










 本文记录了一个数据爱好者使用MATLAB的BP神经网络预测七星彩彩票号码的过程,从数据爬取、预处理到模型训练,最终发现彩票号码分布均匀,难以预测。文章强调了努力奋斗的重要性。
本文记录了一个数据爱好者使用MATLAB的BP神经网络预测七星彩彩票号码的过程,从数据爬取、预处理到模型训练,最终发现彩票号码分布均匀,难以预测。文章强调了努力奋斗的重要性。
每一个穷人都有一个发财的梦想。
于是彩票这个东西,诞生了。
随之而来
各种预测方式···千奇百怪
十二生肖说,星座说,图象说,等等
今天,我摸了摸干瘪的口袋,怀揣着一颗求富的心,试着抓取了2004年到2018年所有的七星彩数据。
最后,用MATLAB最简单的BP神经网络(SGD),进行了预测。
结果

嘿嘿嘿,让我先放几张图片讲讲过程,等会儿再说结果。
为了大家的阅读体验,先放图片。
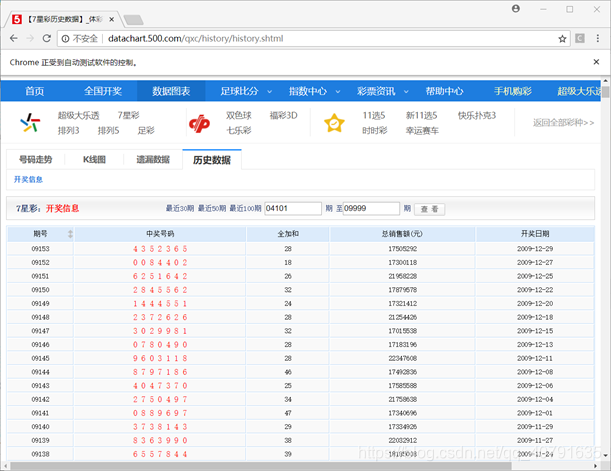
这是我想爬取的页面:
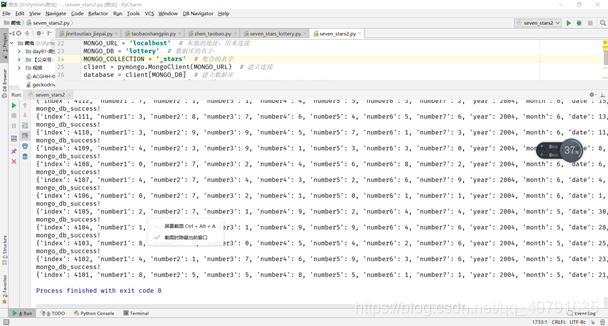
然后我把昨天的程序稍微改了改:
爬取了2178个数据!把这个网站从2004年开始到现在所有储存的七星彩数据全部抓了下来。
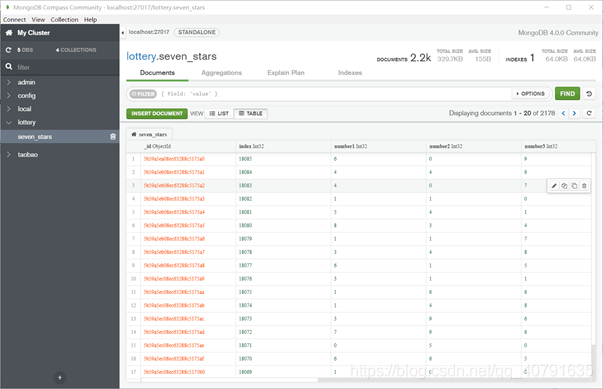
保存在了平易近人的mongoDB数据库里:
