



Linux 系统中安装 NVIDIA 显卡驱动 + 4090M 测评
linux安装显卡驱动
因为项目需要,买了一块4090M的外置显卡,来测试是否满足项目的需求。



第一部分:安装前的关键准备
1 确认显卡型号
lspci | grep -i nvidia
- 确定系统架构
uname -m # x86_64 表示64位系统
第二部分:Ubuntu/Debian 系
使用官方仓库安装(推荐)
# 添加官方PPA仓库
sudo add-apt-repository ppa:graphics-drivers/ppa
sudo apt update
# 查询可用驱动版本
ubuntu-drivers devices
# 自动安装推荐版本(通常标记为recommended)
sudo ubuntu-drivers autoinstall
# 或手动指定版本
sudo apt install nvidia-driver-580-open

如果下载缓慢的话可以换源。
删除残留下载文件的方法:
# 清理所有下载的软件包缓存(保留空目录)
sudo apt clean
# 可选:仅删除不再需要的缓存(如旧版本、未安装成功的包),保留已安装软件的包
sudo apt autoclean
# 列出缓存中NVIDIA相关的包(含.partial临时文件)
ls /var/cache/apt/archives/nvidia*
# 删除这些残留文件
sudo rm -rf /var/cache/apt/archives/nvidia*
然后重启,输入验证即可。
sudo reboot
nvidia-smi
nvidia-smi -L # 可以直接查看显卡型号


Anaconda+pytorch环境配置
uname-a # 查看内核

https://repo.anaconda.com/archive/

wget https://repo.anaconda.com/archive/Anaconda3-2024.10-1-Linux-x86_64.sh
./Anaconda3-5.3.0-Linux-x86_64.sh
开始安装,一直enter ,yes 直到安装完
点击enter,输入yes,点击enter,输入yes

配置Anaconda环境
# 打开/etc/profile
vim /etc/profile
# 在末尾添加环境变量
export PATH=~/anaconda3/bin:$PATH
# 打开 ~/.bashrc
vim ~/.bashrc
# 在末尾添加环境变量
export PATH=~/anaconda3/bin:$PATH
# 刷新环境变量
source /etc/profile
source ~/.bashrc
conda -V

conda create -n track python=3.10.18

安装pytorch
https://pytorch.org/get-started/previous-versions/
conda install pytorch==2.3.1 torchvision==0.18.1 torchaudio==2.3.1 pytorch-cuda=11.8 -c pytorch -c nvidia
# CUDA 11.8
pip install torch==2.3.1 torchvision==0.18.1 torchaudio==2.3.1 --index-url https://download.pytorch.org/whl/cu118


pip install opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple

安装vscode
sudo snap install code --classic
后续方案:

SAM2配置相关的问题
修改image_size,关于图像分辨率
由1024改为512,对应的feat_sizes: [64, 64]两个地方需要改成feat_sizes: [32, 32]
memory_attention:
_target_: sam2.modeling.memory_attention.MemoryAttention
d_model: 256
pos_enc_at_input: true
layer:
_target_: sam2.modeling.memory_attention.MemoryAttentionLayer
activation: relu
dim_feedforward: 2048
dropout: 0.1
pos_enc_at_attn: false
self_attention:
_target_: sam2.modeling.sam.transformer.RoPEAttention
rope_theta: 10000.0
feat_sizes: [32, 32] # 修改这里,64->32
embedding_dim: 256
num_heads: 1
downsample_rate: 1
dropout: 0.1
d_model: 256
pos_enc_at_cross_attn_keys: true
pos_enc_at_cross_attn_queries: false
cross_attention:
_target_: sam2.modeling.sam.transformer.RoPEAttention
rope_theta: 10000.0
feat_sizes: [32, 32] # 修改这里,64->32
rope_k_repeat: True
embedding_dim: 256
num_heads: 1
downsample_rate: 1
dropout: 0.1
kv_in_dim: 64
num_layers: 4
image_size: 512 # 修改这里, 1024->512
这样带来的结果就是:速度变快,不管是图像分割还是视频分割;缺点就是效果会相对应的变差(因为SAM2这个模型原始的训练图像大小就是1024*1024的)

