







MyBatis
MyBatis的功能特性:
1.将sql语句存放在xml文件中。
2.自动将输入参数映射到sql语句的动态参数。
3.将sql语句返回结果映射成成java对象。
安装
添加jar包即可。
<!-- https://mvnrepository.com/artifact/org.mybatis/mybatis -->
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.4.1</version>
</dependency>
因为要连接数据库,所以需要对应数据库的jar包。
<!-- https://mvnrepository.com/artifact/mysql/mysql-connector-java -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.38</version>
</dependency>
最后还需要打印执行的sql语句,所以需要添加日志jar包。
<!-- https://mvnrepository.com/artifact/log4j/log4j -->
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-core</artifactId>
<version>1.2.3</version>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.2.3</version>
</dependency>
准备配置文件
db.properties(包含基本的数据库配置)
jdbc.driver=com.mysql.jdbc.Driver
jdbc.url=jdbc:mysql://localhost:3306/springboot_library
jdbc.username=root
jdbc.password=123456
logback.xml(网上有一大堆现成的配置文件以及教程)
一个比较关键的点是,mybatis默认支持很多日志框架,如果有多个框架jar包存在,则会按顺序使用第一个。所以如果mybatis日志不再输出sql,那么很可能是被另一个框架给覆盖了。mybatis支持显式指定某个框架为日志框架,这里以log4j为例子:
<configuration>
<settings>
<!--mybatis默认支持很多日志框架,如果不指定会按顺序来使用,这里显示指定使用log4j-->
<setting name="logImpl" value="LOG4J"/>
</settings>
</configuration>
<?xml version="1.0" encoding="UTF-8"?>
<configuration scan="true" scanPeriod="60 seconds" debug="false">
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<charset>UTF-8</charset>
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n</pattern>
</encoder>
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>DEBUG</level>
</filter>
</appender>
<!--dao接口的位置-->
<logger name="dao" level="debug" />
<logger name="jdbc.sqltiming" level="debug"/>
<logger name="com.ibatis" level="debug" />
<logger name="com.ibatis.common.jdbc.SimpleDataSource" level="debug" />
<logger name="com.ibatis.common.jdbc.ScriptRunner" level="debug" />
<logger name="com.ibatis.sqlmap.engine.impl.SqlMapClientDelegate"
level="debug" />
<logger name="java.sql.Connection" level="debug" />
<logger name="java.sql.Statement" level="debug" />
<logger name="java.sql.PreparedStatement" level="debug" />
<logger name="java.sql.ResultSet" level="debug" />
<root level="DEBUG">
<appender-ref ref="console"/>
</root>
</configuration>
mybatis-config.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<!--引入数据库配置文件-->
<properties resource="db.properties"/>
<!--配置数据源-->
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="${jdbc.driver}"/>
<property name="url" value="${jdbc.url}"/>
<property name="username" value="${jdbc.username}"/>
<property name="password" value="${jdbc.password}"/>
</dataSource>
</environment>
</environments>
<!--定义映射文件-->
<mappers>
<!--可以配置包名。注解定义-->
<!--<package name="mappers" />-->
<!-- 使用相对于类路径的资源引用。xml定义 -->
<mapper resource="mappers/UserMapper.xml"/>
<!-- 使用映射器接口实现类的完全限定类名。注解定义 -->
<!--<mapper class="dao.UserMapper"/>-->
</mappers>
</configuration>
<mappers>的路径有xml定义和注解定义。
注解定义相当于是把xml文件的sql语句直接整合到接口里了。
所以注解定义指向的是使用注解的接口。而xml定义指向xml文件。
编写映射文件和对应的接口
编写UserMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!--namespace 在以mapper接口文件调用sql时,应指向对应的dao层接口-->
<!--直接使用mapper.xml文件中的sql时,可以自定义,只要不与现存的namespace冲突即可-->
<mapper namespace="dao.UserMapper">
<select id="selectUser" parameterType="string" resultType="pojo.User">
select * from user where user_name = #{userName}
</select>
<!--
<insert id=""/>
<update id=""/>
<delete id=""/>
一个语句就是一个statement
-->
</mapper>
对应接口:
package dao;
import pojo.User;
/**
* created by WuJiaJun on 2021/4/4.