(非关系型数据库真好用啊,数据库老师对不住了,那些关系型数据库的select语句快忘完了)
之后把数据库的文件作为.CSV格式导出来。再用MATLAB打开
嘿嘿嘿,心中感觉离大奖又近了一步。
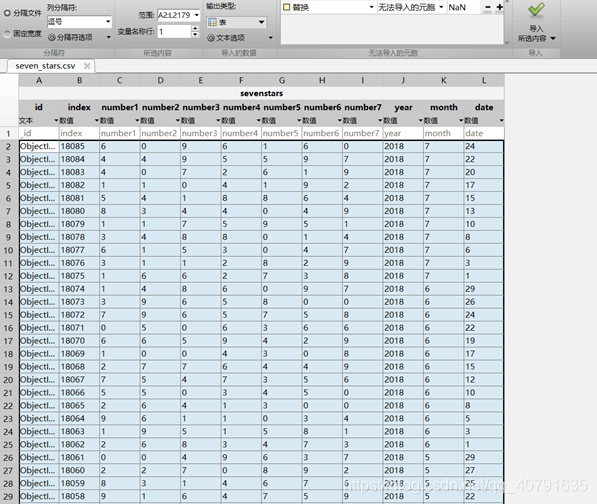
然后左上角把导入表的属性改为导入数值矩阵,在下拉栏里面。
也可以用table2array()函数。
深吸一口气。
按住我躁动的小心脏,继续把处理数据的代码写完,构建神经网络。
(我马上翻以前的案例和笔记,好多都忘了,正好借此温习一波。)
终于我按下了启动键。。。。。。
然而
o(╥﹏╥)o
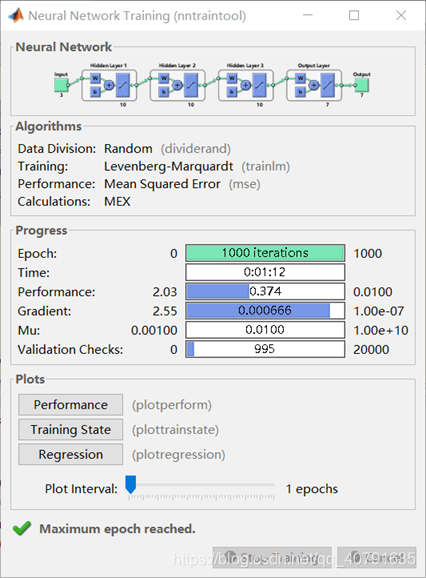
误差迭代1000个epoch(周期)之后居然还有0.374!!!
要知道数据范围就只有0 --- 1!!!
打开performance:
然并卵
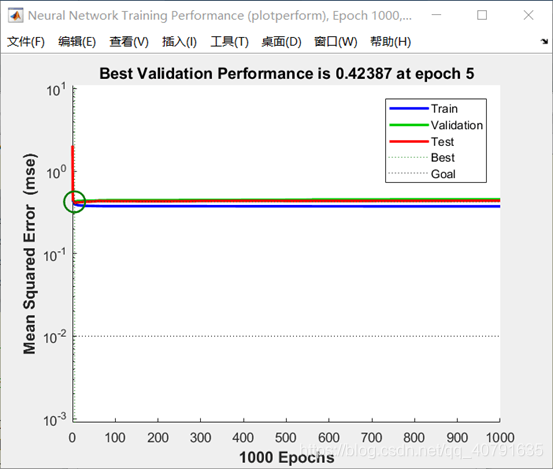
终于这张图完全摧垮了我的所有幻想:
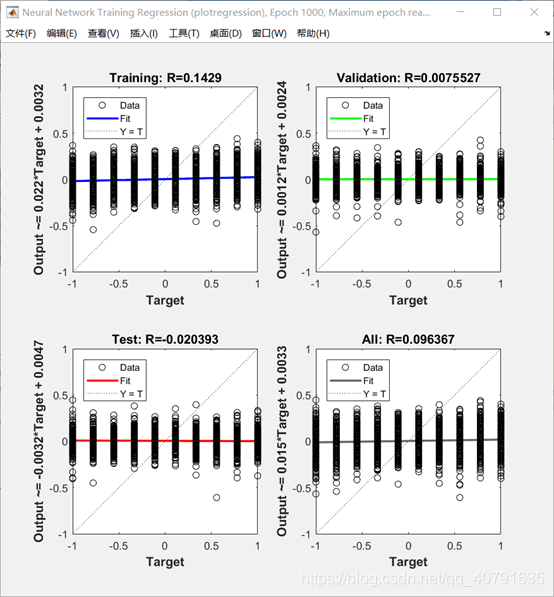
在y=x上说明模型温和比较好:
但是看这个???
你给我十根油条是什么意思???

但是我还是不放弃希望!
于是我想着统计一波数字出现的概率,嘿嘿嘿,说不定今年某个数字出现的概率比较大呢??