另外,还需要修改一个地方才能正常使用。
SAM2ImagePredictor这个地方会出现问题:.view
feats = [
feat.permute(1, 2, 0).view(1, -1, *feat_size)
for feat, feat_size in zip(vision_feats[::-1], self._bb_feat_sizes[::-1])
][::-1]
self._bb_feat_sizes = [
(256, 256),
(128, 128),
(64, 64),
]
最简单的修改方法就是把上面的这个改为下面的这个
self._bb_feat_sizes = [
(128, 128),
(64, 64),
(32, 32),
]
或者增加一段代码:这样可以自动计算特征尺寸列表
# Spatial dim for backbone feature maps
hires_size = self.model.image_size // 4
self._bb_feat_sizes = [[hires_size // (2**k)]*2 for k in range(3)]
这样改虽然速度会获得提升,但是效果会变得很差,所以一般不推荐这样修改
推理速度太慢
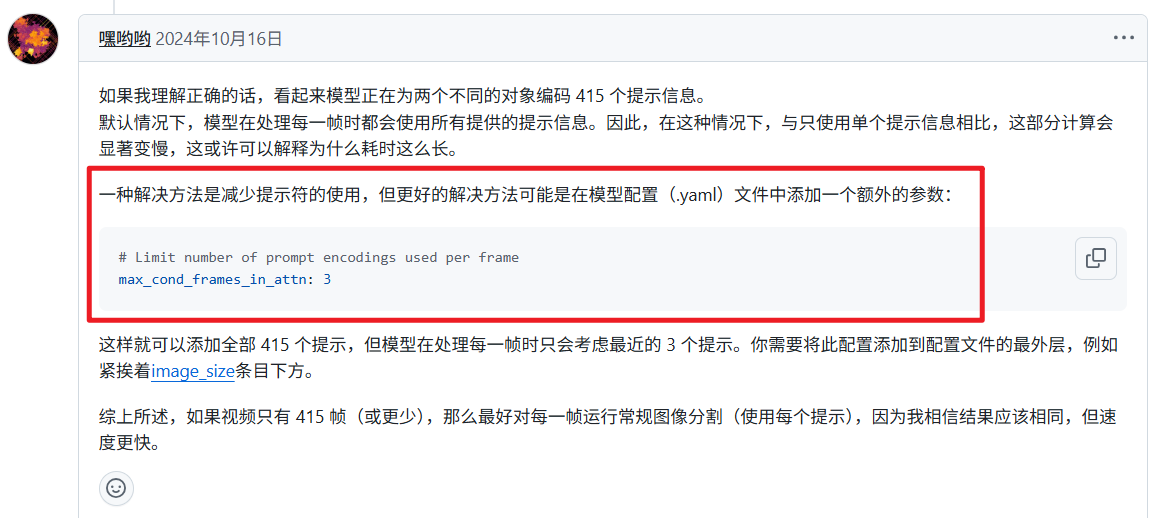
待测试。。。
如何推理更长的视频?或者说更长视频的支持
因为SAM2会同时将所有帧加载进来,后续是一帧一帧做的推理。所以前期这个将所有帧加载进来极其消耗内存。
现在这个方法并不能支持更长视频的支持,但是会一定程度上解决内存溢出的问题。
方法:将视频首先分割成单帧图像,保存在一个文件夹里,然后将视频帧的图像文件夹路径传给init_state函数即可。
# 提取视频帧
frames_path = self.extractVideoFrames(videoPath)
# 初始化推理状态
predictor = self.getPredictorVideo()
inference_state = predictor.init_state(video_path=frames_path)
分割成一帧一帧的图片:
def extractVideoFrames(self, videoPath):
"""
将视频分割成一帧一帧的图片,保存到与视频同一个文件夹下的frames文件夹中。
参数:
videoPath (str): 视频文件的路径
返回:
str: frames文件夹的路径
"""
self.log.debug(f'----------开始提取视频帧: {videoPath}----------')
# 获取视频所在的文件夹路径
video_dir = os.path.dirname(os.path.abspath(videoPath))
# 创建frames文件夹路径
frames_dir = os.path.join(video_dir, 'frames')
# 如果frames文件夹不存在,则创建
if not os.path.exists(frames_dir):
os.makedirs(frames_dir)
self.log.debug(f'创建frames文件夹: {frames_dir}')
# 打开视频文件
cap = cv2.VideoCapture(videoPath)
if not cap.isOpened():
self.log.error(f'无法打开视频文件: {videoPath}')
return frames_dir
frame_count = 0
saved_count = 0
try:
while True:
ret, frame = cap.read()
if not ret:
break
# 保存帧为图片,使用帧序号命名(例如: frame_0001.jpg)
frame_filename = os.path.join(frames_dir, f'{frame_count:06d}.jpg')
cv2.imwrite(frame_filename, frame)
saved_count += 1
frame_count += 1
# 每100帧打印一次进度
if frame_count % 100 == 0:
self.log.debug(f'已提取 {frame_count} 帧')
self.log.debug(f'----------视频帧提取完成,共提取 {saved_count} 帧,保存到: {frames_dir}----------')
except Exception as e:
self.log.error(f'提取视频帧时发生错误: {e}')
finally:
cap.release()
return frames_dir
测试效果 4090M
20s视频 511帧 3条线 181s 350ms/帧 8G显存左右
再多的话就会爆内存了,理论上16G内存的话最多支持40s 25帧的视频
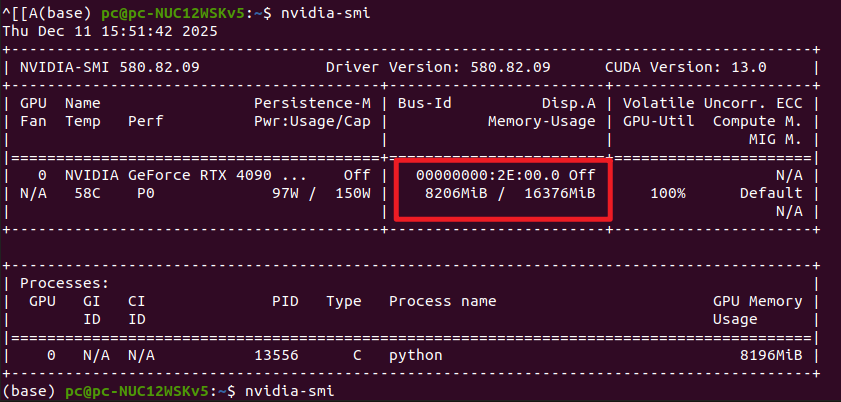
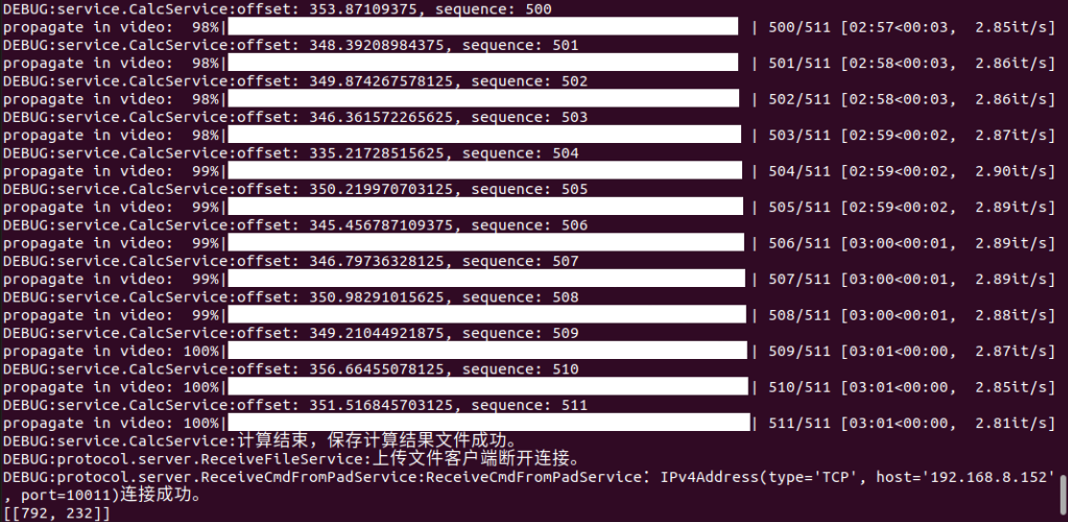

