字段2,... from 表名;
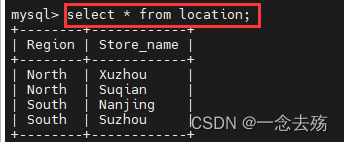
select * from location; #查询location表中的所有字段,*表示所有,如果不嫌麻烦,当然也可以将所有字段都输进去
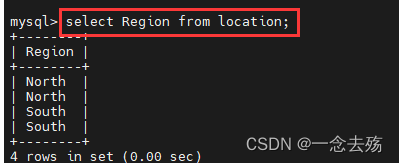
select Region from location; #查询location表中的Region的数据
select sales,Date from store_info; #查询store_info表中的sales,Date字段的数据
----------------DISTINCT-------------------
DISTINCT用于将重复的数据压缩为一个
语法格式:select distinct 字段名 from 表名;
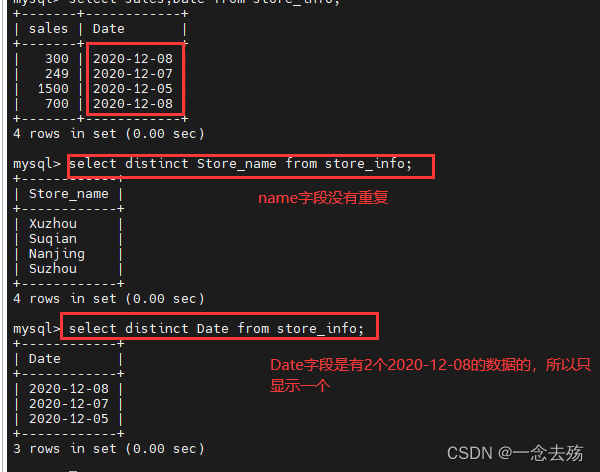
select distinct Store_name from store_info; #查询dtore_info表中的Store_name字段的数据,如有重复,则只显示一个
----------------where-------------------
where用于带条件查询
语法格式:select 字段名 from 表名 where 条件语句;
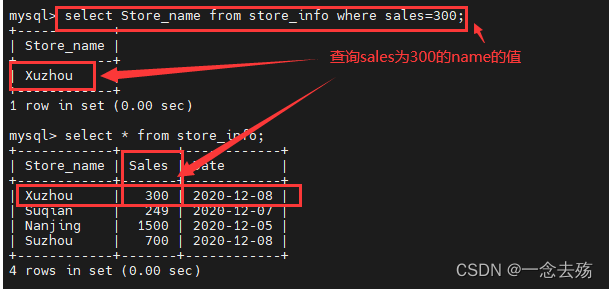
select Store_name from store_info where sales=300; #查询store_info表中sales字段的值等于300的Store_name的数据
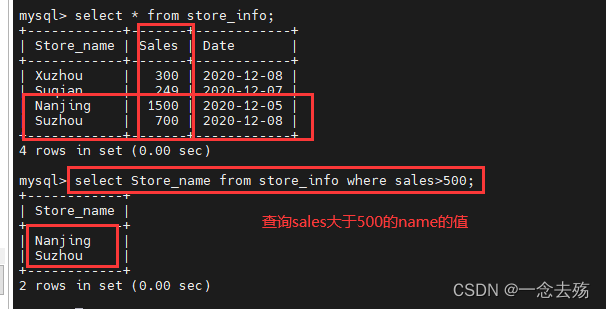
select Store_name from store_info where sales>500; #查询store_info表中sales字段的值大于500的Store_name的数据
----------------and or-------------------
and,且,用于查询一个数据范围;or,或,用于查询包含条件语句的所有数据
语法格式:select 字段名 from 表名 where 条件1 and/or 条件2;
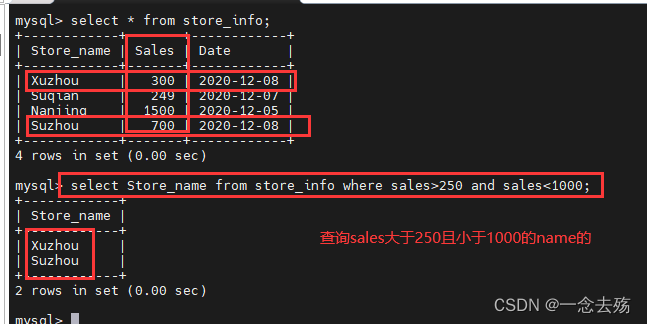
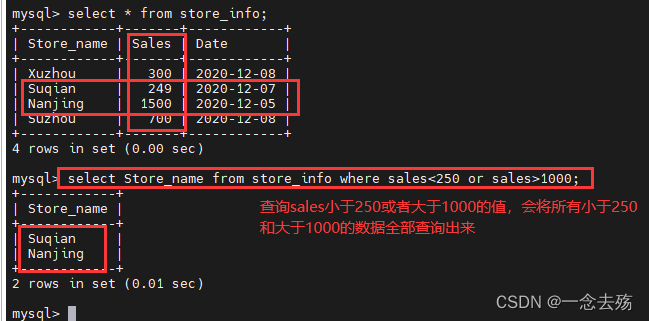
select Store_name from store_info where sales>250 and sales<1000; #查询store_info表中sales字段的值大于250,且小于1000的Store_name的数据
select Store_name from store_info where sales<250 or sales>1000; #查询store_info表中sales字段的值小于250,或者 大于1000的Store_name的数据
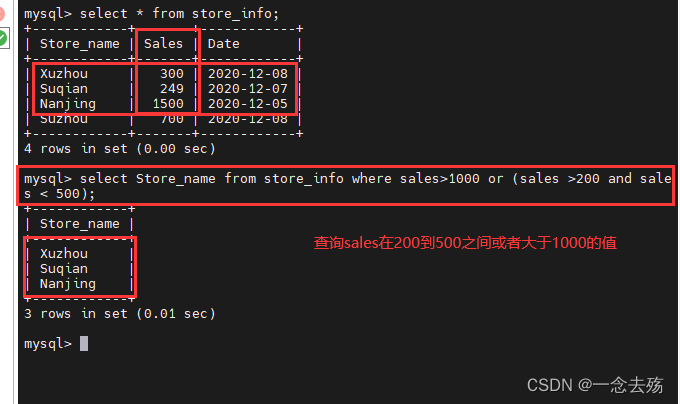
select Store_name from store_info where sales>1000 or (sales >200 and sales < 500); #括号的优先级高,所以先根据括号里的and条件语句进行筛选,然后再根据or进行筛选,最后查询最终筛选出来的数据;该语句先筛选出sales大于200且小于500的值,再使用or进行或的删选,最终筛选出来的结果应该是在200到500之间的值或者大于1000的值。
select Store_name from store_info where sales>1000 or sales >200 and sales < 500; #如果不加括号,and的优先级是比or要高的,也就是说,当一条条件语句中同时存在and和or(没有括号),会先执行and条件。
----------------in-------------------
in用来显示已知值的数据,简单来说,in后面跟的是一个数据集合,查询语句会根据数据集合中的值进行筛选查询。not in 就是取数据集合中的反,不在数据集合中的数据。
语法格式:select 字段名1 from 表名 where 字段名2 in ('字段名2的值1','字段名2的值2,......');
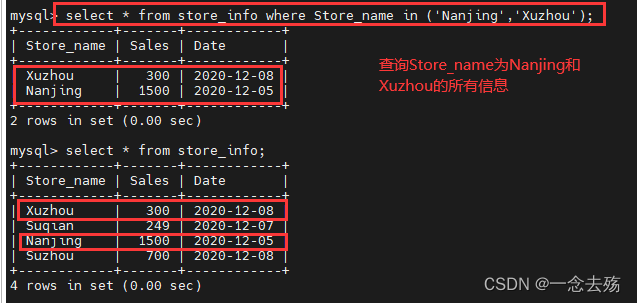
select * from store_info where Store_name in ('Nanjing','Xuzhou'); #将Nanjing和Xuzhou的所有信息都查询出来。
注:in可以用or代替
上述语句等于:select * from store_info where Store_name='Nanjing' or Store_name='Xuzhou';
