







你真的认识Redis吗?
本文都是一些理论性的知识笔记形式,有些扩展和问题,尽量减少大篇幅的指令和实操方法介绍,这些搜索或者官方文档比比皆是,需要的时候查询也来得及。
认识redis
redis是NoSql非关系型数据库,NoSQL = Not Only SQL(不仅仅是 SQL)。
什么是关系型数据库?
关系型数据库:(Relational DataBase Management System),简称 RDBMS,以关系模型组织数据,表现形式为:表格,行,列。
NoSql优点:
- 方便扩展(数据之间没有关系,很好扩展)
- 大数据量高性能(NoSQL的缓存记录级,是一种细粒度的缓存,性能会比较高)
- 数据类型是多样型的(不需要事先设计数据库,随取随用)
RDBMS对比NoSql
传统的 RDBS
- 结构化组织
- SQL
- 数据和关系都存在单独的表中
- 操作语言,数据库定义语言
- 严格的一致性
- 基础的事务
NoSQL
- 不仅仅是数据
- 没有固定的查询语言
- 键值对存储,列存储,文档存储,图形数据库
- 最终一致性
- CAP 定理和 BASE (异地多活)
- 高性能,高可用,高可扩
扩展一下CAP定理和BASE理论
cap定理:
CAP定理(CAP theorem),又被称作布鲁尔定理(Brewer’s theorem),它指出对于一个分布式计算系统来说,不可能同时满足以下三点:
-
一致性(Consistency) (对数据的所有操作成功与失败保持一致,即满足原子性,在任何情况下,所有节点的数据都是一致的。举例,向主数据库写入数据时,同步数据时需要时间,这个过程锁库,避免读到不一致的数据)
-
可用性(Availability)(每次请求都会快速得到相应,不会超时或者出错。举例向主数据库写入数据时,不能锁库,一定要及时返回数据,即时是旧数据或者一些默认值)
-
分区容错性(Partition tolerance)(存储系统部署在多个节点,且不在同一网络中,此时形成网络分区,会产生网络问题,通信失败等,在这种情况下系统仍能对外提供服务。举例主数据库同步到从数据库时,不锁库,一定要及时返回数据,即时是旧数据或者一些默认值,不管是主库还是从库的节点挂掉,也不影响其他节点对外服务)
根据定理,分布式系统只能满足三项中的两项而不可能满足全部三项。很好理解,首先CAP定理是针对分布式系统的,所以必须满足P,否则就不是标准的分布式系统。其次不难看出C和A是矛盾的,所以只有CP或者AP可选,不可能同时满足CAP。
应用:微服务领域主流注册中心组件:zookeeper和eureka,其中zookeeper保证CP,eureka保证AP
Base理论:
实际场景中,大部分公司会选择AP,保证可用性和分区容错性,舍弃强一致性,容忍数据一段时间后是保持一致的,这种情况引入了Base理论,也就是对CAP定理中AP的扩展。
Base的全称是基本可用(Base Availability),软状态(Soft State),最终一致性(Exxxx英文忘了。。。)。
- 基本可用性:分布式系统在出现故障的时候,允许关闭部分可用性,例如快速的响应时间,某些功能模块,但要保证基本的系统运行。例如商城系统,可以响应时间变慢,或者部分图片,广告加载不出来,但保证客户下单付款正常。
- 软状态:软状态表示某一个中间态,既不是失败也不是成功,不影响系统的可用性(反而我觉得提高了对客户的友好程度),允许各个系统节点之间的数据同步出现延迟。例如商城系统的支付中,请等待支付成功等状态提示
- 最终一致性:很简单,意思是经过一段时间后,这个系统的数据各个节点能同步一致。例如支付中,最后会变成支付成功或者支付失败,从软状态变成最终的一致状态。
NoSql的四大类
-
KV键值对:redis
-
文档型数据库(bson和json类似):MongoDB(分布式文件存储数据库,主要用来处理大量文档。介于关系型和非关系型数据库中间的产品)
-
列存数据库:HBase
-
图关系数据库:Neo4j, InfoGrid
Redis入门
Redis(Remote Directionary Server),即远程字典服务
特点:
- 内存存储高效,支持持久化(RDB和AOF)
- 发布订阅系统,队列
- 地图信息分析
- 计数器、计时器(浏览量)
- 多样的数据类型
- 集群
- 事务
Redis是单线程,提问为什么这么快,这么个高效?
