







 本文介绍了如何在Python中处理unicode内存编码,包括str.encode()和bytes.decode()的用法,以及unicode-escape编码的应用。重点讲解了chardet库用于检测文件字符编码的实践,并提供了一个检测中文编码的案例。
本文介绍了如何在Python中处理unicode内存编码,包括str.encode()和bytes.decode()的用法,以及unicode-escape编码的应用。重点讲解了chardet库用于检测文件字符编码的实践,并提供了一个检测中文编码的案例。
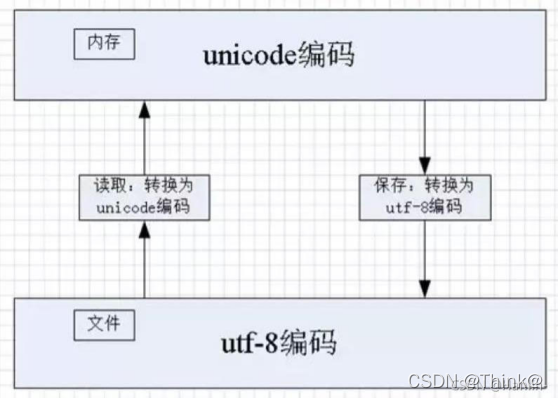
在Python中,unicode是内存编码集,将数据从内存存储到文件中时,需要先将数据编码为其他编码集,例如:UTF-8、GBK等。
首先:
1:str.encode():将字符串转换为其raw bytes形式。
2:bytes.decode():将raw bytes转换为字符串形式。
我们可以使用相同的编码集对一个数据进行编码解码。

unicode-escape也是一种编码集,这种编码集直接将unicode内存编码存储进文件。

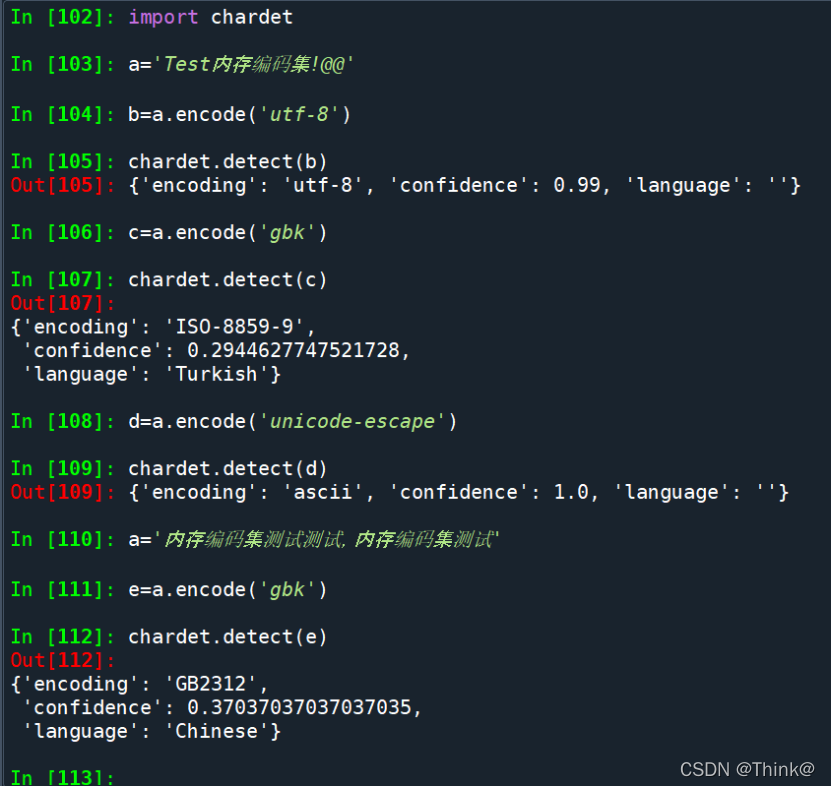
使用chardet.detect()可以对数据进行编码集检测,但是如果中文过少的话会不太准确。
可见:在Python中使用chardet检测文件字符编码方式_Hanlin的博客-CSDN博客_python检测文件编码方式
Reference:
https://www.cnblogs.com/leomei91/p/7685797.html


















 1142
1142

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