----------------between...and-------------------
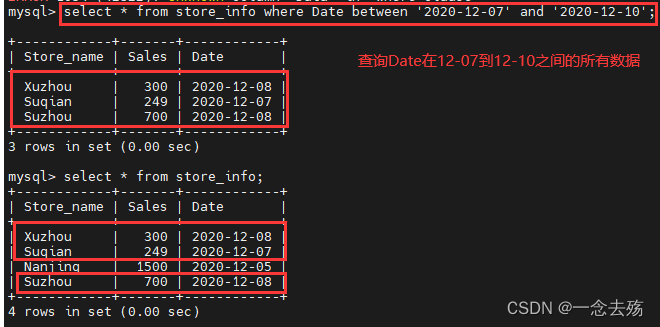
between 值1 and 值2 ,在值1与值2之间(值2 > 值1),该语句查询的是一个范围,包含值1和值2。其作用相在某一方面当于大于等于 ... and 小于等于 ... 。
语法格式:select 字段名 from 表名 where 字段名 between 值1 and 值2;
select * from store_info where Date between '2020-12-07' and '2020-12-10'; #查询store_info表中的Data的值在12-06与12-10之间的所有数据
----------------通配符-------------------
通配符一般情况下和like一起使用进行模糊查询,模糊查询的概念就是将所有符合条件的数据全部查询出来,而等于号是精确查询,会直接将具体的某一数据查询出来
模糊查询的字符如下:
%:百分号表示0个,1个或多个字符
_:下划线表示单个字符
语法格式:select 字段 from 表名 where 字段 like '通配符';
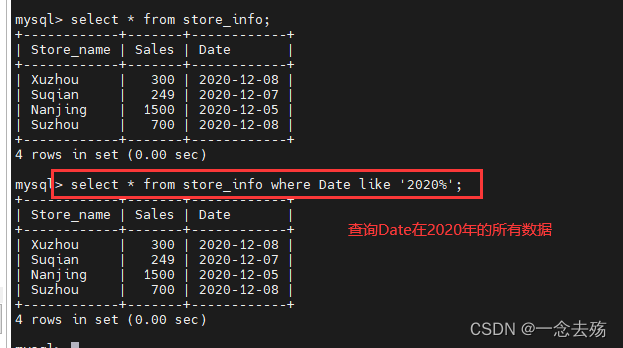
select * from store_info where Date like '2020%'; #将Date的值为2020,后面随便(2020后有没有都行)的值全部查询出来
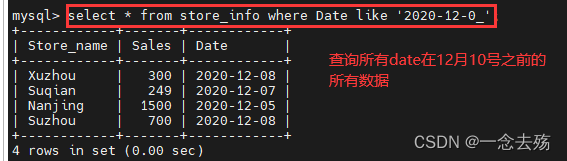
select * from store_info where Date like '2020-12-0_'; #将2020-12-0,后面只能匹配一个字符(必须存在且只能有一个)的所有数据查询出来
----------------like-------------------
like,模糊查询,用于查询符合条件的所有数据,通常和通配符一起使用,语法和通配符一样的,因为是结合使用。
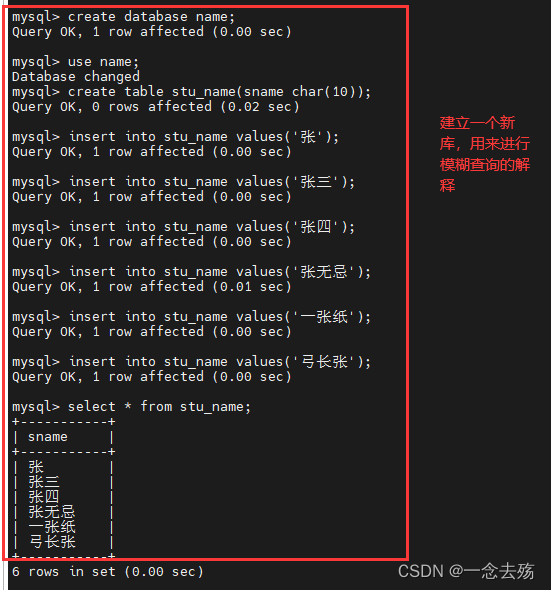
create database name;
use name;
create table stu_name(sname char(10));
insert into stu_name values('张');
insert into stu_name values('张三');
insert into stu_name values('张四');
insert into stu_name values('张无忌');
insert into stu_name values('一张纸');
insert into stu_name values('弓长张');
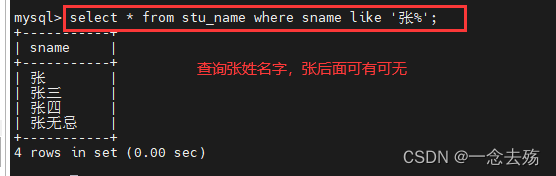
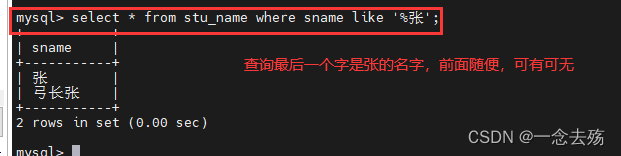
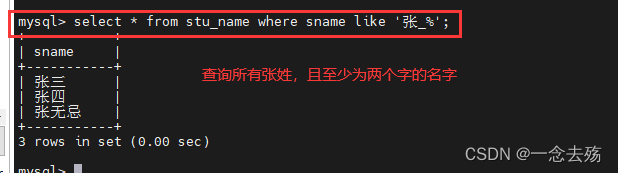
select * from stu_name where sname like '张%'; #查询所有张姓的名字,只要姓张就行
select * from stu_name where sname like '%张'; #查询所有最后一个字是张的姓名,前面无所谓
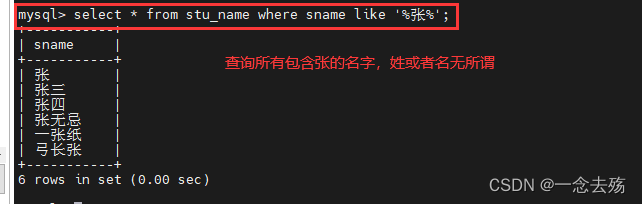
select * from stu_name where sname like '%张%'; #查询所有包含张的姓名,张字在姓在名都行
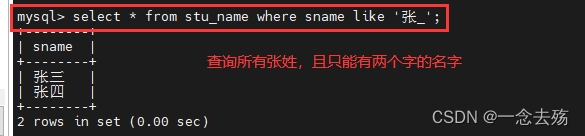
select * from stu_name where sname like '张_'; #查询所有张姓且只有两个字的名字
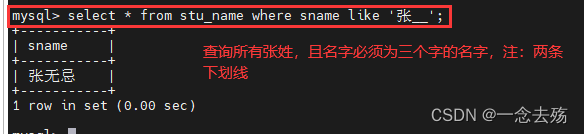
select * from stu_name where sname like '张__';(两条下划线) #查询所有张姓,且必须为三个字的名字
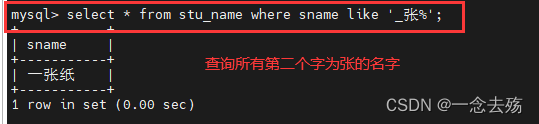
select * from stu_name where sname like '_张%'; #查询所有第二个字为张的名字
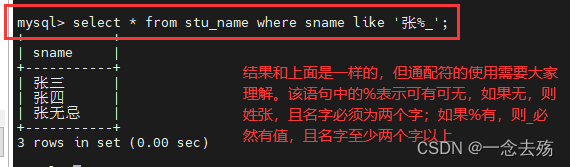
select * from stu_name where sname like '张_%'; #查询所有张姓,名字至少包含两个字的名字
select * from stu_name where sname like '张%_'; #查询所有张姓,名字至少包含两个字的名字,该语句和上面的查询结果一样,但理解是不同的。
----------------order by-------------------
order by 用于关键字的排序