越想越激动,然后得到14年以来0到9这十个数字,在每一个位置出现的概率,七星彩,总共有七个位置,并且是有顺序的。
十四年以来每个位置,每个数字出现的概率。
(这张表上的数据在手机上看会灰常蛋疼!!!没办法,手机和电脑格式不一样啊。。。)
(这张表上的数据在手机上看会灰常蛋疼!!!没办法,手机和电脑格式不一样啊。。。)
(这张表上的数据在手机上看会灰常蛋疼!!!没办法,手机和电脑格式不一样啊。。。)
重要事情说三遍。
|
0.088 |
0.096 |
0.088 |
0.102 |
0.106 |
0.096 |
0.104 |
0的概率 |
|
0.101 |
0.120 |
0.104 |
0.102 |
0.096 |
0.101 |
0.105 |
1的概率 |
|
0.100 |
0.092 |
0.108 |
0.105 |
0.104 |
0.098 |
0.096 |
2的概率 |
|
0.097 |
0.102 |
0.091 |
0.089 |
0.110 |
0.100 |
0.101 |
3的概率 |
|
0.112 |
0.089 |
0.105 |
0.094 |
0.094 |
0.101 |
0.093 |
4的概率 |
|
0.096 |
0.100 |
0.099 |
0.100 |
0.107 |
0.099 |
0.102 |
5的概率 |
|
0.105 |
0.102 |
0.120 |
0.094 |
0.087 |
0.112 |
0.101 |
6的概率 |
|
0.090 |
0.101 |
0.086 |
0.113 |
0.088 |
0.095 |
0.108 |
7的概率 |
|
0.099 |
0.101 |
0.109 |
0.099 |
0.108 |
0.096 |
0.096 |
8的概率 |
|
0.112 |
0.097 |
0.090 |
0.101 |
0.101 |
0.102 |
0.092 |
9的概率 |
|
第一位数字 |
第二位数字 |
第三位数字 |
第四位数字 |
第五位数字 |
第六位数字 |
第七位数字 |
|
我去···
每一个数字的概率都差不到哪里去好吗?
来来来,算一组极差,最大的概率和最小的概率差多少。

(表上的数据在手机上看会灰常蛋疼!!!没办法,手机和电脑格式不一样啊。。。)
十四年来出现最多的数字
|
4和9(正好一样) |
第一位 |
|
1 |
第二位 |
|
6 |
第三位 |
|
7 |
第四位 |
|
3 |
第五位 |
|
6 |
第六位 |
|
7 |
第七位 |
数字中最大的概率减去数字中最小的概率,差值最大的都只有3.1%,说明这十年来,各个数字分布得非常平均,看不出哪个数字非常“突出”。
|
0.024 |
0.031 |
0.034 |
0.025 |
0.023 |
0.017 |
0.017 |
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
百分之3.1。。。。

数据不好看的话,我把图画出来了:
这两千多个数据,分为七个位置,也就是七条曲线,画出来。
每一条曲线是不一样的颜色。
这里的横坐标有2178个,这个没什么用。看瞎人类。
忽略这个,一团红+蓝+绿+···什么什么不管了
下面这个还算可以看清:
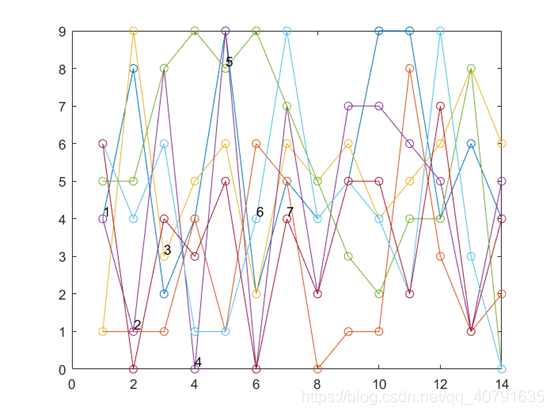
这个是14年来,七个位置概率最大数字的曲线,每一个位置一条曲线。可见每一个位置每一年其实变动都还挺大的。
那些黑色的数字表示那是第几个位置的曲线,总共有7个数字,每个数字比对应的点高0.2个坐标单位,我故意把这些标记都错开了,第一个位置的曲线在第一年标,第二个位置在第二年标(2005年),以此类推。在数字的下面就是他对应的曲线的点,顺着颜色一样就可以把这个位置的曲线给找出来。
年份,横坐标加上2003就是了。
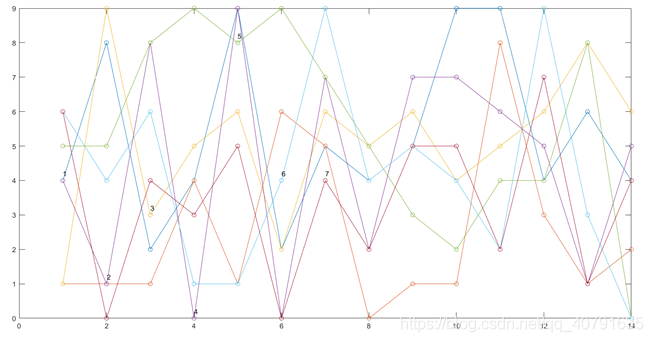
一样的图,稍微大一些。
最后还有更清晰一点的图,这个最清晰了,我把每一条曲线都单独列了出来。
总共七幅图片。
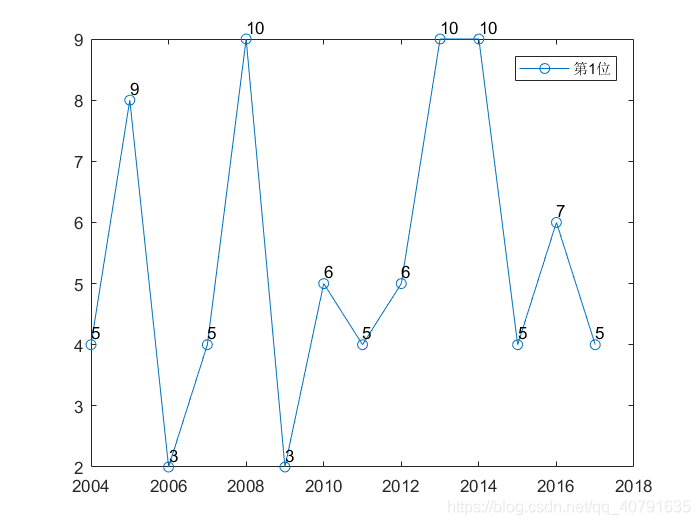
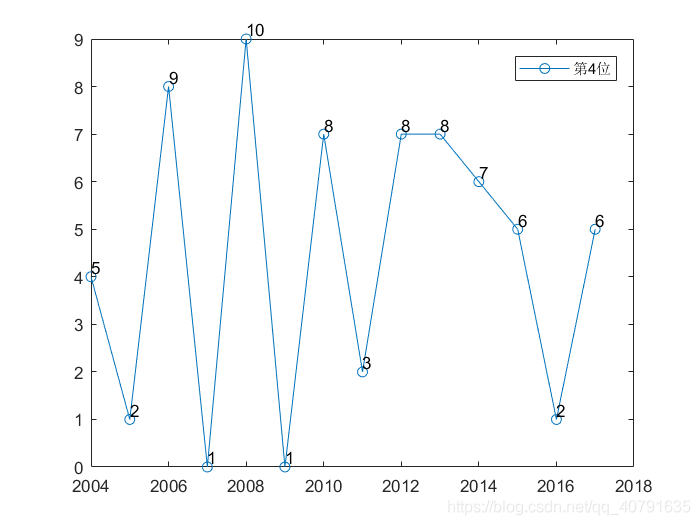
