







正则
作用 : 用来处理一定特征的字符串的规则。
字符集
普通字符集:
字母,数字,汉字,下划线,以及没有特定含义的符号都是普通字符
匹配的时候,精确匹配。

转义字符
- \n——换行符
- \t——制表符
- \——代表\本身
- ^,$,.,(,),{,},?,+,*,[,|,] ——匹配这些字符本身,因为单个字符在正则中已有特殊含义。

元字符 - [] ——表示或关系的集合
- () ——用来分组和提升优先级
- {} ——量词,表示次数。
- \ ——用来转义。
- ^——表示非关系,表示开始边界。
- $——表示结束边界
- . ——匹配除了换行符**\r\n**外的所有字符
- *——量词,意指出现0-N次
- +——量词,意指出现1-N次
- ?——量词,意指0-1次,也有其他意思。下文介绍
- | ——或关系。
这些符号想精确匹配字符,需要转义
转义字符
- \d ——表示任意一个数字(0-9)
- \w ——表示任意一个字母数字或下划线,(A-Z,a-z,0-9,_)之间任意一个
- \s ——表示空格,制表符,换行符等空白字符中的一个。
- .——小数点用来匹配任意字符,除了\n(换行符)
转义字符字母大写代表意思取反。 - \D ——表示除了数字(0-9)的字符
- \W ——表示除了任意一个字母数字或下划线的字符,(除了A-Z,a-z,0-9,_)的字符
- \s ——表示除了 空格,制表符,换行符等空白字符中的字符。
所以用来匹配全字符一般用[\s\S];
自定义字符集合
使用[ ] 括起来的匹配方式,[ ] 里的字符之间是或的关系。能匹配其中的任意一个字符
-
^ 放在[ ]最开头 是非的意思。表示取反。 [^a]表示除了a以外的所有字符
如果在[ ]里头 但是^不是第一个,那么只表示**普通字符**。 如果放在[ ]外头表示开始边界。下方会做介绍 -
- 在[ ]里头,并且左右是数字,或者英文字符。代表区间
a-z 代表用a到z的字符任意一个 A-z 代表大写A-小写z字符任意一个 a-Z 不行会报错 0-9 代表数字0-9之间的任意一个 如果单独把-放[ ]最左或最右表示单个字符 - *****必须左边字符的ascII码小于右边字符的ASCII码****** -
\ 在[ ]中也表示转义。
-
特殊符号在[ ]中会失去其本身意义,除了 - ^ \ 三个。

举例:
[(as)] -> a s ( )
[a-z] ->小写字母
[-]a-z[] -> - [ ] 及小写字母
量词
作用:修改匹配次数的特殊符号 {}
- {n} ——匹配 n 次
- {n,m}——至少重复 n 次,最多重复 m 次
- {n,}——至少重复 n 次,无上限。
- ? —— 0 次或 1 次 相当于 {0,1}
- ‘* —— 0 次,或无数次 ,相当于 {0,}
- ‘+—— 至少 1 次,或者无数次。 相当于{1,}
例子:
co*ke –> 不限个数的o ,匹配cke coke cooke cooooke 等
co{0}ke ->0 个 o ,匹配 cke
1[34578]\d{9} ->匹配手机号
匹配次数中,上限不定时,都是匹配的字数越多越好。 即贪婪模式。
如 co* —> 匹配的 co 直到最后不是o 为止,经可能多的匹配。
懒惰模式:匹配的字符越少越好, 在量词后面加? 就可以将贪婪模式改为懒惰模式。
如 co*? —> 匹配到一个c 就停止。 *表示0个到无数个,懒惰模式选择最少。因此匹配0个。

阻止贪婪有两种方式
1、 量词后面使用 ?
2、 使用取反
边界
边界字符不占宽度。只是一个界限。
-
^ —— 开始边界
表示开始开头必须是^后跟着的字符。 多行模式表示每行的开头,单行模式表示整个字符串的开头 -
$—— 结束边界
表示以 $ 前的字符结尾。 多行模式表示每行的结尾,单行模式表示整个字符串的结尾 -
\b ——单词边界
在字符前加\b表示 匹配字符前无字符。 在字符后加\b 表示 匹配的字符后无字符 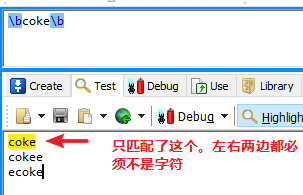 -
\B ——非单词边界
\B表示取反。非单词边界,后面是字符的可以匹配。

举例
查找开头的 hello -> ^hello
查找结尾的 world -> world$
选择符与分组
选择符: | ->表示或 ,优先级低 ,满足匹配则停止,不会查找更优的方案。
he|hello –>只匹配 he,不匹配 hello 因为hello中也有he。所以满足左边就不会匹配。
hello|he->匹配 he 与 hello 因为左边为hello。如果左边不满足。则会去查右边的he。
分组
()中的表达式会作为一个整体。并且会有一个捕获组的概念。
捕获组:在匹配结果的时候,括号中的表达式可以被单独拿到,每一对括号对应一个捕获组,从左边第一个括号 顺序为从1开始编号。捕获元素为0的第一个捕获组是整个正则匹配的文本(一般不用)

\b(and|or)\b -> 捕获 and 或 or
通过反向引用来对捕获组进行操作。
反向引用:内部默认缓存,从第一个左括号计算,编号为 1 开始。
(")test\1 –> “第 1 个左括号中
((")test)\2 –> “第 2 个左括号中
非捕获组😦?:xxx) : 不缓存组 加入?:代表此括号不能作为反向引用使用。
((?:")test)\2 –> 则不能使用\2 来引用 “
模式修改符
(?ism )*(?-ism)
使用 ?后面加 i 或者 s 或者m来改变匹配的模式 中间跟着字符。代表作用的字符

i : insensitive 表示 正则表达式对大小写不敏感
s: singleline 开启“单行模式”,即点号“.”匹配新行符;
m: multiline 开启“多行模式”,即“^”和“$”匹配新行符的前面和后面的位置
零宽断言
零宽表示,不占宽度(类似\b等边界符)
断言表示预言,指定你应该有什么。
- (?=正则表达式) 先行断言,判断自身位置后面应该匹配的表达式

- (?<=正则表达式) 后发断言,判断自身前应该匹配的表达式。
匹配前面跟着b的ddd字符。

- (?!正则表达式) 断言此处位置的后面不能跟的表达式
匹配home后面跟着的不是work的字符串 
- (?!<正则表达式)断言此处位置前不能匹配的表达式。
类似于第一条于第二条的关系。是第三条的位置替换。

Java中使用正则表达式
使用Pattern类 建立正则表达式
通过 Pattern类的静态方法compile();
public static Pattern compile(String regex)传入正则表达式,返回Pattern对象。
通过Matcher 来进行对字符串和正则表达式的操作
-public Matcher matcher(CharSequence input) 传入匹配的字符或匹配器。
通过Matcher的方法进行操作
- find()——查找于该模式匹配的字符序列。匹配完一个自动往下走
- group()——返回之前匹配操作所匹配的字符序列,和find()连用。
- group(int group)—— 返回匹配期间给定的捕获组捕获的子序列。
public static void main(String[] args) {
Pattern p = Pattern.compile("(wo)\\1");
Matcher m = p.matcher("wowoadak");
m.find();
System.out.println(m.group(1)); //返回wo
}
字符串中的spilt 方法和replaceAll方法都可以传入正则。
















 408
408

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