语法格式:select 字段 from 表名 [where 条件语句] order by 字段 asc/desc;
asc:按字段升序,默认为asc
desc:按字段降序
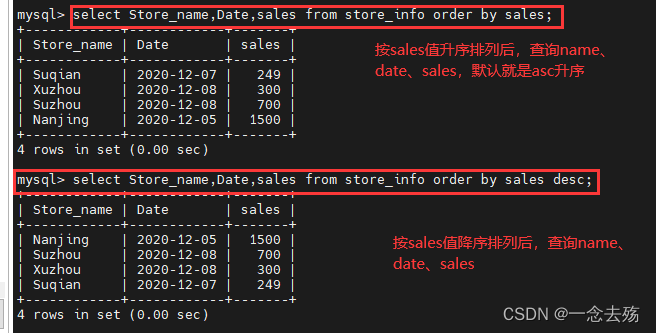
select Store_name,Date,sales from store_info order by sales; #按照sales升序排列后,查询name、date和sales
select Store_name,Date,sales from store_info order by sales desc; #按照sales降序排列后,查询name、date和sales


二、MySQL数据库函数
-------------数学函数-------------------
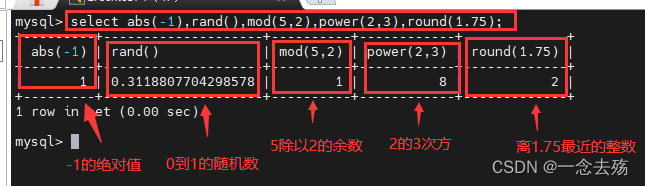
abs(x) #返回x的绝对值
rand() #返回0到1之间的随机数
mod(x,y) #返回x除以y的余数
power(x,y) #返回x的y次方
round(x) #返回离x最近的整数
round(x,y) #保留x的y位小数四舍五入之后的值
sqrt(x) #返回x的平方根
truncate(x,y) #返回x截断为y位小数的值
ceil(x) #返回大于或等于x的最小整数
floor(x) #返回小于或等于x的最大整数
greatest(x,y,z,...) #返回集合中最大的值
least(x,y,z,...) #返回集合中最小的值
---------------------------------------------
select abs(-1),rand(),mod(5,2),power(2,3),round(1.75);
select round(3.1415926,5),sqrt(2),truncate(3.141592653,4),ceil(5.2),floor(3.2),greatest(1.61,2.54,0.87),least(5.23,8.71,4.13);


--------------聚合函数--------------------
avg() #返回指定列的平均值
count() #返回指定列中非空值的个数
min() #返回指定列的最小值
max() #返回指定列的最大值
sum(x) #返回指定列的所有值的和
------------------------------------------
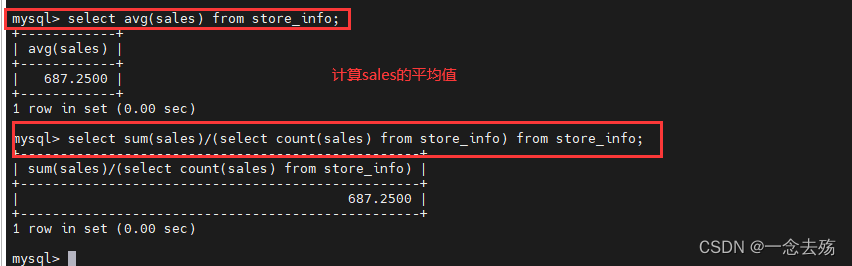
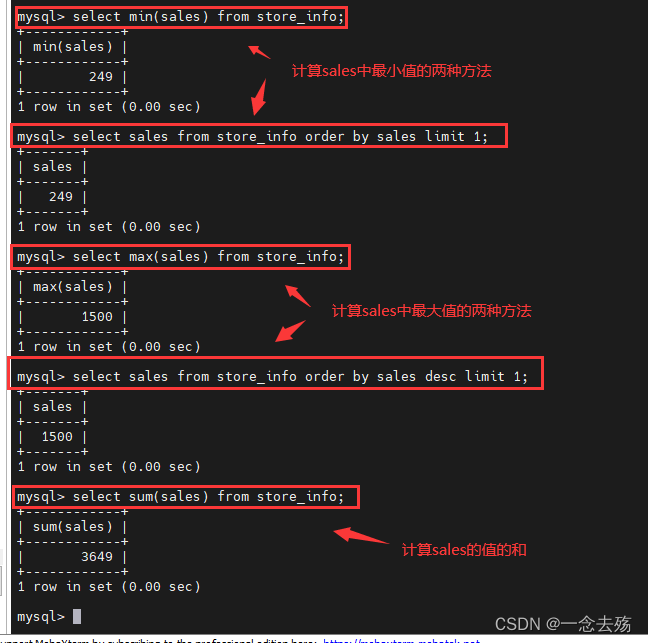
select avg(sales) from store_info; #查询sales的平均值
平均值的另一种方法:
select sum(sales)/(select count(sales) from store_info) from store_info;
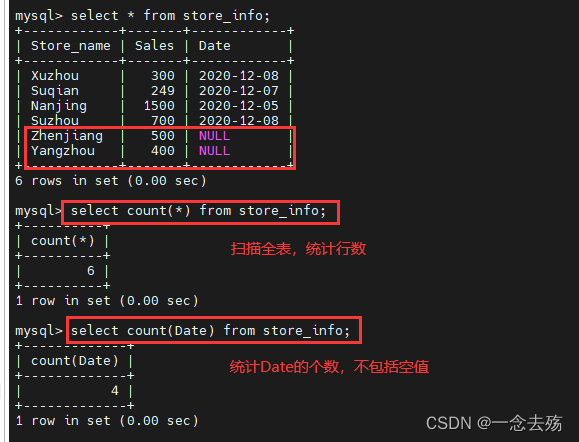
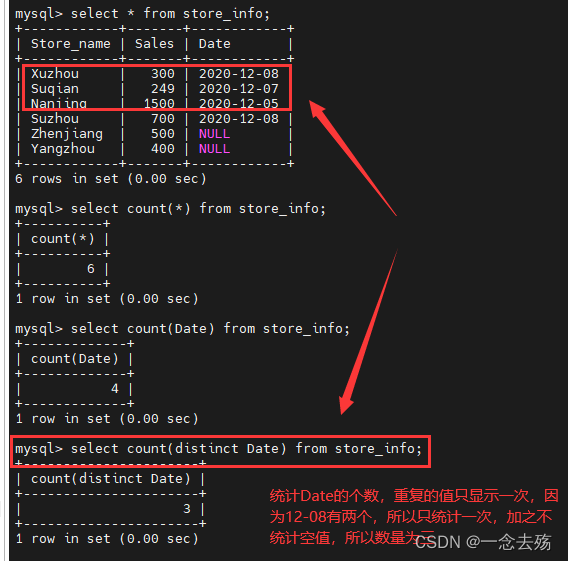
select count(Date) from store_info; #统计Date的数据个数,包括重复的值,但不包括空值
select count(distinct Date) from store_info; #统计Date的数据个数,重复的数据只统计一次,不包括空值
select count(*) from store_info; #全部统计,包括空值,count(*)扫描全表
select min(sales) from store_info; #查询sales的最小值
最小值的另一种方法:
select sales from store_info order by sales limit 1;
select max(sales) from store_info; #查询sales的最大值
最大值的另一种方法:
select sales from store_info order by sales desc limit 1;
select sum(sales) from store_info; #查询sales的和
-----------------字符串函数--------------------
trim() #返回去除指定格式的值
concat(x,y) #将提供的参数x和y拼接成一个字符串
substr(x,y) #获取字符串x中第y个位置开始的字符串,跟substring()函数作用相同
substr(x,y,z) #获取字符串x中第y个位置开始,长度为z的字符串
length(x) #返回字符串x的长度
replace(x,y,z) #将字符串z替代字符串x中的字符串y
upper(x) #将字符串x中的所有字母变成大写
lower(x) #将字符串x中的所有字母变成小写