*/
public interface UserMapper {
User selectUser(String userName);
}
测试配置是否成功
//以Mapper接口文件调用sql,mapper中的namespace必须指向mapper对应的接口文件
//Mybatis官方更推荐使用这种方式调用sql
public class MyBatisUtil {
private static SqlSessionFactory factory = null;
public static SqlSessionFactory getFactory() throws IOException {
if (factory == null){
InputStream inputStream = Resources.getResourceAsStream("mybatis-config.xml");
factory = new SqlSessionFactoryBuilder().build(inputStream);
}
return factory;
}
public static void main(String[] args) throws IOException {
SqlSessionFactory factory = MyBatisUtil.getFactory();
SqlSession sqlSession = factory.openSession();
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
System.out.println(mapper.selectUser("2470759014"));
sqlSession.close();
}
}
//直接调用mapper中的sql,namespace可以自定义
@Test
public void test2() throws IOException {
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
SqlSession sqlSession = sqlSessionFactory.openSession();
//statement 由 CustomerMapper.xml <mapper> 元素的namespace 属性值+<select> 元素的 id 属性值组成
Customer customer = (Customer)sqlSession.selectOne("dao.CustomerDao.findCustomerById",1);
System.out.println(customer.toString());
sqlSession.close();
}
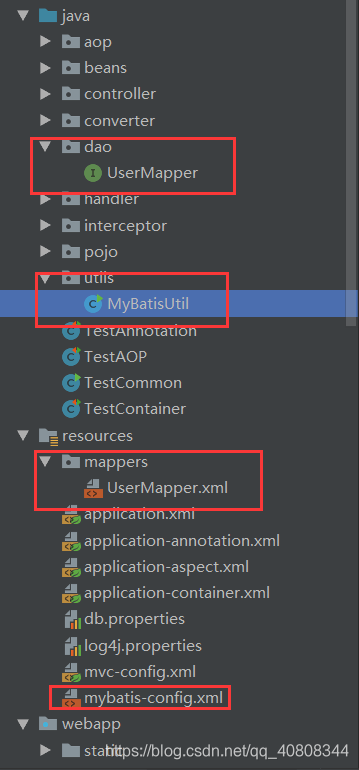
项目结构
定义别名
在mybatis配置文件里配置。
类型别名可为 Java 类型设置一个缩写名字。 它仅用于 XML 配置,意在降低冗余的全限定类名书写。例如:
<typeAliases>
<typeAlias alias="Author" type="domain.blog.Author"/>
<typeAlias alias="Blog" type="domain.blog.Blog"/>
<typeAlias alias="Comment" type="domain.blog.Comment"/>
<typeAlias alias="Post" type="domain.blog.Post"/>
<typeAlias alias="Section" type="domain.blog.Section"/>
<typeAlias alias="Tag" type="domain.blog.Tag"/>
</typeAliases>
当这样配置时,Blog 可以用在任何使用 domain.blog.Blog 的地方。
也可以指定一个包名,MyBatis 会在包名下面搜索需要的 Java Bean,比如:
<typeAliases>
<package name="domain.blog"/>
</typeAliases>
解决列名和属性名不一致
例如:数据库表中列名为user_name,而User类中属性名为userName。
那么user_name的值不会赋给userName。
userName会得到一个默认值(对象为null,数值为0,boolean为false)。
但如果User类中有user_name字段,则赋值会成功。
1、使用sql语句的别名
select user_name as userName where ......
2、使用resultMap
<!--不一定要映射所有属性,可以只映射列名和属性名不一致的情况-->
<resultMap id="userResultMap" type="pojo.User">
<id property="userName" column="user_name" />
<result property="nickName" column="nick_name"/>
</resultMap>
<!--返回值要改成:resultMap。-->
<select id="selectUser" parameterType="string" resultMap="userResultMap">
select * from user where user_name = #{userName}
</select>
resultMap中,id和result节点的区别:
id 和 result 元素都将一个列的值映射到一个简单数据类型(String, int, double, Date 等)的属性或字段。
这两者之间的唯一不同是,id 元素对应的属性会被标记为对象的标识符,在比较对象实例时使用。
这样可以提高整体的性能,尤其是进行缓存和嵌套结果映射(也就是连接映射)的时候。
返回对象时是用set方法还是用构造器为参数赋值?