误区1:高性能服务器一定是多线程的
误区2:多线程一定比单线程更高效
官方表示CPU不是redis的性能瓶颈,内存和网络带宽才是。
首先执行效率CPU>内存>硬盘,Redis是将所有数据全部存放在内存中的,所以使用单线程去执行就是效率最高的,因为多线程在执行过程中存在CPU的上下文切换,这是耗时操作,对于内存系统来说没有上下文切换就是最高效的,多次读写在一个CPU上。
当然,redis还采用了网络IO多路复用技术保证多连接的时候,系统的高吞吐量;使用跳表,链表,动态字符串,压缩列表等技术来实现数据结构,效率更高。
Redis数据类型
这里的数据类型指value,key都是string类型
五大基本类型
官网可查看命令: http://www.redis.cn/commands.html
String,List,Set,Hash,ZSet
- String:value除了是字符串还可以是数字,常用于计数器,粉丝数,对象缓存存储
- List:可以把list当作栈,队列,阻塞队列等,l开头的命令一般代表队列左侧执行,r代表右侧。实际上list是一个链表,前后都可以插入。如果key不存在则会创建新的list,如果移除了list所有值,则代表空链表,不存在。在list的两边插入或者改动值效率最高
- Set:集合
- Hash:value是map的形式,命令一般是:操作命令 key filed value,hash一般适合存储经常变动的对象信息,String更适合存储字符串
- ZSet:有序集合
三种特殊数据类型
geospatial,hyperloglog,bitmap
-
geospatial:地理位置。一般推算地理位置信息,两地之间距离
-
hyperloglog:基数:数学上集合的元素个数,是不能重复的。这个数据结构常用于统计网站的 UV。传统的方式是使用 set 保存用户的ID,然后统计 set 中元素的数量作为判断标准。但是这种方式保存了大量的用户 ID,ID 一般比较长,占空间,还很麻烦。我们的目的是计数,不是保存数据,所以这样做有弊端。但是如果使用 hyperloglog 就比较合适了。UV(Unique visitor):是指通过互联网访问、浏览这个网页的自然人。访问的一个电脑客户端为一个访客,一天内同一个访客仅被计算一次。
-
bitmap:bitmap就是通过最小的单位bit来进行0或者1的设置,表示某个元素对应的值或者状态。一个bit的值,或者是0,或者是1;也就是说一个bit能存储的最多信息是2。
bitmap 常用于统计用户信息比如活跃粉丝和不活跃粉丝、登录和未登录、是否打卡等。
Redis的事务
ACID:原子性,一致性,隔离性,持久性
Redis 事务的本质:一组命令的集合!一个事务中的所有命令都会被序列化,在事务执行过程中,会按照顺序执行。
一次性、顺序性、排他性的执行一组命令。
Redis 事务没有隔离级别的概念。
所有的命令在事务中,并没有直接被执行,只有发起执行命令的时候才会执行(exec)。
Redis 单条命令是保证原子性的,但是事务不保证原子性。
Redis 事务的命令:
- 开启事务:multi
- 命令入队
- 执行事务:exec(exec之后才开始执行)
- 撤销事务:discard
监视Watch:watch命令可以监控一个或多个key,一旦其中有一个key被修改(或删除),之后的事务就不会执行。监控一直持续到exec命令(事务中的命令是在exec之后才执行的,所以在multi命令后可以修改watch监控的键值)。假设我们通过watch命令在事务执行之前监控了多个Keys,倘若在watch之后有任何Key的值发生了变化,exec命令执行的事务都将被放弃,同时返回Null multi-bulk应答以通知调用者事务执行失败。