left(x,y) #返回字符串x中的前y个字符
right(x,y) #返回字符串x中的后y个字符
repeat(x,y) #将字符串x重复y次
space(x) #返回x个空格
strcmp(x,y) #比较x和y,返回的值可以为-1,0,1
reverse(x) #将字符串x反转
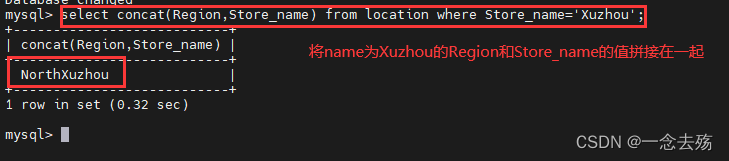
select concat(Region,Store_name) from location where Store_name='Xuzhou'; #将location表中Store_name='Xuzhou'的Region,Store_name的值拼接在一起
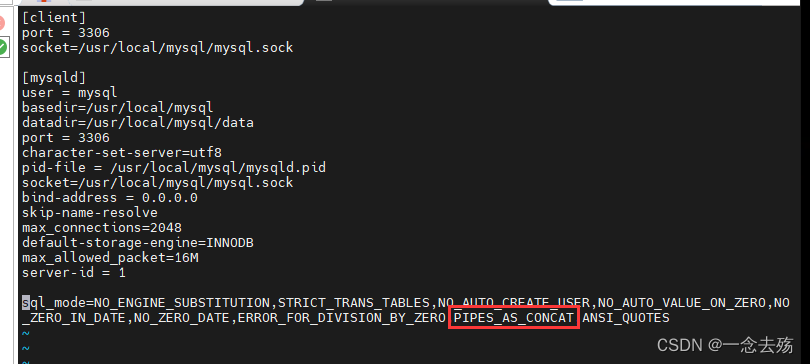
select Region || ' ' || Store_name from location where Store_name='Xuzhou'; #在my.cnf中开启了PIPES_AS_CONCAT模式后,可以使用 || 代替concat函数,将多个字符串拼接在一起
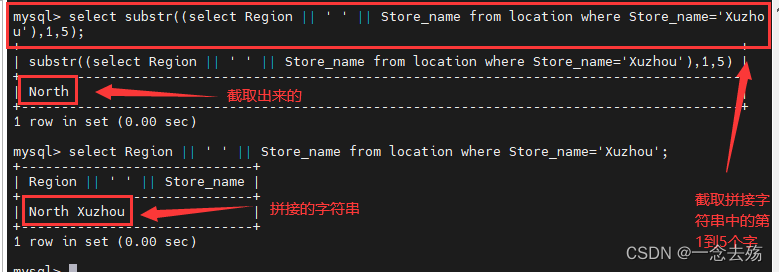
select substr(Store_name,3) from store_info where Store_name='Suqian'; #将Suqian的第3个字符往后的所有字符截取出来
select substr((select Region || ' ' || Store_name from location where Store_name='Xuzhou'),1,5); #将上一条拼接的字段的第1到5个字符截取出来
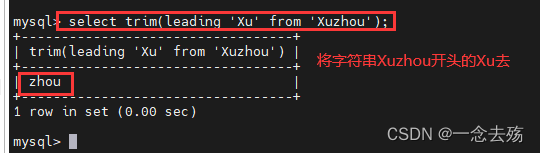
select trim([[位置] [要除移的字符串] from] 字符串);
#位置:leading(开头),tariling(结尾),both(开头及结尾)
#要除移的字符串:从字符串的开头、结尾,或开头及结尾除移的字符串,缺省时为空格
select trim(leading 'Xu' from 'Xuzhou'); #将Xuzhou开头的Xu去掉
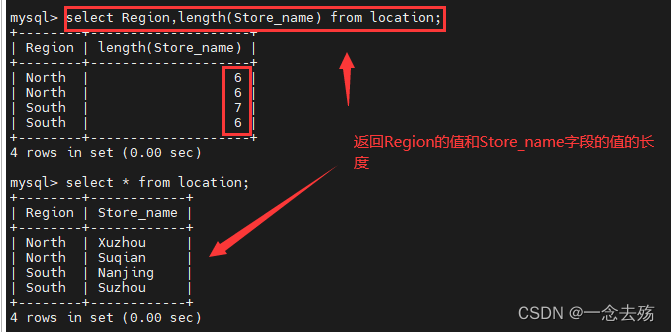
select Region,length(Store_name) from location; #查询location表中的Region字段的值和Store_name的值的长度
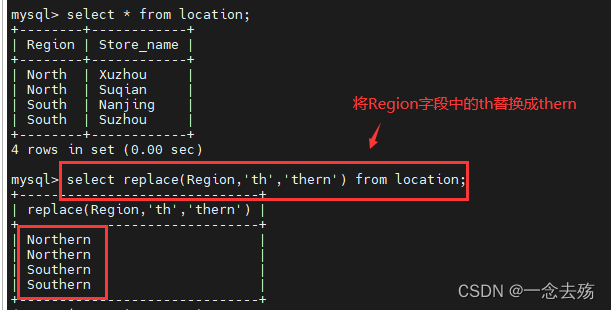
select replace(Region,'th','thern') from location; #将location表中的Region字段的值包含th的替换为thern,然后返回。
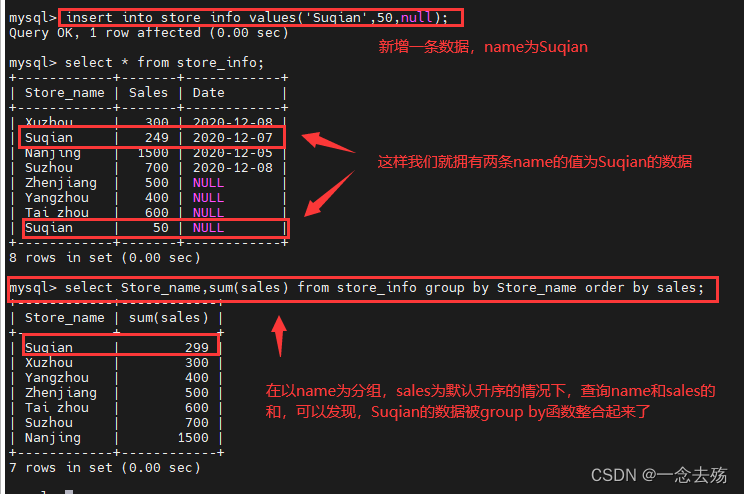
------------------group by-------------------
group by用于对查询结果进行汇总分组,通常是结合聚合函数
一起使用,group by有一个原则,凡是在group by后面出现的
字段,必须在select后面出现。凡是在select后面出现、且未在
group by后面出现的字段,必须出现在group by后面。
语法格式:select 字段1,sum(字段2) from 表名 group by 字段1;
select Store_name,sum(sales) from store_info group by Store_name order by sales;
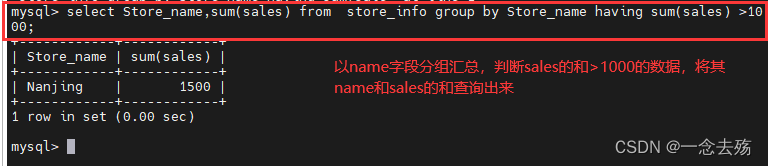
------------------having----------------------
having用来过滤由group by语句返回的记录值,通常与group by语句联合使用。having语句的存在弥补了where关键字不能与聚合函数联合使用的不足。
语法格式:select 字段1,sum(字段2) from 表名 group by 字段1 having (函数条件);
select Store_name,sum(sales) from store_info group by Store_name having sum(sales) >1000;
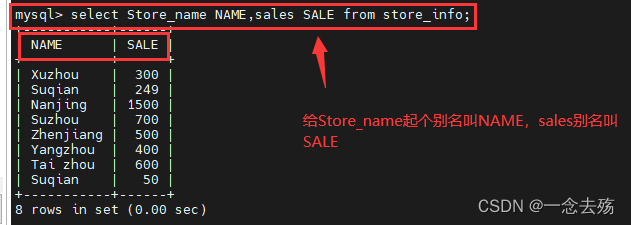
-------------------别名----------------------
别名包括字段别名和表的别名,当一张表的名字或者表中的某一个字段名过于冗长时,可以使用别名将之代替,从而降低查询的失误率。
语法格式:select 字段 [AS] 字段别名 from 表名 [AS] 表格别名;
select Store_name NAME,sales SALE from store_info;
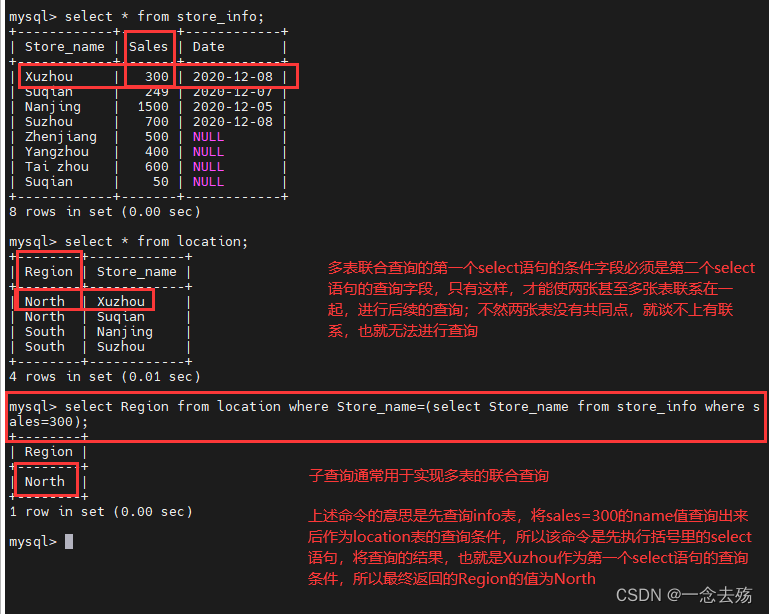