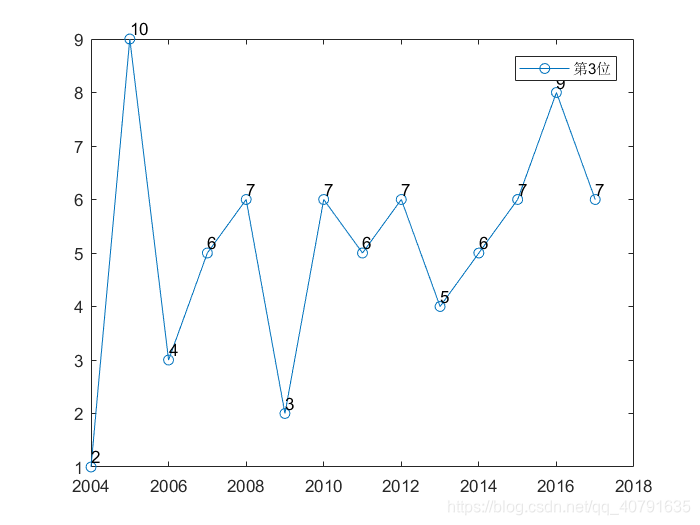
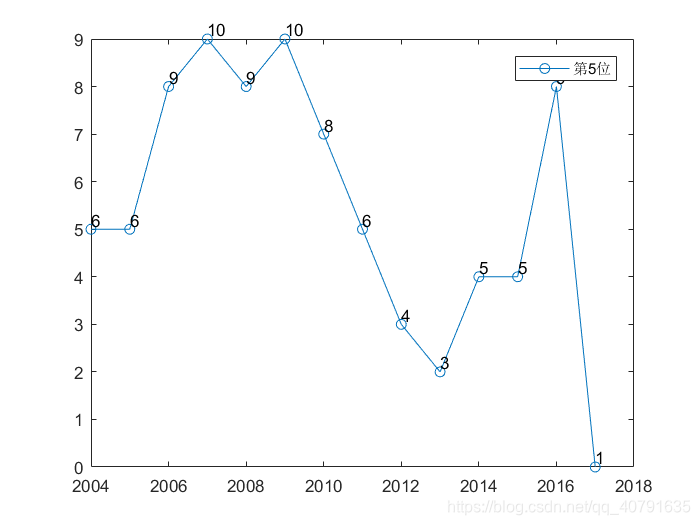
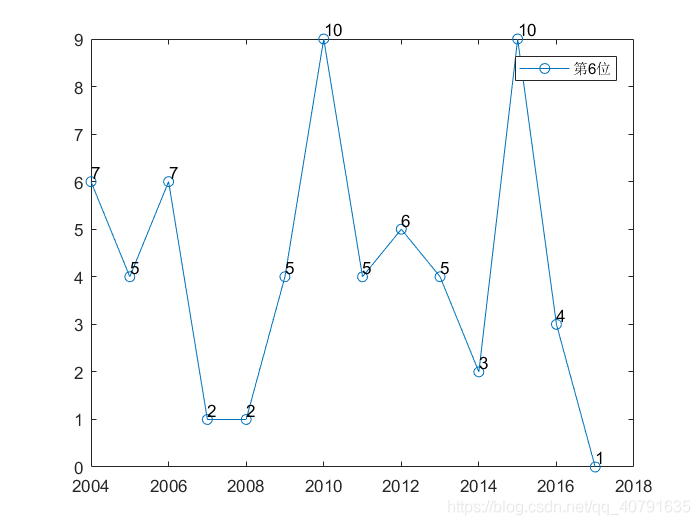
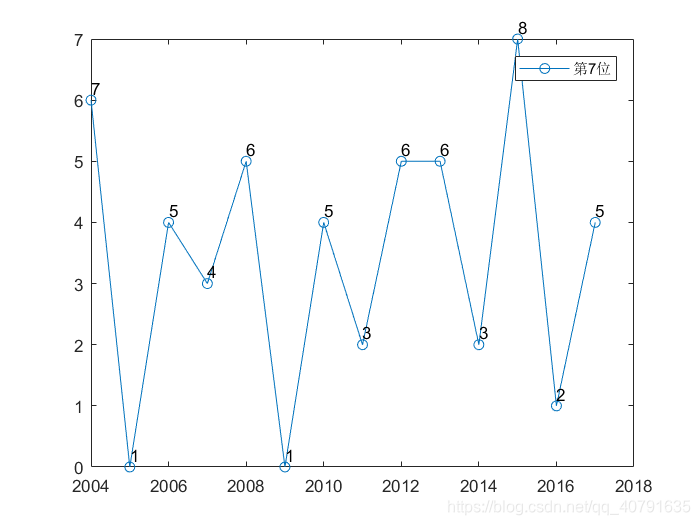
每一个位置概率最大的数字,随着年份,波动真的挺大的。
小结一下吧:
所谓彩票,就是一群不劳而获的人构造出一条貌似能不劳而获的途径,然后勾引和赚取一群想不劳而获的人的钱,最终养活了一群不劳而获的人。
努力奋斗才能梦想成真!
希望大家假期开开心心!!!
下面就是一些代码了,可以忽略咯!
这次用了两个程序一群运行,稍微爬得快一丢丢。
程序1:
import re
from selenium.common.exceptions import TimeoutException # 时间溢出异常
from urllib.parse import quote # 把输入的参数转化进行编码,转化为url可以接受的参数。
from pyquery import PyQuery as pq
from selenium.webdriver import * # 所有浏览器都引进来
from selenium.webdriver.common.by import By # 解析方式 from selenium.webdriver.common.by.By import *也行
from selenium.webdriver.support import expected_conditions as EC # 期望情况的判断
from selenium.webdriver.support.wait import WebDriverWait # 显式等待
import pymongo # 引入数据库的库
from bs4 import BeautifulSoup # 引入“美味的汤”
# chrome_options = ChromeOptions()#chrome浏览器的选项初始化
# chrome_options.add_argument('--headless')#进行无界面的设置,这里必须要分开才行,这里返回的不是chrome_options,只是通过函数进行相关设置。
# browser = Chrome(chrome_options=chrome_options)#将设置付诸行动,建立浏览器
browser = Chrome()
wait = WebDriverWait(browser, 2.5) # 调用webdriver的类进行显式等待的设置。
browser.implicitly_wait(2)
MONGO_URL = 'localhost' # 本地的地址,用来连接
MONGO_DB = 'lottery' # 数据库的名字
MONGO_COLLECTION = 'seven_stars' # 集合的名字
client = pymongo.MongoClient(MONGO_URL) # 建立连接
database = client[MONGO_DB] # 建立数据库
database[MONGO_COLLECTION].drop() # 清除原来的数据,drop掉原来的表
def main():
try:
url = 'http://datachart.500.com/qxc/history/history.shtml'
browser.get(url)#隐式等待即可
browser.switch_to.frame('chart')
input=browser.find_element(By.CSS_SELECTOR,'td[align=center] input#start')
# print(input)
input.clear()
input.send_keys('10001')
# input.send_keys('18001')#only for testing
img=browser.find_element(By.CSS_SELECTOR,'td[align=center] img')
img.click()
print('click_success')
