







【自动驾驶】
[2024] EMMA: End-to-End Multimodal Model for Autonomous Driving
机构:Waymo
论文链接:https://arxiv.org/pdf/2410.23262v1
代码链接:
文中介绍了EMMA,这是一种端到端的多模态模型,用于自动驾驶。EMMA建立在多模态大语言模型的基础上,能够直接将原始摄像头传感器数据映射为多种与驾驶相关的输出,包括规划轨迹、感知物体和道路图元素。EMMA通过将所有非传感器输入(例如导航指令和自车状态)和输出(例如轨迹和三维位置)表示为自然语言文本,最大限度地利用了预训练大语言模型中的世界知识。这种方法使EMMA能够在统一的语言空间中共同处理各种驾驶任务,并使用特定任务的提示生成每个任务的输出。在实证上,通过在nuScenes数据集上实现最先进的运动规划性能,以及在Waymo开放运动数据集(WOMD)上取得具有竞争力的结果,展示了EMMA的有效性。EMMA在Waymo开放数据集(WOD)上的主要摄像头三维物体检测方面也表现出竞争力。与规划轨迹、物体检测和道路图任务共同训练EMMA可以在这三个领域实现改进,突显了EMMA作为自动驾驶应用通用模型的潜力。然而,EMMA也存在一些局限性:它只能处理少量图像帧,不支持像LiDAR或雷达这样的精确三维感知模式,并且计算成本较高。希望该研究结果能够激发进一步的研究,以减轻这些问题并推动自动驾驶模型架构的最新进展。


实验结果

可视化结果

【语义补全】
[ECCV 2024] Hierarchical Temporal Context Learning for Camera-based Semantic Scene Completion
机构:上交大、阿德莱德
论文链接:https://arxiv.org/pdf/2407.02077
代码链接:https://github.com/Arlo0o/HTCL
基于摄像头的三维语义场景补全(SSC)对于通过有限的二维图像观测预测复杂的三维布局至关重要。现有的主流解决方案通常通过粗略地堆叠历史帧来补充当前帧,从而利用时间信息,这种简单的时间建模不可避免地会减少有效线索并增加学习难度。为了解决这个问题,文中提出了HTCL,一种用于改进基于摄像头的语义场景补全的新颖的分层时间上下文学习范式。这项工作的主要创新在于将时间上下文学习分解为两个分层步骤:(a)跨帧亲和度测量和(b)基于亲和度的动态细化。首先,为了从冗余信息中分离出关键相关上下文,作者引入了具有尺度感知隔离和多个独立学习者的模式亲和度,用于细粒度的上下文对应建模。随后,为了动态补偿不完全观测,在初始识别的高亲和度位置及其相邻相关区域的基础上自适应地细化特征采样位置。该方法在SemanticKITTI基准测试中排名第一,甚至在OpenOccupancy基准测试上的mIoU方面超过了基于激光雷达的方法。


实验结果

【医学图像】
[TMI 2024 图像配准] UTSRMorph: A Unified Transformer and Superresolution Network for Unsupervised Medical Image Registration
论文链接:https://arxiv.org/pdf/2410.20348
代码链接:https://github.com/Runshi-Zhang/UTSRMorph
复杂的图像配准是医学图像分析中的一个关键问题,基于深度学习的方法已经取得了比传统方法更好的结果。这些方法包括基于卷积神经网络(ConvNet)和基于Transformer的方法。尽管ConvNets可以通过小范围邻域卷积有效利用局部信息来减少冗余,但受限的感受野导致其无法捕捉全局依赖关系。Transformers可以通过自注意力机制建立远距离依赖关系,然而,对所有标记token之间的关系进行密集计算会导致高冗余度。文中提出了一种名为统一Transformer和超分辨率(UTSRMorph)网络的新型无监督图像配准方法,该方法可以在编码器中增强特征表示学习,并在解码器中生成详细的位移场以克服这些问题。首先提出了一种融合注意力块,整合了ConvNets和Transformers的优点,将一个基于ConvNet的通道注意力模块插入多头自注意力模块中。重叠注意力块,一种新颖的交叉注意力方法,使用重叠窗口获取一对图像匹配信息的丰富相关性。然后,这些块被灵活地堆叠成一个新的强大编码器。从低分辨率特征生成高分辨率变形位移场的解码过程被视为一个超分辨率过程。具体来说,采用超分辨率模块代替插值上采样,可以克服特征退化问题。UTSRMorph与最先进的配准方法在3D脑磁共振成像(OASIS, IXI)和MR-CT数据集上进行了比较。定性和定量结果表明,UTSRMorph实现了相对更好的性能。

实验结果

[2024 医学图像分割] MLLA-UNet: Mamba-like Linear Attention in an Efficient U-Shape Model for Medical Image Segmentation
论文链接:https://arxiv.org/pdf/2410.23738
代码链接:https://github.com/csyfjiang/MLLA-UNet
最近的医学成像技术进步带来了更复杂和多样化的图像,面临如高解剖变异性、组织边界模糊、器官对比度低和噪声等挑战。传统的分割方法难以应对这些挑战,使得深度学习方法,特别是U形架构,越来越受到重视。然而,标准自注意力的二次复杂度使得Transformer在处理高分辨率图像时计算成本过高。为了解决这些挑战,文中提出了MLLA-UNet(Mamba-Like Linear Attention UNet),这是一个新颖的架构,通过其创新的线性注意力和受Mamba启发的自适应机制的结合,实现了线性计算复杂度,同时保持高分割精度,并辅以高效的对称采样结构来增强特征处理。所提架构有效地保留了必要的空间特征,同时以较低的计算复杂度捕捉长距离依赖关系。此外,还引入了一种新颖的多尺度特征融合的采样策略。实验表明,MLLA-UNet在六个具有挑战性的数据集上实现了最先进的性能,包括24个不同的分割任务,如FLARE22、AMOS CT和ACDC,平均DSC为88.32%。这些结果强调了MLLA-UNet相对于现有方法的优越性。作者的贡献包括这个新颖的2D分割架构及其经验验证。

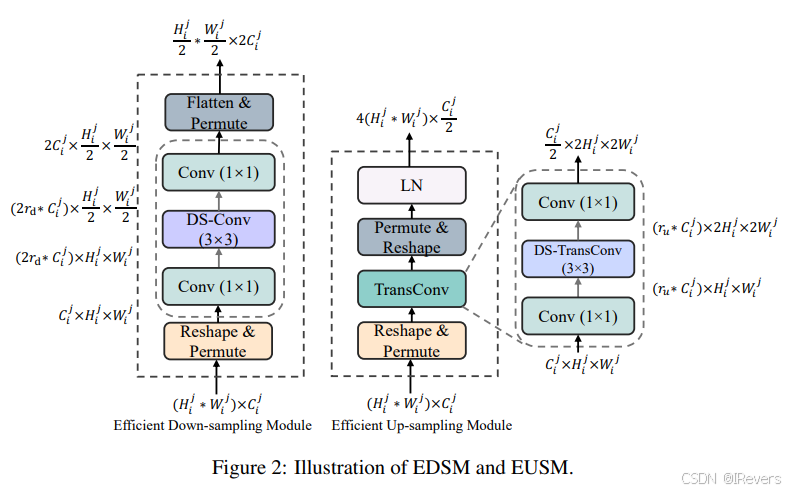
实验结果





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