------------------子查询---------------------
子查询通常用于连接表格,在where子句或者having子句中插入另一个SQL语句。
语法格式:select 字段1 from 表格1 where 字段2 [比较运算符] (select 字段2 from 表格2 where 条件语句);括号里的select语句是内查询,括号外的select语句是外查询
select Region from location where Store_name=(select Store_name from store_info where sales=300); #比较运算符,可以是=、>、<或者>=、<=
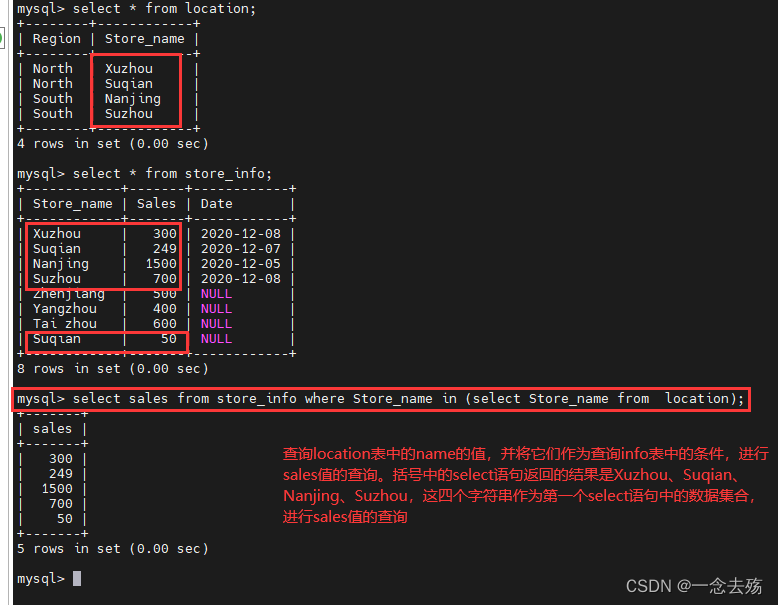
select sales from store_info where Store_name in (select Store_name from location); #也可以是in、between...and、like等


------------------exists---------------------
exists用来测试内查询有没有产生任何结果,类似布尔值
是否为真。如果内查询产生了结果,则将结果作为外查询
的条件继续执行,如果没有结果,那么整条语句都不会产
生结果。
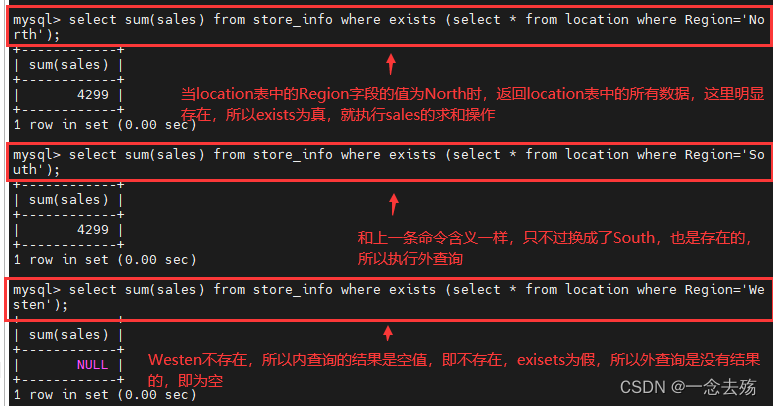
语法格式:select 字段1 from 表1 where exists (select 字段2 from 表2 where 条件语句);
select sum(sales) from store_info where exists (select * from location where Region='North'); #
#先执行内查询语句,即在location表中查询Region为North的所有数据,如果存在,则执行外查询语句;如果不存在,就不执行外查询
------------------连接查询-----------------------
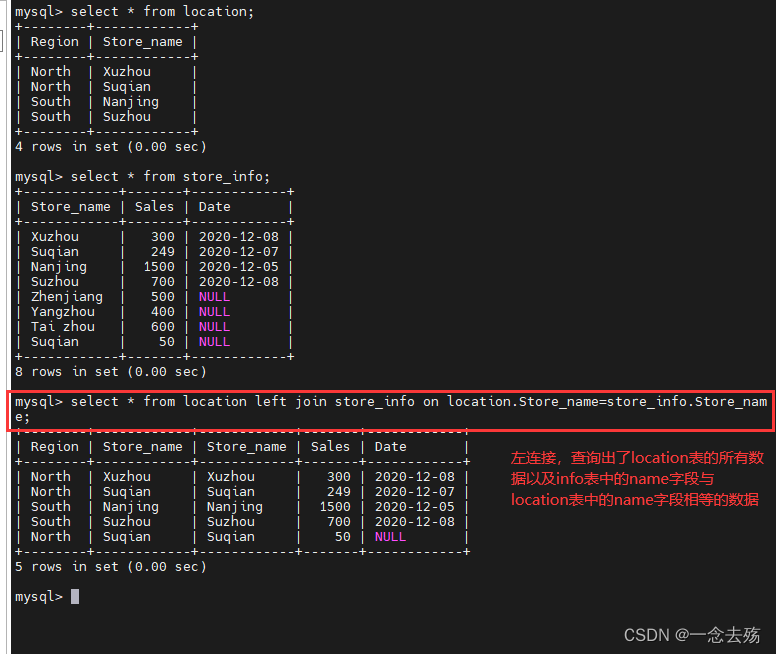
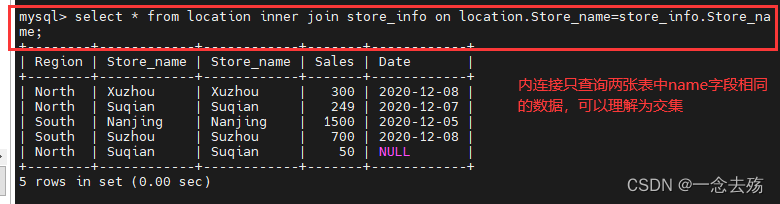
inner join(内连接):内连接只返回两个表中字段的值相等的数据,即两表的交集
left join(左连接):返回包括左表中的所有记录和右表中联结字段相等的记录
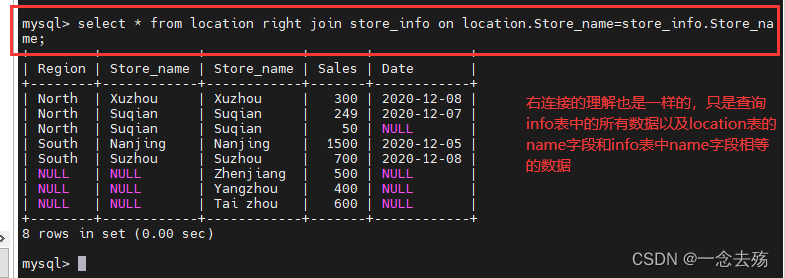
right join(右连接):返回包括右表中的所有记录和左表中联结字段相等的记录
select * from location left join store_info on location.Store_name=store_info.Store_name; #左连接
select * from location right join store_info on location.Store_name=store_info.Store_name; #右连接
select * from location inner join store_info on location.Store_name=store_info.Store_name; #内连接法1
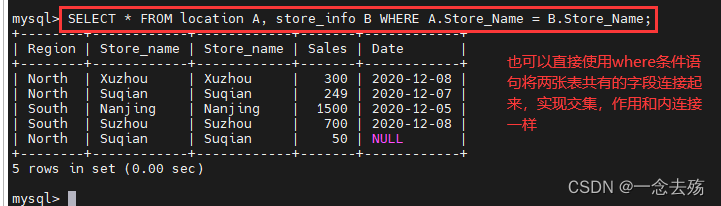
SELECT * FROM location A, store_info B WHERE A.Store_Name = B.Store_Name; #内连接法2
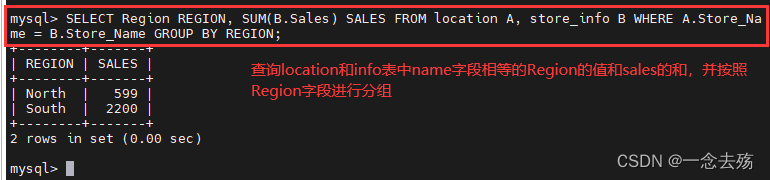
SELECT Region REGION, SUM(B.Sales) SALES FROM location A, store_info B WHERE A.Store_Name = B.Store_Name GROUP BY Region; #查询两表中name值相等的Region的值和sales的和,并按照Region字段进行分组,REGION是字段Region的别名,SALES是sum(sales)的别名,A是表location的别名,B是info表的别名
---------------------view-----------------------
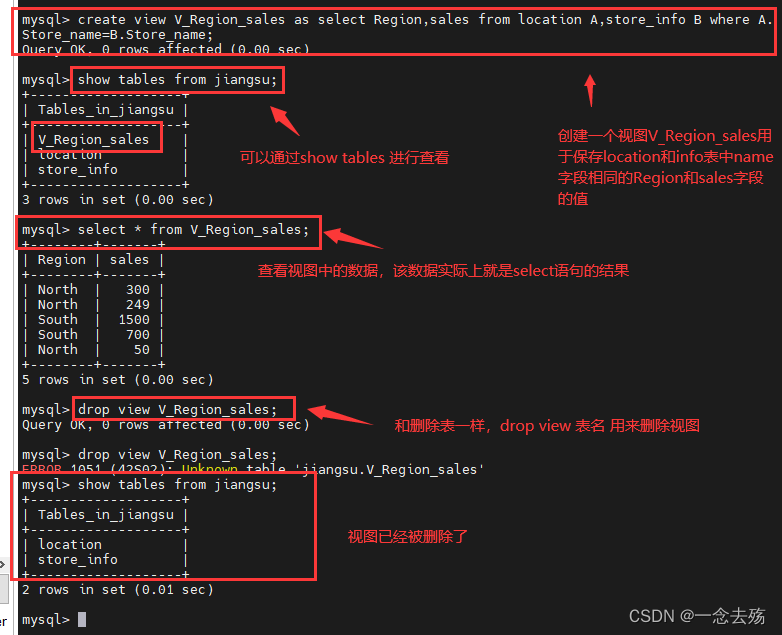
view,视图,视图是一张虚拟的表,通常用于保存多表联合查询出来数据,这样可以极大的减轻SQL语句的复杂度,在执行n张表的联合查询时,视图可以起到很大的便利作用。视图跟表格的不同是,表格中有实际储存数据记录,而视图是建立在表格之上的一个架构,它本身并不实际储存数据记录。而视图不会因为退出数据库而消失。
语法格式1:create view 视图名 as 查询语句; #创建视图