except TimeoutException:
print('GG') # 传入页面的页码进行解析
main()
items=browser.find_elements_by_css_selector('tr.t_tr1')#返回List,find_element只会返回第一个
for item in items:
# print(item.text)
#print(item.find_element_by_css_selector('td.cfont2').text.split(' '))#check
number_list=item.find_element_by_css_selector('td.cfont2').text.split(' ')
elements=item.find_elements_by_css_selector('.t_tr1')
text1=elements[0].text
text2=elements[1].text
text3=elements[2].text
time_list=text3.split('-')
# print(elements[0].text)
# print(elements[1].text)
# print(elements[2].text)
result={
'index':int(text1),
'number1':int(number_list[0]),
'number2':int(number_list[1]),
'number3':int(number_list[2]),
'number4':int(number_list[3]),
'number5':int(number_list[4]),
'number6':int(number_list[5]),
'number7':int(number_list[6]),
'year':int(time_list[0]),
'month':int(time_list[1]),
'date':int(time_list[2])
}
if result['index']>=10000:
if database[MONGO_COLLECTION].insert(result):
print('mongo_db_success!')
print(result)
else:
return 0
main()
#database[MONGO_COLLECTION].insert()
第二个程序:
稍微改了下参数而已。
import re
from selenium.common.exceptions import TimeoutException # 时间溢出异常
from urllib.parse import quote # 把输入的参数转化进行编码,转化为url可以接受的参数。
from pyquery import PyQuery as pq
from selenium.webdriver import * # 所有浏览器都引进来
from selenium.webdriver.common.by import By # 解析方式 from selenium.webdriver.common.by.By import *也行
from selenium.webdriver.support import expected_conditions as EC # 期望情况的判断
from selenium.webdriver.support.wait import WebDriverWait # 显式等待
import pymongo # 引入数据库的库
from bs4 import BeautifulSoup # 引入“美味的汤”
# chrome_options = ChromeOptions()#chrome浏览器的选项初始化
# chrome_options.add_argument('--headless')#进行无界面的设置,这里必须要分开才行,这里返回的不是chrome_options,只是通过函数进行相关设置。
# browser = Chrome(chrome_options=chrome_options)#将设置付诸行动,建立浏览器
browser = Chrome()