40s视频 1000帧 3条线(跟踪三个物体) 352s 352ms/帧 16G显存左右
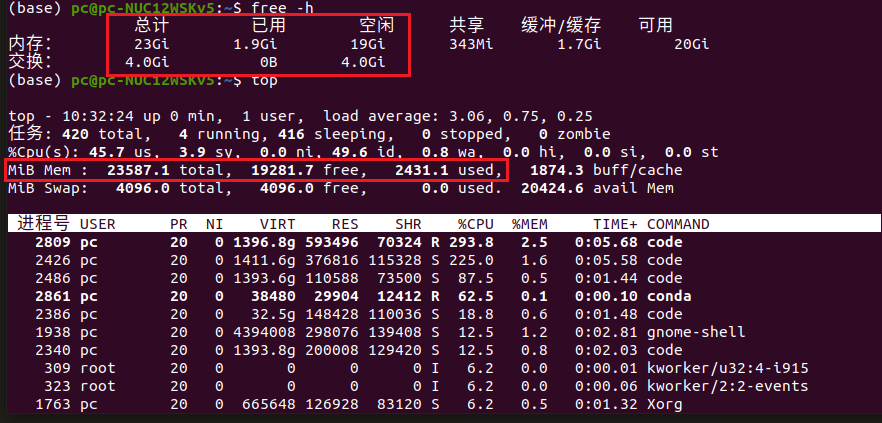
增加内存条,8G+16G=24G