一般的映射不依赖set方法也不用构造器,可以直接对私有变量赋值。
(真的很奇怪,spring要么用set方法要么用构造器)
类型转换(类型处理器)
现有一个pojo类如下,其中一个属性为enum类型。
在mysql table中,该属性由int表示,1表示男,2表示女。
现在要配置转换器,使得由jdbcType:int 和 javaType:enum能够自由转换
public class User {
private Long id;
private String userName;
private SexEnum sex;
private String note;
//getter setter.....
}
public enum SexEnum {
MALE("男",1),FEMALE("女",2);
private String s;
private Integer i;
SexEnum(String s,Integer i){
this.s = s;
this.i = i;
}
public String getS() {
return s;
}
public Integer getI() {
return i;
}
public static SexEnum getEnumById(int id){
for (SexEnum s:
SexEnum.values()) {
if (s.getI().equals(id)){
return s;
}
}
return null;
}
}
转换器如下,需要实现BaseTypeHandler接口。
@MappedJdbcTypes(JdbcType.INTEGER) //声明jdbcType为整型
@MappedTypes(SexEnum.class) //声明javaType为SexEnum
public class SexTypeHandler extends BaseTypeHandler<SexEnum> {
//设置非空性别参数
@Override
public void setNonNullParameter(PreparedStatement ps, int i, SexEnum parameter, JdbcType jdbcType) throws SQLException {
ps.setInt(i,parameter.getI());
}
//通过列名读取性别
@Override
public SexEnum getNullableResult(ResultSet rs, String columnName) throws SQLException {
int sex = rs.getInt(columnName);
return SexEnum.getEnumById(sex);
}
//通过下标读取性别
@Override
public SexEnum getNullableResult(ResultSet rs, int columnIndex) throws SQLException {
int sex = rs.getInt(columnIndex);
return SexEnum.getEnumById(sex);
}
//通过存储过程读取性别
@Override
public SexEnum getNullableResult(CallableStatement cs, int columnIndex) throws SQLException {
int sex = cs.getInt(columnIndex);
return SexEnum.getEnumById(sex);
}
}
在xml文件中声明该处理器,之后mybatis会自动进行转换。
<!-- mybatis-config.xml -->
<typeHandlers>
<typeHandler handler="org.mybatis.example.SexTypeHandler "/>
</typeHandlers>
模糊查询
1、使用#传参
//接口
public interface UserMapper {
List<User> selectByNickName(String nickName);
}
<!--sql语句-->
<select id="selectByNickName" parameterType="string" resultMap="userResultMap">
select * from user where nick_name like #{nickName}
</select>
SqlSessionFactory factory = MyBatisUtil.getFactory();
SqlSession sqlSession = factory.openSession();
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
//注意传送的参数
List<User> users = mapper.selectByNickName("w%");
2、使用$传参
当parameterType为单值属性(基本数据类型及其包装类还有String)的时候,只能用value字段占位。
//接口
public interface UserMapper {
List<User> selectByNickName(String nickName);
}
<select id="selectByNickName" parameterType="string" resultMap="userResultMap">
select * from user where nick_name like '${value}'
</select>
//测试
SqlSessionFactory factory = MyBatisUtil.getFactory();
SqlSession sqlSession = factory.openSession();
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
List<User> users = mapper.selectByNickName("w");
3、使用concat连接
<select id="findCustomerByName" resultType="map" parameterType="string">
select * from t_customer where username like concat('%',#{name},'%')
</select>
区别
第二种是纯字符串拼接,而第一种相当于prepareStatement的 ? 占位。TODO
建议使用第一种或第三种,第二种有sql注入的风险。
排序
对单一的column排序没有什么坑。
直接写:select * from user order by date;
但是对于给定column参数,根据参数去排序,不能使用#,而必须使用$。
在参数是单值情况下,只能用value占位,即${value}。
public interface UserMapper {
//按指定的列排序
List<User> selectUserBySort(String column);
}
<!--只能用$-->
<select id="selectUserBySort" parameterType="string" resultMap="userResultMap">
select * from user order by ${value}
</select>
//测试
SqlSessionFactory factory = MyBatisUtil.getFactory();
SqlSession sqlSession = factory.openSession();
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
List<User> users = mapper.selectUserBySort("nick_name");
传递多个参数
方法一、按照参数出现的顺序,从0开始。
<select id="selectByPage" resultMap="userResultMap">