wait = WebDriverWait(browser, 2.5) # 调用webdriver的类进行显式等待的设置。
browser.implicitly_wait(2)
MONGO_URL = 'localhost' # 本地的地址,用来连接
MONGO_DB = 'lottery' # 数据库的名字
MONGO_COLLECTION = '_stars' # 集合的名字
client = pymongo.MongoClient(MONGO_URL) # 建立连接
database = client[MONGO_DB] # 建立数据库
# database[MONGO_COLLECTION].drop() # 清除原来的数据,drop掉原来的表
def main():
try:
url = 'http://datachart.500.com/qxc/history/history.shtml'
browser.get(url) # 隐式等待即可
browser.switch_to.frame('chart')
input1 = browser.find_element(By.CSS_SELECTOR, 'td[align=center] input#start')
# print(input)
input1.clear()
input1.send_keys('04101')
input2 = browser.find_element(By.CSS_SELECTOR, 'td[align=center] input#end')
# print(input)
input2.clear()
input2.send_keys('09999')
# input.send_keys('18001')#only for testing
img = browser.find_element(By.CSS_SELECTOR, 'td[align=center] img')
img.click()
print('click_success')
except TimeoutException:
print('GG') # 传入页面的页码进行解析
main()
items = browser.find_elements_by_css_selector('tr.t_tr1') # 返回List,find_element只会返回第一个
for item in items:
# print(item.text)
# print(item.find_element_by_css_selector('td.cfont2').text.split(' '))#check
number_list = item.find_element_by_css_selector('td.cfont2').text.split(' ')
elements = item.find_elements_by_css_selector('.t_tr1')
text1 = elements[0].text
text2 = elements[1].text
text3 = elements[2].text
time_list = text3.split('-')
# print(elements[0].text)
# print(elements[1].text)
# print(elements[2].text)
result = {
'index': int(text1),
'number1': int(number_list[0]),
'number2': int(number_list[1]),
'number3': int(number_list[2]),
'number4': int(number_list[3]),
'number5': int(number_list[4]),
'number6': int(number_list[5]),
'number7': int(number_list[6]),
'year': int(time_list[0]),
'month': int(time_list[1]),
'date': int(time_list[2])
}
if database[MONGO_COLLECTION].insert(result):
print('mongo_db_success!')