1000帧图片推理,显存占用大概在16G左右,接近跑满
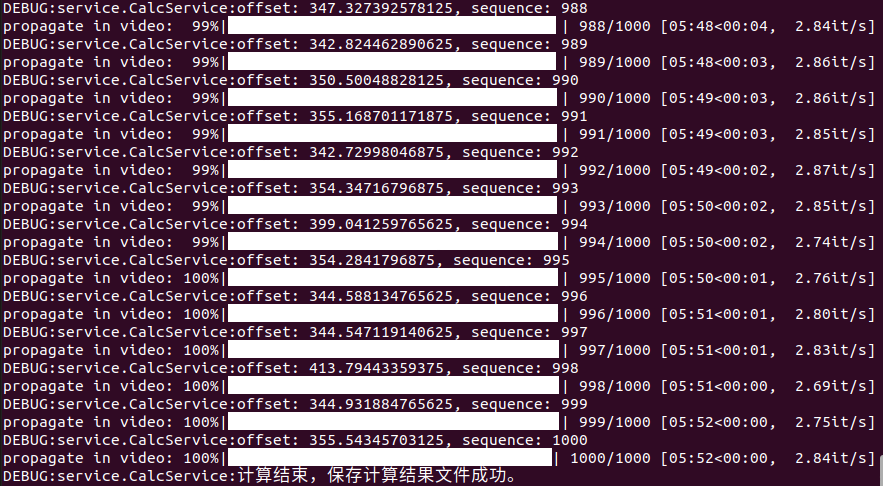
耗时5:52,也就是352s
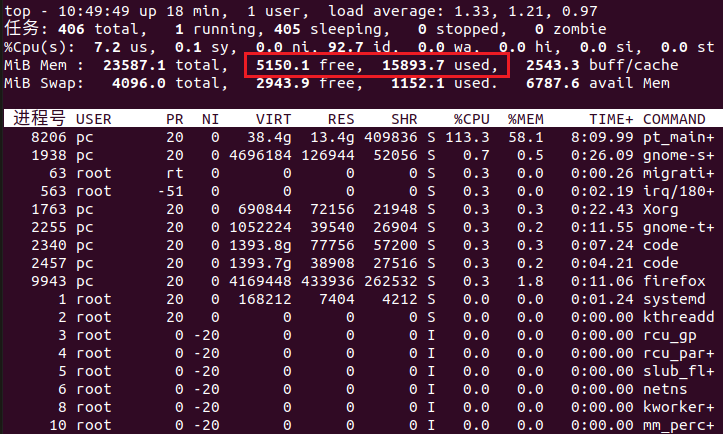
这是内存1000帧的时候的消耗,还剩下5G空闲