Redis的持久化
Redis 是内存数据库,如果不将内存中的数据库状态保存到磁盘,那么一旦服务器进程退出,服务器中的数据库状态就会消失,所以 Redis 提供了持久化功能。
RDB(Redis DataBase)
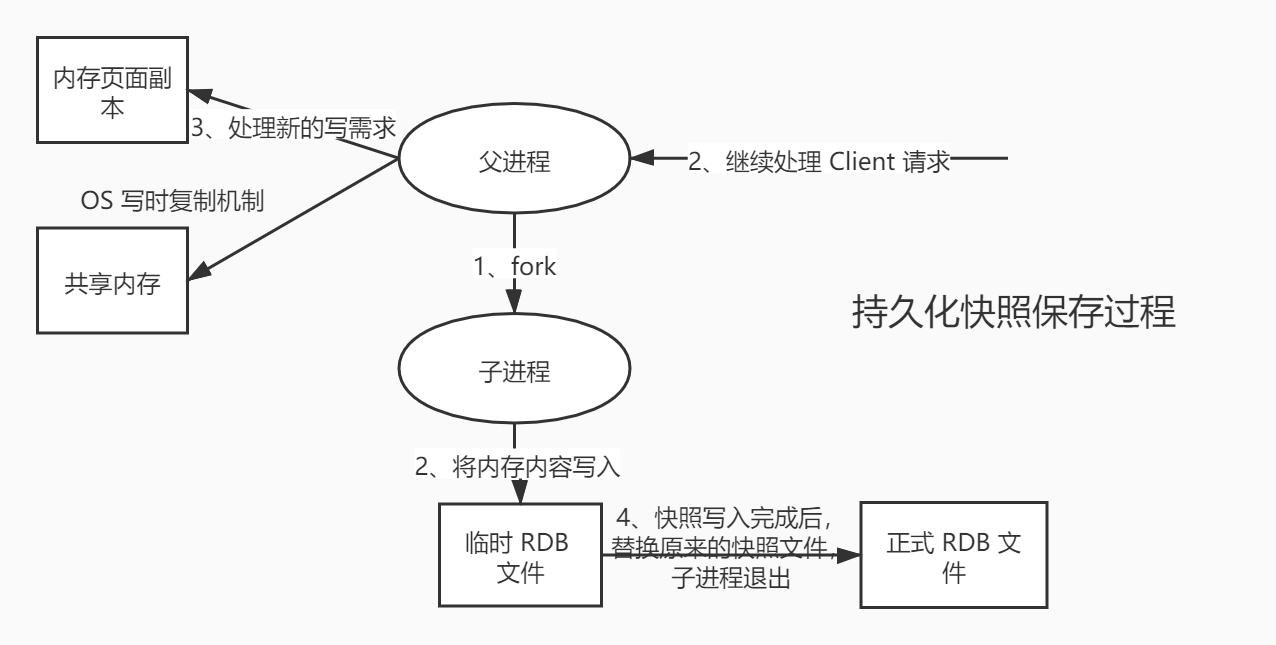
优点:
- rdb文件都是二进制,占用空间很小。比如内存数据10G,rdb文件可能只有1G。所以灾后恢复效率高
- 处理命令的效率比AOF快,每个命令请求来的时候,不会处理任何事,只是bgsave的时候会fork子进程且可能copyonwrite,但是copyonwrite只是寻址操作,纳秒级。而AOF每次都是写盘,毫秒级操作。
缺点:
- 数据可靠性不如AOF,丢失的数据更多可能性更大。因为AOF可以配置每秒或者每个命令执行完后就立马持久化,这种高频率的持久化操作,牺牲了性能,保证了可靠性。RDB每次全量持久化,可能会丢失最后一次的数据。而AOF只是追加
RDB持久化的两种方法分为save和bgsave:
- save:同步阻塞,持久化的时候,执行save的线程会阻塞,其实也就是整个redis服务会阻塞,因为redis是单线程
- bgsave:异步非阻塞,原理是fork()+copyonwrite,可以一边进行持久化,一边对外提供读写服务,新写入的数据不对持久化的数据产生影响
扩展fork()
fork():
fork()是unix和linux这种操作系统的一个api,而不是Redis的api。
fork用于创建一个子进程,注意不是子线程,fork出来的进程共享其父类的内存数据。但是仅仅共享fork出子进程那一刻的内存数据,后期主进程的数据变化对于子进程是不可见的,子进程的数据变化主进程也是不可见的。子进程挂了不影响主进程,但是主进程挂了,子进程也会挂。
Redis巧妙地使用了fork这个api来进行了RDB的持久化操作。
当bgsave执行时,Redis主进程会判断当前是否有fork()出来的子进程,若有则忽略,若没有则会fork()出一个子进程来执行rdb文件持久化的工作,子进程与Redis主进程共享同一份内存空间,二者互不影响。他们之后的修改内存数据对彼此不可见,但是明明指向的都是同一块内存空间,这是为什么?肯定不可能是fork()出来子进程后顺带复制了一份数据出来,如果是这样的话,要给rdb留出一半空间来,这样太浪费了,Redis采用了copyonwrite技术。
p.s.调用fork()也会阻塞,但是这个阻塞真的可以忽略不计。尤其是相对于阻塞主线程的save。
copyonwrite:
主进程fork()子进程之后,内核把主进程中所有的内存页的权限都设为read-only,然后子进程的地址空间指向主进程。当主子进程有内存写入操作时,CPU硬件检测到内存页是read-only的,于是触发页异常中断(page-fault),陷入内核的一个中断例程。中断例程中,内核就会把触发的异常的页复制一份(这里仅仅复制异常页,也就是所修改的那个数据页,而不是内存中的全部数据),于是主子进程各自持有独立的一份。(其余的页还是共享主进程的)。
p.s.对于大多数的 Redis 服务或者数据库,写请求往往都是远小于读请求的,所以使用fork()加上写时拷贝这一机制能够带来非常好的性能,也让BGSAVE这一操作的实现变得很简单。