语法格式2:drop view 视图名; #删除视图
show tables from 库名; #该命令不仅可以查看库所包含的表,也可以查看有哪些视图
------------------------union-------------------------
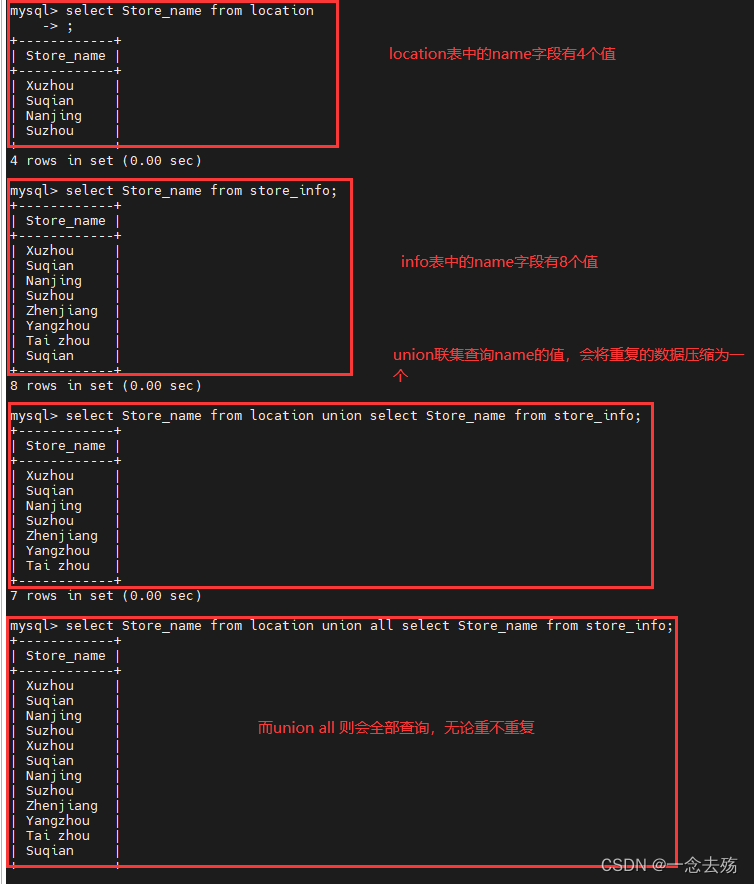
union,联集,其作用是将两个SQL语句的结果合并起来,两个SQL语句所产生的字段需要是同样的数据记录种类
union :生成结果的数据记录值将没有重复,且按照字段的顺序进行排序
union all :将生成结果的数据记录值都列出来,无论有无重复
语法格式:[select 语句 1] UNION [all] [SELECT 语句 2];
select Store_name from location union select Store_name from store_info;
select Store_name from location union all select Store_name from store_info;
-------------------求交集的几种方法------------------
存在重复数据:
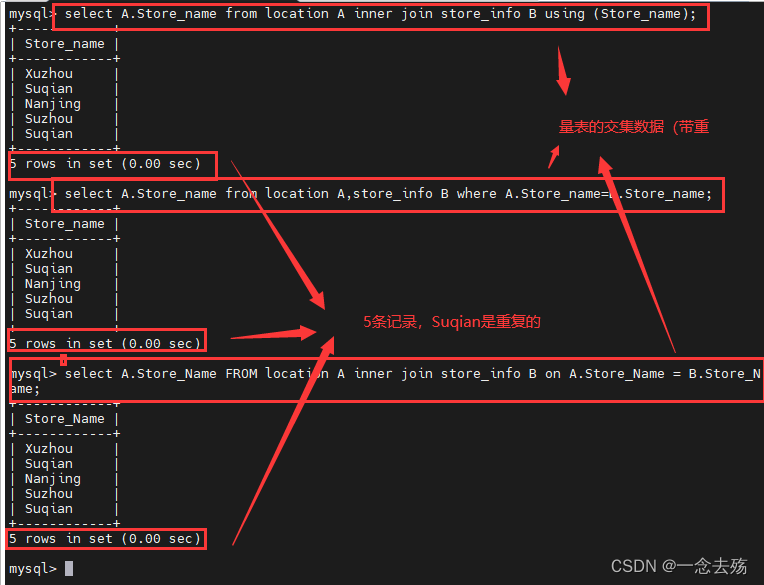
1.select A.Store_Name FROM location A inner join store_info B on A.Store_Name = B.Store_Name;
2.select A.Store_name from location A,store_info B where A.Store_name=B.Store_name;
3.select A.Store_name from location A inner join store_info B using (Store_name);
无重复数据:
1.想要得到无重复数据其实很简单,在重复数据的查询语句select后加上distinct去重即可。
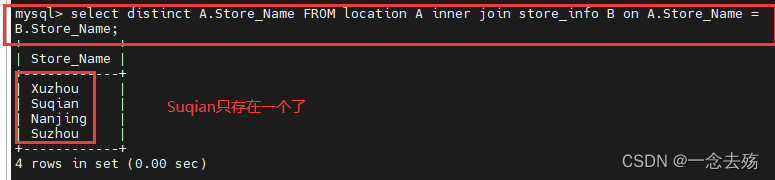
select distinct A.Store_Name FROM location A inner join store_info B on A.Store_Name = B.Store_Name;
2.使用子查询,在内查询中查询info中的name字段,并将之作为外查询的条件,这样,外查询的查询语句的范围就只能在内查询查出的数据中进行。(子查询实际上就是变相的内查询)
select distinct Store_name from location where Store_name in (select Store_name from store_info);
3.使用左查询,将location和info表进行左查询,会查询出location表中的所有name字段的值以及info表中与location表中name的值相等的数据,再使用distinct进行去重
select distinct A.Store_name from location A left join store_info B using(Store_name) where B.Store_name is not null;
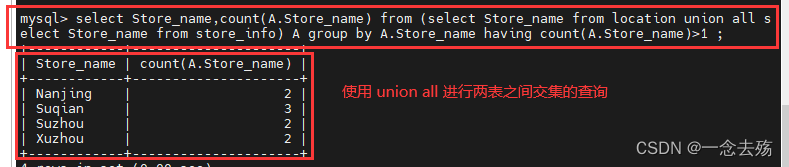
4.使用级联查询,union all会将两张表的所有数据都连接到一起,这时只需要通过count()函数将大于1的数值统计出来,即可实现查询两表的共同数值。
select Store_name,count(A.Store_name) from (select Store_name from location union all select Store_name from store_info) A group by A.Store_name having count(A.Store_name)>1 ;
---------------------无交集---------------------
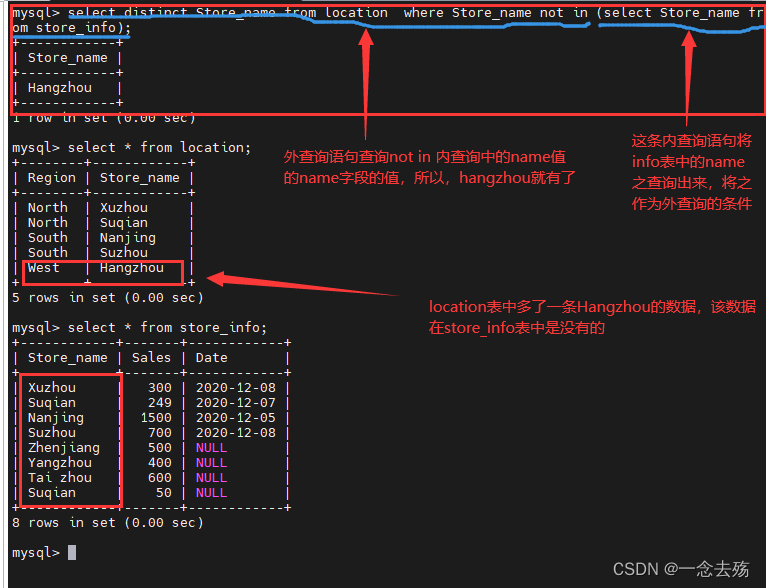
既然我们可以查询出有交集的数据,那么取反就可以实现无交集的查询了
select distinct Store_name from location where Store_name not in (select Store_name from store_info);
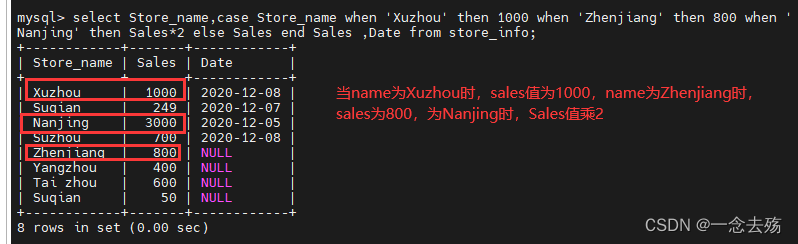
---------------------case---------------------
case是SQL语句用来做为when-then-else(当...就...否则...)之类逻辑的关键字
语法格式:
select case 字段名
when 条件1 then 结果1
when 条件2 then 条件2
.....