这是正常时候,还剩下17G空闲,也就是说1000帧的视频消耗掉了12G内存
测试效果 4080M
4080M相比4090M一帧推理慢100ms;16G内存对于500帧的视频是足够的。

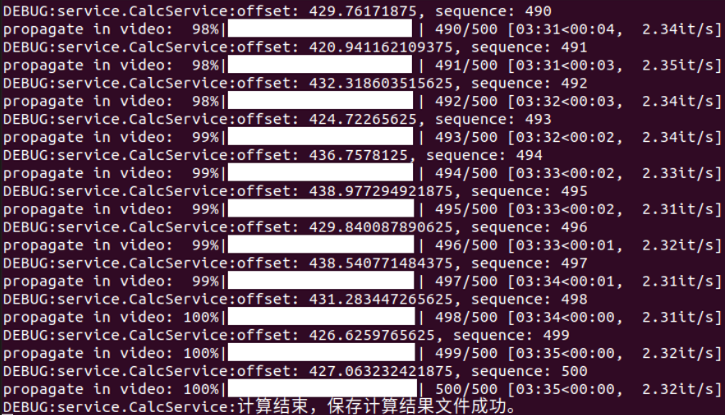
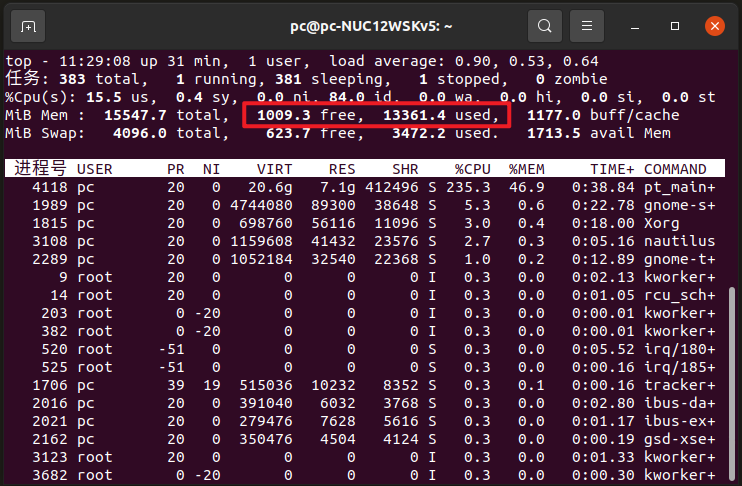

关于Swap交换空间,与SAM2关系不大
增大 Swap 交换空间的核心作用,是当物理内存被占满时,为系统和程序提供临时的 “内存兜底”,避免出现内存不足导致的程序崩溃或系统卡死


增大Swap交换空间的方法:
sudo swapoff /swapfile
sudo swapon --show # 查看启用的Swap文件
sudo fallocate -l 4G /swapfile
sudo chmod 600 /swapfile # 仅让 root 用户读写该文件,避免普通用户篡改
sudo mkswap /swapfile # 将新文件格式化为 Swap 格式
sudo swapon --show # 查看启用的Swap文件
sudo swapon /swapfile # 启用 Swap 文件
参考文章:
1 在Linux系统上安装NVIDIA显卡驱动的终极指南
2 在 Linux 系统中安装 NVIDIA 显卡驱动:详细指南
3 Linux安装Anaconda教程(2024最新)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