print(result)
main()
# database[MONGO_COLLECTION].insert()
下面是matlab的一些代码:
MATLAB可以把代码框住,就运行那一些框住的代码,所以基本上是想到哪写到哪,没有什么逻辑框架之类的。
自由,但是除了自己大概。。。没人有心思看吧···
sevenstars=table2array(sevenstars);
sevenstars=sevenstars_T;
input(1,1:2178)=sevenstars(8,1:2178);
input(2,1:2178)=sevenstars(9,1:2178);
input(3,1:2178)=sevenstars(10,1:2178);
result(1:7,1:2178)=sevenstars(1:7,1:2178);
[one_result, struct_result] = mapminmax(result,-1,1);
[one_input, struct_input] = mapminmax(input,-1,1);
net = newff(one_input,one_result,[10,10,10]);
net.trainParam.epochs = 1000;
net.trainParam.goal = 1e-2;
net.trainParam.lr = 0.01;
net.trainParam.max_fail = 20000;
net = train(net,one_input,one_result);
% B=sum(one_input,2);
% A=B<5;
% C=find(B<5)
one_input([1,2],2)
test_(:,1)=[2018,7,26];
test_ = mapminmax('apply',test_, struct_input);
t_sim = sim(net,test_);%仿真
T_sim = mapminmax('reverse',t_sim,struct_result);
n=size(sevenstars,2)
size(find(sevenstars(1,:)==0),2)
%%
for i=1:10
for j=1:7
probability(i,j)=size(find(sevenstars(j,:)==i-1),2)/n;
end
end
[x,y]=find(probability==max(probability))
x=x-1
dif=max(probability)-min(probability)
hold on
figure
for i=1:7
plot(1:n,sevenstars(i,1:n))
end
figure
hold on
for i=1:7
plot(1:n,sevenstars(i,1:n))
end
plot(1:n,sevenstars(1,1:n),'-r*')
hold on
plot(1:n,sevenstars(2,1:n),'-o')
[x2018,y2018]=find(sevenstars==2018);
[x2018,y2017]=find(sevenstars==2017);
[x2018,y2016]=find(sevenstars==2016);
[x2018,y2015]=find(sevenstars==2015);
[x2018,y2014]=find(sevenstars==2014);
[x2018,y2013]=find(sevenstars==2013);
[x2018,y2012]=find(sevenstars==2012);
[x2018,y2011]=find(sevenstars==2011);
[x2018,y2010]=find(sevenstars==2010);
[x2018,y2009]=find(sevenstars==2009);
[x2018,y2008]=find(sevenstars==2008);
[x2018,y2007]=find(sevenstars==2007);
[x2018,y2006]=find(sevenstars==2006);
[x2018,y2005]=find(sevenstars==2005);
[x2018,y2004]=find(sevenstars==2004);
Y=zeros(200,30)
Y(1:97,1)=y2004
Y(1:153,2)=y2005
Y(1:154,3)=y2006
Y(1:153,4)=y2007
Y(1:154,5)=y2008
Y(1:153,6)=y2009
Y(1:154,7)=y2010
Y(1:153,8)=y2011
Y(1:154,9)=y2012
Y(1:154,10)=y2013
Y(1:153,11)=y2014
Y(1:153,12)=y2015
Y(1:154,13)=y2016
Y(1:154,14)=y2017
Y1=Y;
[a,b]=find(Y1==0);
Y1{1,2}=[]
for i=1:10
for j=1:7
probability(i,j)=size(find(sevenstars(j,:)==i-1),2)/n;
end
end
full_p=cell(1,14);
full_p{1,1}=[];
for k=1:14
Y_reserve=Y(:,k);
Y_reserve(find(Y_reserve==0))=[];
reserve=sevenstars(:,Y_reserve);
n=size(Y_reserve,1);
for i=1:10
for j=1:7
probability(i,j)=size(find(reserve(j,:)==i-1),2)/n;
end
