







排队论模型
一般而言,排队问题相当常见,比如等待银行柜台服务、加油站加油或者多个进程等待cpu处理都会出现排队,为叙述方便,将排队者称为顾客,提供服务的一方称为服务员。常识都知道我们不希望排队(为了享受排队的另说),排队意味着是时间成本的消耗,如果是物资等待被处理的排队则说明物资出现积压,不管哪种都会对生产效率产生重要负面影响,但往往这个排队现象是无法完全消失的,这是一种随即现象,排队与很多因素相关,其中最重要的两部分是顾客到达时间间隔的随机时间和服务过程的随即时间两部分,而排队论的宗旨也是系统在不同场景下利用以上两种过程规律对实际的排队系统做出最优的决策以提高效益。

一般来说排队论是基于概率随机过程的理论建立起来的理论,最后才是系统的优化。
准备
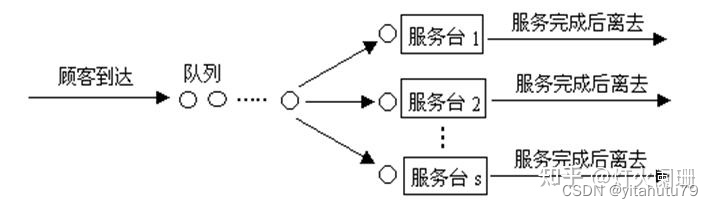
排队系统
一般包含顾客输入、排队规则、服务过程三部分。顾客的输入过程指的是顾客到来的时间规律性。
顾客可以是无限的,也不一定是一个一个按照时间间隔到达,且顾客间相互独立,互不影响
排队规则主要是顾客会按照什么样的规则排队,分为损失制,等待制和前两者的混合,损失制顾名思义是顾客到达时没有服务员了就立马离去,而等待制则是说明顾客愿意等待直到接受完服务后才离去。
服务过程可以简单理解为柜台分配规则和对顾客的处理规则,有时是单个服务台,有时有多个服务台并行出现,当然也有多个服务台串联(即顾客需要按顺序走完流程);而处理规则包括先到先服务(FIFO,最常见),后到先服务(比如砌墙用的砖头,先拿来用的一定是最后放上去的),随机服务,优先服务(比如重大患者优先)
符号约定
模型一般用六个符号表示,符号间用斜线隔开
![[公式]](https://i-blog.csdnimg.cn/blog_migrate/9d1a2d12bc25d68154cc9a71b0cb6728.png)
其中X代表顾客流到达时间间隔的概率分布,Y表示服务员服务时间的概率分布(常见概率分布见后),Z表示服务台个数,A表示系统容量限制,B表示顾客数目限制,C表示服务规则
表示顾客到达间隔时间和服务时间的分布的约定符号为:M为指数分布,D为确定型分布(即不依靠概率),
为k阶爱尔朗分布,G为一般服务时间的分布,GI为一般相互独立的时间间隔的分布
常用概率分布和过程
泊松分布过程

指数分布

爱尔朗分布

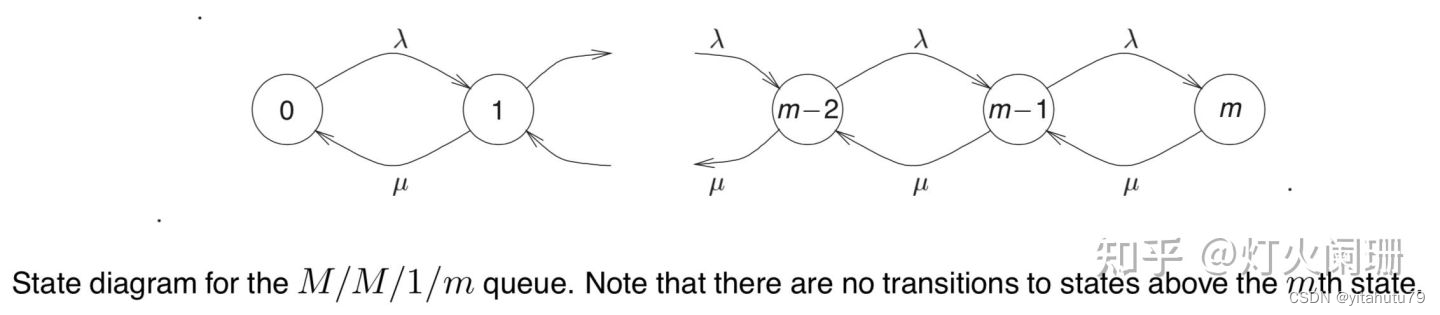
生灭过程


排队系统指标


常见的排队模型
M/M/S排队模型
该模型所在的系统满足:
(1) 顾客到达服从泊松分布
(2) 服务时间服从指数分布
(3) 并列的服务台数为S个,系统容量、顾客数限制为无穷,排队规则为先来先服务
S=1时为单服务台等待模型,S>1时为并列多服务台排队模型



小trick:一般来说采用一个M/M/2排队模型要比两个M/M/1排队模型的效果更好(即排队效益最好,等待时间少,等待队长短),这在经济学上是规模效益的说法
M/M/S/k排队模型