[else 结果n]
end
from 表名;
--------空值(NULL) 和 无值('') 的区别----------
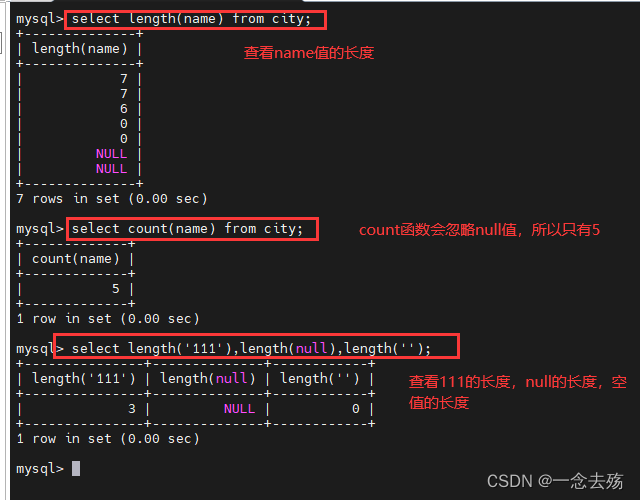
1.无值的长度为 0,不占用空间的;而 NULL 值的长度是 NULL,是占用空间的。
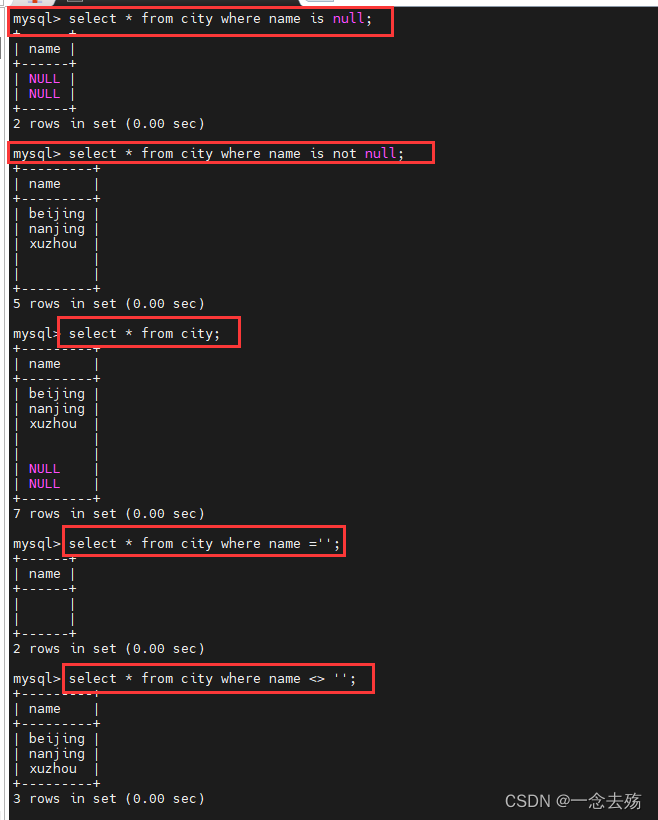
2.IS NULL 或者 IS NOT NULL,是用来判断字段是不是为 NULL 或者不是 NULL,不能查出是不是无值的。
3.无值的判断使用=''或者<>''来处理。<> 代表不等于。
4.在通过 count()指定字段统计有多少行数时,如果遇到 NULL 值会自动忽略掉,遇到无值会加入到记录中进行计算。
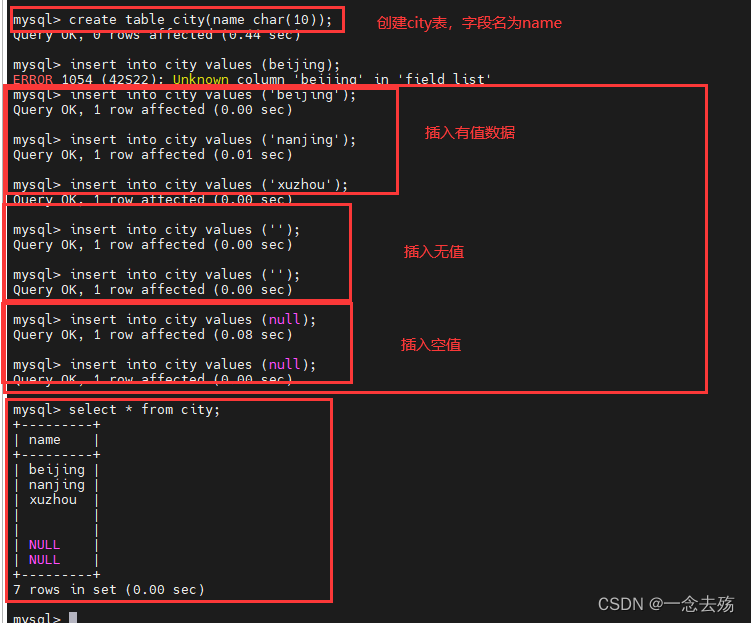
create table city(name char(10)); #新建city表
insert into city values ('beijing'); #插入三个值
insert into city values ('nanjing');
insert into city values ('xuzhou');
insert into city values (''); #插入两个无值
insert into city values ('');
insert into city values (null); #插入两个空值
insert into city values (null);
select * from city; #查询city表的所有值
select length(name) from city; #查询name字段值的长度
select count(name) from city; #统计name字段的值,空值会被忽略
select length('111'),length(null),length(''); #比较有值、空值、无值的长度
select * from city where name is null; #查询name为空的值
select * from city where name is not null; #查询name字段不为空的值
select * from city where name = ''; #查询name值为无值的数据
select * from city where name <> ''; #查询name字段不为无值的数据,空值会被忽略
--------------------正则表达式-------------------------
^:匹配文本的开始字符
$:匹配文本的结束字符
.:匹配任何一个字符
*:匹配零个或多个在它前面的字符
+:匹配前面的字符1次或多次
字符串:匹配包含指定的字符串
p1|p2:匹配p1或p2
[...]:匹配字符集合中的任意一个字符
[^...]:匹配不在括号中的任何字符
{n}:匹配前面的字符串 n 次
{n,m}:匹配前面的字符串至少n次,至多m次
语法格式:select 字段 from 表名 where 字段 REGEXP {模式};
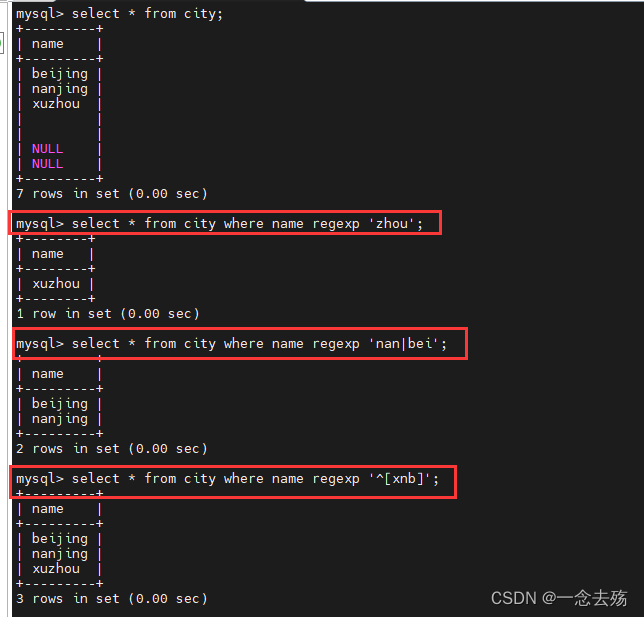
select * from city where name regexp 'zhou'; #匹配数据中带zhou的
select * from city where name regexp 'nan|bei'; #匹配数据中有nan或bei的
select * from city where name regexp '^[xnb]'; #匹配以xnb任一字符开头的数据
三、MySQL存储过程
存储过程是一组为了完成特定功能的SQL语句集合。
存储过程在使用过程中是将常用或者复杂的工作预先使用SQL语句写好并用一个指定的名称存储起来,这个过程经编译和优化后存储在数据库服务器中。当需要使用该存储过程时,只需要调用它即可。存储过程在执行上比传统SQL速度更快、执行效率更高。
存储过程的优点:
1、执行一次后,会将生成的二进制代码驻留缓冲区,提高执行效率
2、SQL语句加上控制语句的集合,灵活性高
3、在服务器端存储,客户端调用时,降低网络负载
4、可多次重复被调用,可随时修改,不影响客户端调用
5、可完成所有的数据库操作,也可控制数据库的信息访问权限
------------------创建存储过程-----------------------
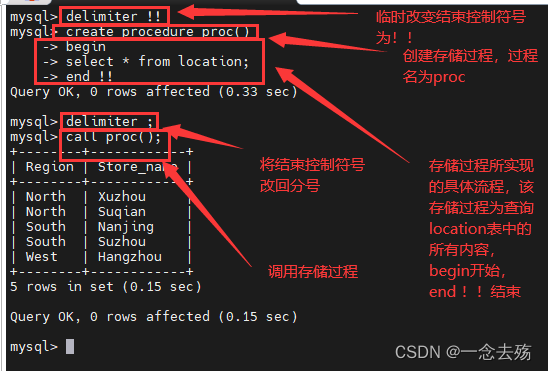
