







生成式模型和判别式模型
判别式模型是直接基于后验条件概率进行建模,而生成模型是对联合分布进行建模。
假设已有训练数据(X,Y),X是属性集合,Y是类别标记。
我们最终的目的是求得最大的条件概率P(y|x)作为样本的分类。只是两个模型做法不一样。
判别式模型
依据训练数据得到一个分类函数和分界面,比如使用SVM得到一个分界面,然后直接计算P(y|x),将最大的值作为x的分类类别,判别式模型不能反映数据本身特性,能力有限,只能告诉我们类别。
生成式模型
对每一个分类进行建模,有多少类别建多少模型。比如三个类{a,b,c},分别建立一个有关a,b,c的模型,然后对新的测试样本d,和每一个模型计算联合概率分布P(a,d),P(b,d),P(c,d),然后根据贝叶斯公式计算P(a|d),P(b|d),P(c|d),选一个最大的作为分类结果。
两者的联系
判别式模型可以由生成式模型生成,因为生成式模型线得到联合分布,再得到后验概率分布。可以得到更多的信息。
概率图模型
用图表达变量相关关系的概率模型。点代表随机变量(一个或一组),边代表变量的概率相关关系。
类别
有向无环图:有向图模型或贝叶斯网
- 隐马尔可夫模型(HMM)--时序数据建模--语音识别、NLP--生成式模型
无向图:无向图模型或马尔可夫网
- 马尔可夫随机场(MRF)--生成式模型
- 条件随机场(CRF)--判别式模型
隐马尔可夫模型(HMM)
两组变量
- 状态变量:又称隐变量,表示第i时刻系统状态,假设不可被观测。可在多个状态之间转换,有N个可能取值的离散空间
- 观察变量:表示第i时刻观察值,可离散可连续,以离散为例
组成HMM模型的条件
两个基本假设
- 齐次马尔科夫假设:状态变量之间遵循马尔可夫性;
- 观测独立性假设:观察变量只依赖于当前时刻的状态变量;
基于上述条件,所有变了联合分布为
三组参数
状态转移概率,记为矩阵
输出观测概率,记为矩阵
初始状态概率,记为
状态变量组成状态空间Y + 观测变量组成观测空间X + 三组参数 = HMM,参数表示为
给定参数,按下列步骤产生观测序列:
- t = 1,根据初始状态概率得到初始状态y1;
- 由yt和输出观测概率得到观测变量x1;
- 由yt和状态转移概率得到下一时刻状态yt+1;
- t<n,设置t = t + 1,转到第二步,否则终止;
HMM三个基本问题
- 如何评估模型和观测序列之间的匹配程度?
- 如何根据观测序列推测隐藏的模型状态?
- 如何训练模型使其更好的描述观测数据?

概率计算问题
直接计算方法
概念上可行,计算上不可行。列举所有的长度为T可能的状态序列,然后计算每一个状态序列与观察序列的联合概率,然后对所有可能的状态序列求和,得到P(O|).计算量大,是O(T
)阶的,算法不可行。
前向算法
前向概率
,给定HMM模型
,到时刻t部分观测序列为
,且状态为
的概率
观测序列概率的的前向算法
输入:HMM模型,观测序列O
输出:观测序列概率P(O|)
- 初值
- 递推 对t = 1,2,3,...,T-1,
- 终止
后向算法
后向概率
,给定HMM模型
,在时刻t状态为qi的条件下,从t+1到T的部分观测序列为
的概率为后向概率。
观测序列概率的的后向算法
输入:HMM模型,观测序列O
输出:观测序列概率P(O|)
- 对t = T-1,T-2,...,1,
综合前向概率和后向概率,
t = 1时等于前向概率,t = T-1时等于后向概率。
学习算法
根据训练数据是包括观测序列和对应状态序列,还是只有观测序列分为监督与非监督学习。
监督学习方法
假设已给训练数据包含S个长度相同的观测序列和对应的状态序列,使用极大似然估计来估计HMM的参数。
1、转移概率的估计
样本中时刻t处于状态i时刻t+1转移到状态j的频数为,状态转移概率
的估计是
2、观测概率的估计
样本中状态为j并观测为k的频数是,那么状态为j观测为k的概率
的估计是
3、初始状态概率的估计
为S个样本中初始状态为qi的概率。
由于监督学习需要使用训练数据,人工标注数据代价很大,所以需要非监督学习的算法。
非监督学习方法
Baum-Welch算法
给定只包含S个长度为T的观测序列,而没有对应的状态序列,目标学习HMM的参数。
将观测序列数据看作观测数据O,状态序列数据看作不可测的隐数据I,HMM模型实际上是一个含有因变量的概率模型
参数学习由EM算法实现。
输入:观测数据
输出:HMM参数
1、初始化
![]()
2、递推,对n=1,2,...,
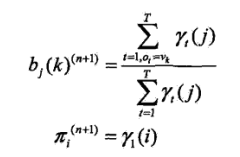
![]()
3、终止。![]()
预测算法
近似算法
维特比算法















 2608
2608











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









