







索引类型
1、普通索引
普通索引查出出来的是主键值,然后再到主键索引去查找对应的值

聚集索引是索引跟数据放在一起(Innodb),非聚集索引是数据跟索引分开的(MyIsam)
聚合会比较快
B+树的索引数据结构,也有hash索引的数据结构
B树与B+树最大的区别是 B树在跟和叶子节点都会存储数据 B+树在叶子节点才存储数据

possible_key 可能用到的索引
key 实际用到的索引

设置ID为主键 为什么要自增
尽量减少页合并和页分裂,在于维护索引
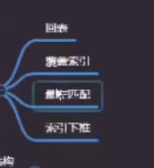
问题:查找name=张三的age
1、回表
普通的索引去找到name=张三一个id,然后再去到主键的索引表去找到对应的值就叫回表(回到主键的B+树查找) 先通过name查到主键id 再到主键索引的B+树进行数据查找
如果没有主键,数据库会自己创建主键去维护这个表的索引
2、覆盖索引
例子1,select * from table1 where name = 'zhangsan' 会 “回表” 操作 才能查出其他字段
例子2,select id from table1 where name = 'zhangsan' 不用 回表 查 “覆盖索引” 直接查到ID不用回表查,这个不需要的过程就叫覆盖索引
3、最左匹配原则
例如表 id,name,age,gender
例如 多数使用 name,age 进行查找
例如 索引是 name,age 组合索引
最左匹配原则 必须从左到右挨个匹配
1、select * from t1 where name = 'zhangsan' 可以使用
2、seletc * from t1 where name = 'zhangsan' and age = 10 可以使用
3、seletc * from t1 where age = 10 不能用 跨过了name 例如写地址 不写省市 直接写区就找不到
4、seletc * from t1 where age = 10 and name = 'zhangsan' 可以用,由优化器帮我们修改执行顺序

explain 也可以查看表关联的执行顺序
4、索引下推-->只有组合索引才有
谓词下推
select t1.name,t2.name from t1 join t2 on t1.id = t2.id
假设的执行方式
1、把索引的字段先做表关联,再从关联好的表中选择出需要的4个字段
2、先把两张表需要的4个字段取出,再做表关联 --->谓词下推
索引下推:
例如组合索引 name,age
没有优化的查询步骤:
1、先根据name列从存储引擎中把符合规则的数据拉取到mysql的server层
2、再server层按age进行数据过滤
索引下推的操作方式 新版本 5.6 以上才有
1、直接从存储引擎拉去数据的时候直接按照name和age做判断,将符合的结果返回给mysql server
5、索引匹配机制

1、全值匹配:跟所有字段值匹配上之后才有对应数据
例子:select * from table1 where name='zhangsan' and age = 10
2、匹配最左前缀:匹配的时候只匹配到前面几列
例子:
select * from table1 where name='zhangsan' and age = 10
select * from table1 where name='zhangsan'
3、匹配列前缀:使用like的时候 %****不会 ****%会 前面带% 就不会启动索引
例子:
select * from table1 where name like '%zhangsan' 不会用索引
select * from table1 where name like 'zhangsan%' 会匹配到zhangsan
4、匹配范围值:因为mysql是B+树的 索引可以
例子:
select * from table1 where age > 10 --但是只能执行一次
5、精确匹配到某一列并范围匹配另外一列
例子:
name = ‘zhangsan’ 是全部
再去查到 age > 10 的部分
select * from table1 where name = ‘zhangsan’and age > 10 这样才可以走索引
select * from table1 where age > 10 and name = 'zhangsan' age会走查询 但是name不会走查询
6、只访问索引的查询 就是 select 出的值 跟索引匹配 不需要访问数据行,本质上是覆盖索引
例子:
select name,age from table where name='zhangsan' and age = 10
6、索引优化

1、组合索引
字段name,age
问题:以下sql都要用到索引
1、select * from t1 where name = 'zhangsan'
2、seletc * from t1 where name = 'zhangsan' and age = 10
3、seletc * from t1 where age = 10
4、seletc * from t1 where age = 10 and name = 'zhangsan'
第一种
创建 name,age 组合索引
创建 age 索引 可以满足
第二种
创建 age,name 组合索引
创建name 索引
第一种与第二种的区别,创建name,age 或者 age,name 存储差不多 但是age 比 name 小,索引第一种比较好,要考虑存储大小
2、聚簇索引和非聚簇索引
1、聚簇索引
不是单独的索引类型,是一直数据存储方式,指的是数据行跟相邻的键值紧凑在一起 innodb
数据跟索引是放在一起的 ibd
2、非聚簇所有
值得是索引文件跟数据文件分开放 myisam
MYD(数据) 跟 MYI(索引) 分开存储

3、优化细节
1、尽量使用主键查询,而不是其他查询,因为主键查询不会回表
2、使用前缀索引
3、union all,in,or都可以用索引 但是推荐用 in


前缀咧索引写法
搜索相同城市的值 left (city,3) city字段存的字符串的前三个字符串的值
select count(*) as cnt ,left(city,8) as name form table group by pref order by cnt desc limit 10

范围列
可以使用 < <= > >= between 会触发索引 但是 后续的字段不会触发索引,索引最多只能使用一个范围索引

强制类型转换会全表扫描
select * form user where phone = 123 phone 本身是varchar的 强制转为int 会全表扫描随意不会触发索引
select * form user where phone ='123' 会触发索引
表结构如下
![]()

测试


查看两次结果


4、连表的时候必须保存数据类型一致
5、单个表索引控制在5个以内
6、单索引字段最好不用超过5个(组合索引)
简述聚集索引和稀疏索引
聚集索引按每张表的主键构建一棵B+树,数据库中的每个搜索键值都有一个索引记录,每个数据页通过双向链表连接。表数据访问更快,但表更新代价高。(索引跟数据放在一起,找到key就等于找到数据)
稀疏索引不会为每个搜索关键字创建索引记录。搜索过程需要,我们首先按索引记录进行操作,并按顺序搜索,直到找到所需的数据为止。(索引跟数据是分开的)(查询较慢,因为先差了索引表对应的key 然后再用key去数据表找到对应的值)
为什么数据库不用红黑树用B+树
红黑树的出度为 2,而 B Tree 的出度一般都非常大。红黑树的树高 h 很明显比 B Tree 大非常多,IO次数很多,导致会比较慢,因此检索的次数也就更多。
B+Tree 相比于 B-Tree 更适合外存索引,拥有更大的出度,IO次数较少,检索效率会更高。















 455
455











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









