







【数据增强】
[2024] A Survey on Mixup Augmentations and Beyond
论文链接:https://arxiv.org/pdf/2409.05202
代码链接:https://github.com/Westlake-AI/Awesome-Mixup
在过去的十年里,随着深度神经网络取得了令人兴奋的突破,数据增强技术在无法获得大量标记数据的情况下,作为正则化技术获得了越来越多的关注。在现有的增强技术中,Mixup及相关的数据混合方法因其通过生成依赖数据的虚拟数据而产生高性能,且易于迁移到各种领域而广泛应用。这些方法凸性地组合选定的样本及其对应的标签。本综述全面回顾了基础Mixup方法及其应用。首先详细阐述了包含Mixup增强的训练pipeline作为一个统一的框架模块。重新构建的框架可以包含各种Mixup方法,并提供直观的操作步骤。然后,系统地研究了Mixup增强在视觉下游任务、各种数据模态中的应用,以及一些关于Mixup的分析与定理。同时,文中总结了当前Mixup研究的现状和局限性,并指出进一步的工作以实现有效和高效的Mixup增强。本综述可以为研究人员提供Mixup方法的最新现状,并在Mixup领域中提供一些见解和指导作用。



实验结果

【大语言模型】
[ECCV 2024] SAM4MLLM: Enhance Multi-Modal Large Language Model for Referring Expression Segmentation
论文链接:https://arxiv.org/pdf/2409.10542
代码链接:无
文中介绍了SAM4MLLM,这是一种创新方法,它将Segment Anything Model(SAM)与多模态大型语言模型(MLLMs)集成,用于像素感知任务。该方法使MLLMs能够在不需要对现有模型架构进行过多修改或添加专用标记的情况下学习像素级位置信息。作者引入了一种基于查询的方法,该方法能够有效地找到提示点,让SAM基于MLLM执行分割。它在无需额外计算开销的情况下,将详细的视觉信息与大型语言模型的强大表达能力结合起来,以统一的语言方式进行学习。在公共基准测试上的实验结果表明了该方法的有效性。



【人脸识别】
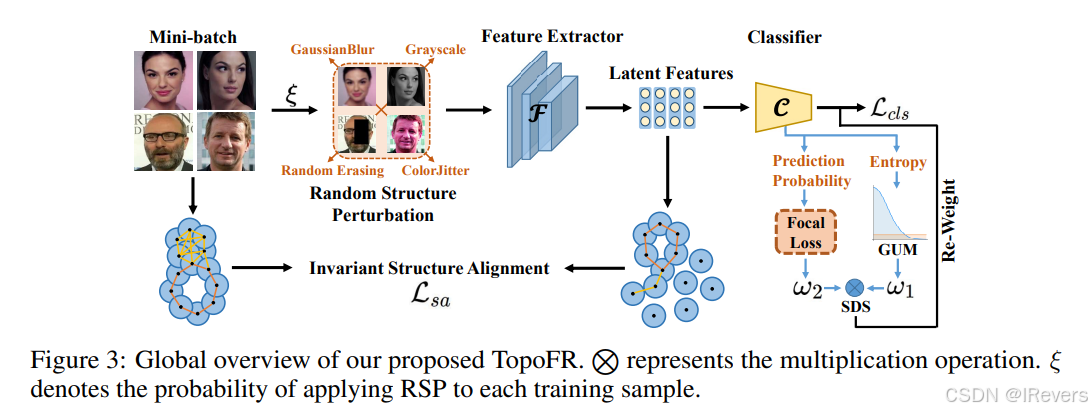
[NeurIPS 2024] TopoFR: A Closer Look at Topology Alignment on Face Recognition
论文链接:https://arxiv.org/pdf/2410.10587
代码链接:https://github.com/modelscope/facechain/tree/main/face_module/TopoFR
人脸识别(FR)领域随着深度学习的兴起取得了显著进展。最近,无监督学习和图神经网络的成功展示了数据结构信息的有效性。考虑到FR任务可以利用大规模训练数据,这些数据内在地包含重要的结构信息,文中旨在研究如何将这些关键结构信息编码到潜在空间中。从作者的观察中发现,直接对齐输入和潜在空间之间的结构信息不可避免地会遇到过拟合问题,导致潜在空间的结构崩溃现象。为了解决这个问题,作者提出了TopoFR,一种新颖的FR模型,它利用了一种称为PTSA的拓扑结构对齐策略和一种名为SDE的难样本挖掘策略。具体来说,PTSA使用持久同调来对齐输入和潜在空间的拓扑结构,有效地保留了结构信息,并提高了FR模型的泛化性能。为了减轻难样本对潜在空间结构的影响,SDE通过自动计算每个样本的结构损伤分数(SDS)准确识别难样本,并指导模型优先优化这些样本。在流行的面部基准测试上的实验结果表明,TopoFR优于最先进的方法。
实验结果





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