AOF(Append Only File)
AOF( append only file )持久化以独立日志的方式记录每次写命令,并在 Redis 重启时在重新执行 AOF 文件中的命令以达到恢复数据的目的。AOF 的主要作用是解决数据持久化的实时性。
AOF简单来说就是以日志的形式记录每一个除读以外的操作指令,记录的时候只追加不可以改写日志文件。redis重启的时候会读取该日志文件进行数据的重构恢复,也就是按照顺序重新执行一遍所有指令操作。
优点:
- 每一次指令操作都同步,持久化的可靠性和完整性更好
- 持久化的速度更快,因为每次只追加,RDB是全量
缺点:
-
相对于数据文件来说占用空间更大,灾后恢复速度更慢
-
影响性能,效率低相较于RDB,因为AOF与主进程收到请求、处理请求是串行化的,而非异步并行的。
基本原理:Client->Redis-Server->执行命令->命令写入AOF缓冲区->刷盘写入AOF文件
Redis每次都先将命令放到缓冲区,根据具体策略(每秒/每条指令/缓冲区满)进行刷盘,如果是配置是Always,就是典型阻塞,如果是sec,就会开一个同步线程去每秒进行刷盘操作,对主线程影响稍小一些。
**rewrite:**rewrite操作是为了压缩aof的文件大小。比如有个场景是反复set和del一个key,如果每一条都记录的话会非常冗余,没有必要,所以可以进行rewrite操作进行压缩,只保留最新的命令。4.0前rewrite操作只是简单的去重,保留最新的,效率较低。4.0后的rewrite支持混合模式,也就是把rdb的持久化文件运用到aof上,因为rdb的二进制文件占用空间是很小的。具体是将最新的rdb覆盖到aof文件,然后在此基础上继续append命令,下次aof文件过大时再次重复以上操作。
数据恢复
Redis会优先看是否存在aof文件,若存在则先按照aof文件恢复,因为aof毕竟比rdb全。若aof不存在,则才会查找rdb是否存在。这是默认的机制。毕竟aof文件也rewrite成rdb二进制格式,文件小,易于回复。所以redis会优先采取aof。
发布订阅
其实就是MQ,被订阅者写消息,订阅者们实时读到消息进行处理。只有已订阅的客户端才能收到消息,比如我给test发送了一条helloworld,他会发给当前所有订阅test的客户端推送helloworld这条消息,后来的客户端再去订阅test,也不会收到这个历史消息。
主从复制
主从复制,是指将一台 Redis 服务器的数据,复制到其他的 Redis 服务器。前者称之为主节点(master/leader),后者称之为从节点(slave/flower);数据的复制都是单向的,只能从主节点到从节点。Master 以写为主,Slave 以读为主。
默认情况下,每台 Redis 服务器都是主节点。且一个主节点可以有多个从节点或者没有从节点,但是一个从节点只能有一个主节点。
作用:
-
数据冗余:主从复制实现了数据的热备份,是持久化的之外的一种数据冗余方式。
-
故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复。实际也是一种服务的冗余。
-
负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务(即写 Redis 数据时应用连接主节点,读 Redis 的时候应用连接从节点),分担服务器负载;尤其是在写少读多的场景下,通过多个节点分担读负载,可以大大提高 Redis 服务器的并发量。