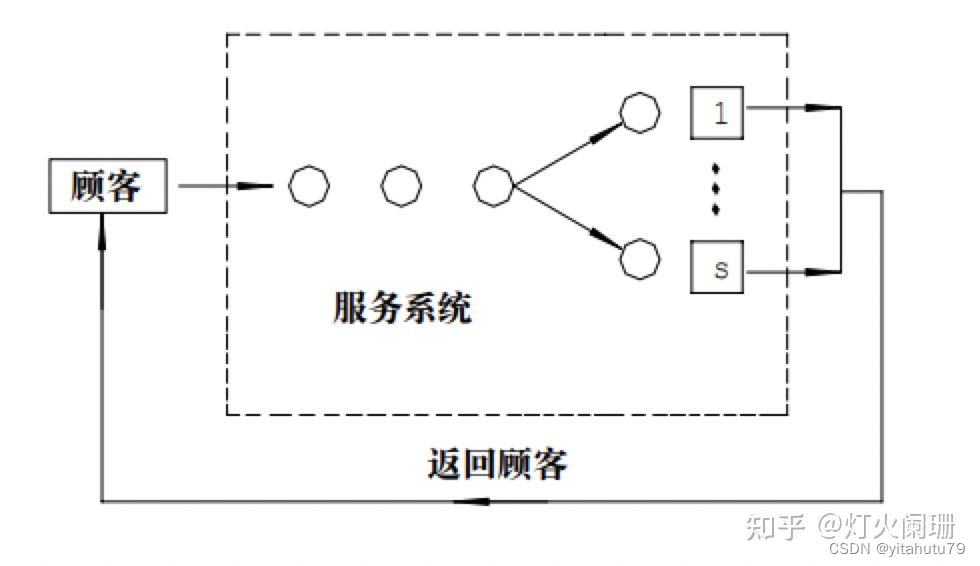
M/M/S/m/m模型
即此时顾客源为有限的m个,即如果系统有m个客户就不会再有新的顾客到达
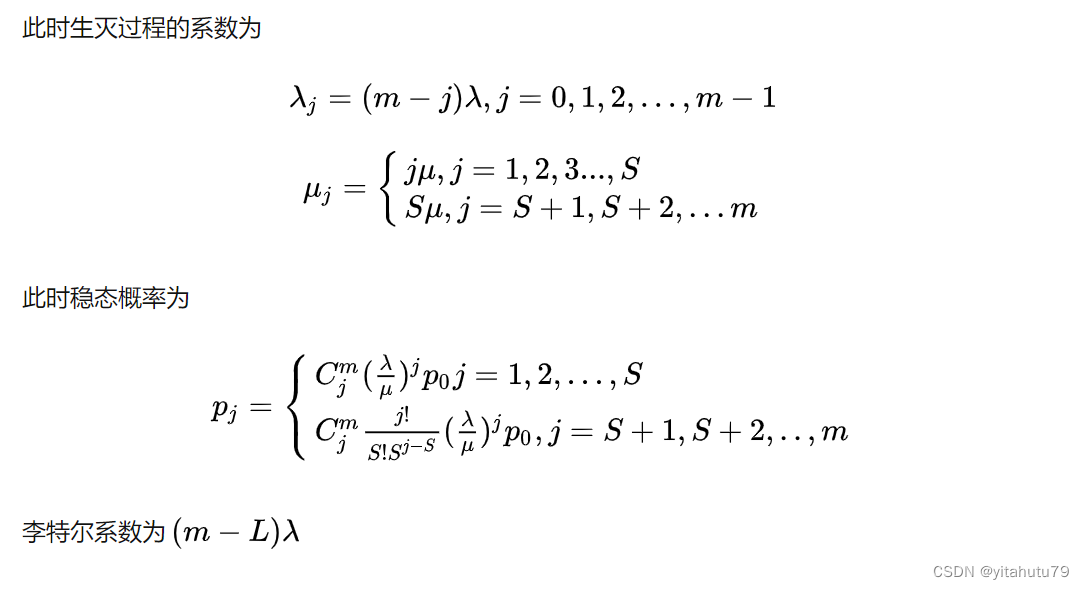
M/G/1排队模型

排队系统的优化




小技巧
当排队系统的到达间隔时间和服务时间的概率分布很复杂时,或不能用公式给出时,那么就不能用解析法求解,这就需用随机模拟法求解,其实核心要义就是如何生成F(X)为指定分布的随机变量X
1、反变换法
必须要求F(X)严格递增(这样才有反函数)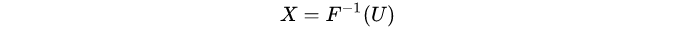 其中U为已知的分布
其中U为已知的分布
2、卷积法
若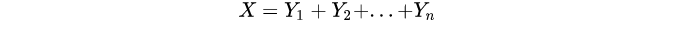
因为X很难直接求出,而Y相对容易,所以就是对他们做求和的卷积操作(概率论里面求Z = X+Y的分布函数的求法)


















 4509
4509

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