end
full_p{1,k}=probability;
clear probability Y_reserve
end
for i=1:14
[x,y]=max(full_p{1,i});
yy(:,i)=y;
end
for i=1:7
plot(1:14,yy(i,1:14)-1,'-o')
text(i,yy(i,i)-1+0.2,num2str(i))
% for j=1:14
% text(j,yy(i,j)-1,[num2str(yy(i,i))])
%
% end
hold on
legend(['第',num2str(i),'位'])
end
for i=1:7
figure
plot(2004:2017,yy(i,1:14)-1,'-o')
for j=1:14
text(j+2003,yy(i,j)-1+0.2,[num2str(yy(i,j))])
end
hold on
legend(['第',num2str(i),'位'])
end
python/matlab/excel语法小总结:
1、https://blog.csdn.net/xgxyxs/article/details/53265318
改变matlab神经网络中训练集,测试集的比例。
2、http://blog.sina.com.cn/s/blog_b0ae46ad0102whmo.html
validation check的含义,防止过拟合,这篇文章里有讲。
net = newff(one_input,one_result,[10,10,10]);%初始化
net.trainParam.epochs = 1000;
net.trainParam.goal = 1e-2;
net.trainParam.lr = 0.01;
net.trainParam.max_fail = 20000;%改变validation check的次数,想让他一直练下去,知道epoch达到1000(默认)
net = train(net,one_input,one_result);
这里训练集要重复输入两次,如果第二次train函数没输入训练不了,应该是个规范问题。
3、
%B=sum(one_result,1);把每一列加起来
% B=sum(one_result,2);%把每一行加起来
% A=B<5;
% C=find(B<5)
4、变量名不要与文件名重复
预测输出
5.64902154574710
3.17886477348706
3.60725379423438
4.75603454169594
5.52918160335890
2.97167166187060
2.89186715673648
5、one_input([1,2],2)
one_input列表的第一、二行的第二列上的数据。(两个)
6、
excel点开设置单元格格式的数字->数值中,可以设置保留多少位小数。
7、
C = max(A,B)
返回一个和A和B同大小的数组,其中的元素是从A或B中取出的最大元素。
AB矩阵的维度必须一样
C=max(A,2)
把数字2,看成与A维度一样的全是2的“2”阵。
C = max(A) 返回每一列的最大值
C = max(A,[],2) 返回每一行的最大值
8、
hold on在原来的图像上画图
hold off 取消
不加hold off会一直作用
或者加一个figure,会产生一个新的图片,之前的hold on 没用了。
9、
[x2018,y2018]=find(sevenstars==2018);
y2018为列序号,x2018为行序号。
10、
Y(:,2)=y2005
Y(:,4)=y2007
Y(:,3)=y2006
因为y2005,y2007都是153行,所以可以,但是到了y2006他是154行,这样扩张矩阵之后不再是一个“矩形”,形状不对,所以不能这样。
如果Y不存在第二列,那么直接写行数直接写:,这是可以的,但是如果Y本来有第二列,并且行数是200,那么就必须写1:153与后面一致。
如果是扩张,那么扩张之后必须是矩形。
如果在矩阵范围内,那么必选标明范围。
11、
矩阵[A,B,C]嵌套矩阵,那么ABC维度必须一样。
这个时候,可以用D=cell(A,B,C)元宝数组。
一、创建元胞数组
1、用cell命令创建规格为2*2的空元胞
>> a=cell(2,2)
a =
[] []
[] []
2、用大括号"{}"创建元胞数组并赋值
>> b={'abc',[1,2,3];123,'a'}
b =
'abc' [1x3 double]
[123] 'a'
二、读取元胞数组内容
1、获取指定元胞的大小,用小括号“()”
>> b(1,2)
ans =
[1x3 double]
2、获取指定元胞的内容,用大括号“{}”
>> b{1,2}
ans =
1 2 3
3、进一步获取指定元胞的内容,如b{1,2}为数组,获取该数组指定元素
>> b{1,2}(1,1)%嵌套读取。
ans =
1
12、
矩阵调用用(1,2)小括号
元胞数组调用用{1,2}
13、
矩阵里面不能删除一个元素!!!
A(1,2)=[]是不行的
A(1,:)=[]ok!
只能删除一行或者一列。
14、matlab中,for循环的计数变量和里面的操作变量在for循环之外还能用,作用域是全局。
for循环嵌套不要取一样名字的计数变量。
15、selenium只要定位到元素就可以点击,应该是传递了CSS的位置信息,仅仅是模仿浏览器的鼠标在那个标签所对应的元素的信息的“位置”进行了点击,不管是text,img都是可以的!
努力奋斗才能梦想成真!


















 850
850

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