delimiter !! #将语句的结束符号从分号;临时改为两个!!(可以是自定义)
create procedure Proc() #创建存储过程,过程名为Proc,不带参数
-> begin #过程体以关键字 BEGIN 开始
-> select * from Store_Info; #过程体语句
-> end $$ #过程体以关键字 END 结束
delimiter ; #将语句的结束符号恢复为分号
------------------调用存储过程-----------------------------
call Proc;
------------------查看存储过程----------------------------
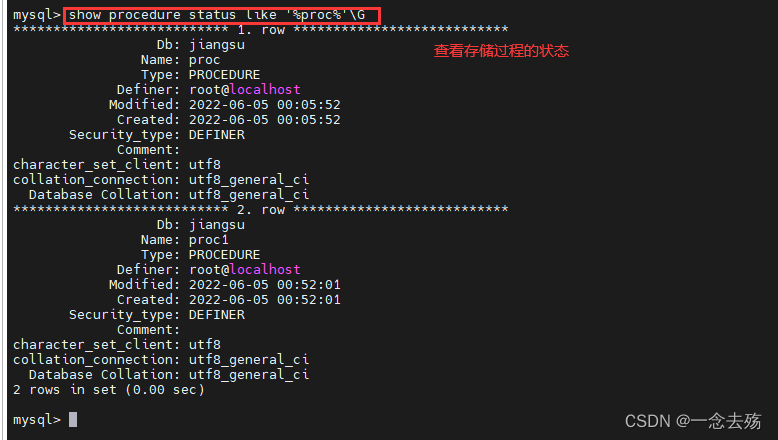
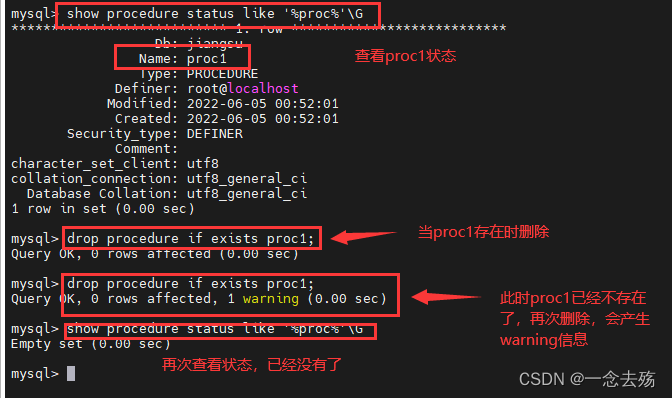
show create procrdure [数据库.]存储过程名; #查看某个存储过程的具体信息
show create procedure proc;
show procedure status [LIKE '%Proc%'] \G

----------------存储过程的参数--------------------
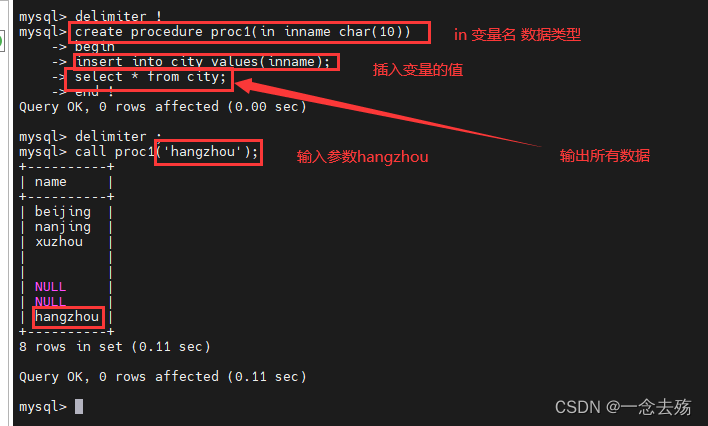
IN 输入参数:表示调用者向过程传入值(传入值可以是字面量或变量)
OUT 输出参数:表示过程向调用者传出值(可以返回多个值)(传出值只能是变量)
INOUT 输入输出参数:既表示调用者向过程传入值,又表示过程向调用者传出值(值只能是变量)
实例:
delimiter !
create procedure proc1(in inname char(10))
-> begin
-> insert into city values(inname);
-> select * from city;
-> end !
delimiter ;
call proc1('hangzhou');
------------------删除存储过程----------------------
存储过程内容的修改方法是通过删除原有存储过程,之后再以相同的名称创建新的存储过程。
drop procedure if exists 存储过程名; #仅当存在时删除,不添加if exists时,如果指定的过程不存在,则产生一个错误
##存储过程的控制语句##
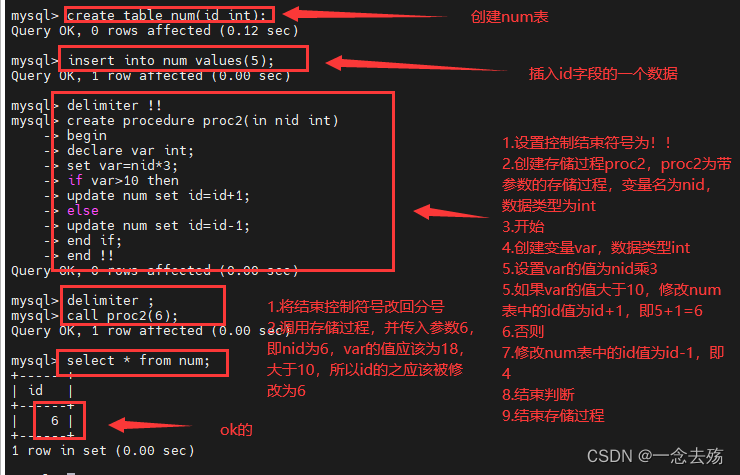
create table num (id int);
insert into num values(10);
(1)条件语句if...then...else ...end if
delimiter !!
create procedure proc2(in nid int)
-> begin
-> declare var int; #declare 变量名 数据类型 来创建一个变量
-> set var=nid*3; #设置变量的参数
-> if var>=10 then #if-else判断
-> update num set id=id+1;
-> else
-> update num set id=id-1;
-> end if; #结束判断
-> end !!
delimiter ;
call proc2(6);
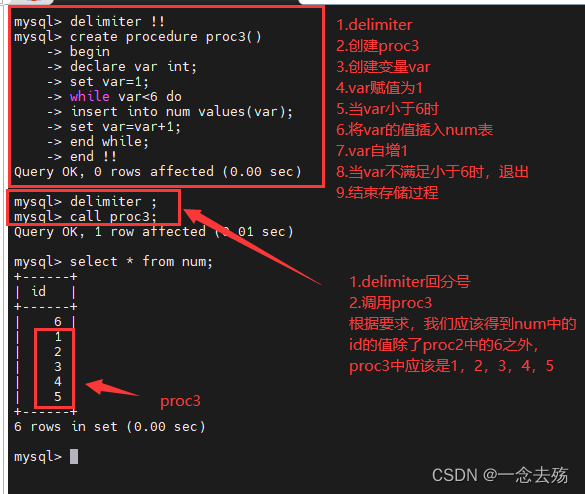
(2)循环语句while...do...end while #用法和if一样,while的话必须要给定义的变量自增的过程,否则会死循环,可以参考shell中的while语句
delimiter !!
create procedure proc3()
-> begin
-> declare var int(10);
-> set var=0;
-> while var<6 do
-> insert into num values(var);
-> set var=var+1;
-> end while;
-> end !!
delimiter ;
call proc3;
总结
- 各种函数的使用
- 多表查询时的字段所属的表
- 存储过程的整体流程
- 灵活运用所学知识,举一反三















 2651
2651











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