-
高可用(集群)的基石:除了上述作用以外,主从复制还是哨兵模式和集群能够实施的基础,因此说主从复制是 Redis 高可用的基础。
主备和主从
- 主备:请求都在Master上执行,备机只是Master挂了之后自动升级为客户端继续提供服务。
- 主从:读请求会均摊到主节点和从节点上,写请求在Master上进行,然后同步到slaver。
扩展主从复制三种方式:
-
同步阻塞:必须等所有Slaver都同步写入成功后才会响应客户端,否则一直阻塞。也就是CAP中的CP
-
异步非阻塞:**Redis采取的就是这种方式,因为Redis特点就是高效。**Master处理完请求后立马返回给客户端,不会管Slaver是否同步完成,也就是CAP中的AP。
-
同步阻塞MQ:Master接收到客户端请求后,先是一同步阻塞的方式存在MQ(例如Kafka)中,后续MQ再以异步非阻塞的方式同步给Slaver。大数据HIVE采取的此类方式,会保证最终一致性,没异步非阻塞高效,但异步非阻塞的问题是存在丢失数据的风险。
复制原理
Slave 启动成功连接到 Master 后会发送一个 sync 同步命令。
Master 接收到命令后,启动后台的存盘进程,同时收集所有接收到的用于修改数据集的命令,在后台进程执行完毕后,master 将传送整个数据文件到 slave ,并完成一次完全同步。
同步的数据 使用的是RDB文件,收到同步命令之后,master会bgsave 把数据保存在rdb中,发送给从机。
bgsave:fork出来一个子进程 进行处理,不影响主进程的使用。
**全量复制:**Slave 服务在接收到数据库文件后,将其存盘并加载到内存中。
增量复制: Master 继续将新的所有收集到的修改命令一次传给 slave,完成同步。
但是只要重新连接 master ,一次完全同步(全量复制)将被自动执行。我们的数据一定可以在从机中看到。
哨兵模式
哨兵模式能够后台监控主机是否故障,如果故障了自动将从库转换为主库。其原理是哨兵通过发送命令,等待 Redis 服务器响应,从而监控运行的多个 Redis 实例。当哨兵检测到Master宕机,会自动进行主从切换,然后通过发布订阅模式通知其他的Slaver修改配置文件,切换主机。
一个哨兵监控Redis可能不够可靠,会出问题,可以使用多哨兵模式。假设主服务器宕机了,哨兵1先检测到这个结果,仅仅是哨兵 1 主观认为主服务器不可用,这个现象称之为主观下线。当后面的哨兵也检测到主服务器不可用,并且数量达到一定值时,这个过程称之为客观下线,那么哨兵之间就会进行一次投票,投票的结果由一个哨兵发起,最终会选出来一个leader(哨兵节点),进行 failover 故障转移。切换成功后,就会通过发布订阅模式,让各个哨兵把自己监控的从服务器实现切换主从切换。
Redis集群
Redis集群与主从的最大区别在于多个主节点通过分片机制存储所有数据,即每个主从复制结构单元管理部分key。而不是像主从一样所有的写请求集中在一个Redis主节点。
优点:
- 相较于主从,所有写请求不会集中在一个Redis Master,请求增多时,可以均摊压力
- 每个主节点不必存储全量数据,减少了RDB或者AOF的耗时
- 提高了服务的可用性,如果主从的主节点出现故障,在故障恢复转移期间可能导致服务不可用
Redis缓存问题
一些典型的问题就是,缓存穿透、缓存雪崩、缓存击穿。我们可以把缓存当成持久层DB的一层屏障,当请求大量直接访问持久层DB时,会对DB造成大量的压力。
缓存穿透
所谓穿透,也就是透过屏障对DB产生了压力,那么这层屏障还没破裂。
具体来说用户查询了一个内存数据库不存在的key,也就是缓存未命中,接着继续访问持久层DB查询。
这种情况偶尔发生不会有什么问题,但是如果大量出现,就会给DB带来很大的压力,这时候就出现了缓存穿透。
解决方案1:布隆过滤器
布隆过滤器是一种数据结构,对所有存在的参数以 hash计算得到一个下标,作为bitmap的位,将其置为1.当用户查询时,先去布隆过滤器看这个参数是否为1,1则存在,然后继续去缓存和DB查询,否则不存在。位的计算非常的快,消耗很小,对性能影响可以忽略不计。
hash碰撞:可能多个参数计算得到的hash值相同,也就意味着两个查询参数,A存在而B不存在,但恰好两个hash计算后的值相同,那么查询B的时候,布隆过滤器显示1,但是其实不存在该参数B。这种情况叫hash碰撞。所以布隆过滤器不是100%靠谱
提问1:如何减少hash碰撞的几率
可以让参数计算hash的时候,使用不同的计算方法得到N个hash值,然后都设置为1,当查询一个参数的时候,只要N个hash值有一个不为1,则不存在,利用这种方法能几乎99.99%避免hash碰撞
提问2:如果有人恰巧走了狗运,N次的hash值都为1,但是该参数不存在,这个漏洞被他发现了,他一直利用该参数去不停的查询,攻击你的系统,怎么办?
可以把hash都为1,但是redis和mysql都不存在的参数,添加记录到redis里
解决方案2:缓存不存在的对象
当存储层不命中后,即使返回的空对象也将其缓存起来,同步会同步一个过期时间,之后再访问这个数据将会从存储中获取,保护了后端数据源。
存在问题:
- 缓存需要更多的空间存储
- 即使对空值设置了过期时间,还是会存在缓存层和存储层的数据会有一段时间窗口的不一致,这对于需要保持一致性的业务会有影响。
缓存击穿
所谓击穿,意味着缓存这层屏障直接被打破了,通了一个洞。
具体来说某一个key一直持续的被频繁访问,突然这个key失效了,可能过期了,或者被LRU淘汰了,时效的瞬间,大量的请求访问,击穿了缓存,直接请求了DB。
**解决方案1:**简单粗暴的设置热门的key永不过期
**解决方案2:**使用分布式锁,请求来了,先查询redis,如果没有数据需要请求DB时,加锁,DB查到后set到redis。保证每个key同时只有一个线程去查询后端服务,上锁时,其他线程只能等待。
缓存雪崩
所谓雪崩的时候没有一片雪花是无辜的,屏障直接大面积崩溃了
具体来说是指在某一个时间段,大批量热点数据缓存集中过期失效,或者redis直接挂了,大量请求直接访问到DB。
集中过期失效解决方案:
- 简单粗暴的方式是,直接设置所有热点key永不过期。
- 设置这一批热点key,在热门时间段后,随机加上一段时间失效,尽量分散开,避免雪崩的情况,也就是分流的策略
redis宕机解决方案:
- 使用Redis集群或者主从主备
- 数据预热,加一层本地缓存。请求进来先查本地缓存,没有的话去查redis,redis也没有再去db。即使redis挂了,但是我们本地缓存还有,所以不会打到db层。
- 添加限流组件,限制每秒最大请求数。如果超过最大请求数的请求,可以返回一些软状态,例如请等待,或者返回默认值















 217
217

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