select * from user limit #{0},#{1}
</select>
方法二、使用注解
xml的占位字段要和注解的参数一致
public interface UserMapper {
List<User> selectByPage(@Param("offset") Integer offset,
@Param("pageSize")Integer pageSize);
}
<select id="selectByPage" resultMap="userResultMap">
select * from user limit #{offset},#{pageSize}
</select>
方法三、使用map
//接口
public interface UserMapper {
List<User> selectByPage(Map<String,Object> map);
}
<select id="selectByPage" resultMap="userResultMap">
select * from user limit #{offset},#{pageSize}
</select>
//测试
SqlSessionFactory factory = MyBatisUtil.getFactory();
SqlSession sqlSession = factory.openSession();
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
Map<String, Object> map = new HashMap<>();
map.put("offset",1);
map.put("pageSize",2);
List<User> users = mapper.selectByPage(map);
插入
public interface UserMapper {
void insertUser(User user);
}
<insert id="insertUser" parameterType="pojo.User">
insert into user (nick_name, user_name, password, phone)
values (#{nickName},#{userName},#{password},#{phone})
</insert>
SqlSessionFactory factory = MyBatisUtil.getFactory();
SqlSession sqlSession = factory.openSession();
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
mapper.insertUser(new User("kk","7895462","assddws",124));
//手动提交
sqlSession.commit();
获取插入数据的自增id
方法一
useGeneratedKeys="true" keyProperty="id"
<insert id="insertUser" parameterType="pojo.User" useGeneratedKeys="true" keyProperty="id">
方法二
在mybatis配置文件中配置
<settings>
<setting name="useGeneratedKeys" value="true"/>
</settings>
再到mapper文件里
<insert id="insertUser" parameterType="pojo.User" keyProperty="id">
动态更新语句
//接口方法
void updateByUserName(User user);
<update id="updateByUserName" parameterType="pojo.User">
update user
<set>
<if test="nickName != null">
nick_name=#{nickName},
</if>
<if test="password != null">
password=#{password},
</if>
<if test="phone != null">
phone=#{phone}
</if>
</set>
where user_name = #{userName}
</update>
set 元素会动态地在行首插入 SET 关键字,并会删掉额外的逗号
(这些逗号是在使用条件语句给列赋值时引入的)
删除
<delete id="deleteByUserName" parameterType="string">
delete from user where user_name = #{userName}
</delete>
动态SQL
官方文档有详细的解释
以下为例子:
<if></if>
if 在满足条件时会保留sql语句,否则不会
<select id="findCustomerByNameAndJobs" resultType="map" parameterType="pojo.Customer">
select * from t_customer where 1=1
<if test="username != null and username !=''">
and username like concat('%',#{username},'%')
</if>
<if test="jobs != null and jobs !=''">
and jobs = #{jobs}
</if>
</select>
<choose>
<when></when>
<when></when>
<otherwise></otherwise>
</choose>
对每一个when都会进行像if一样的判断,如果没有一个when满足条件,otherwise则会生效
<select id="findCustomerByNameOrJobs" parameterType="pojo.Customer" resultType="map">
select * from t_customer where 1=1
<choose>
<when test="username != null and username !=''">
and username like concat('%',#{username},'%')
</when>
<when test="jobs != null and jobs !=''">
and jobs like concat('%',#{jobs},'%')
</when>
<otherwise>
and phone is not null
</otherwise>
</choose>
</select>
<trim prefix="where" prefixOverrides="and"></trim>
trim里面有内容,则prefix会生效,且第一个内容的prefixOverrides会被去除
trim可以和if配合使用,也可以和其他元素配合使用
<select id="findCustomerByNameAndJobsTrim" parameterType="pojo.Customer" resultType="map">
select * from t_customer
<trim prefix="where" prefixOverrides="and">
<if test="username !=null and username !=''">
and username like concat('%',#{username},'%')
</if>
<if test="jobs != null and jobs !=''">
and jobs like concat('%',#{jobs},'%')
</if>
</trim>
</select>
<set>
<if></if>
<if></if>
<if></if>
</set>
用于update,<set></set>会在sql上补上set
并且去除<if> username = #{username} ,</if> 里面最后的逗号
<update id="updateCustomerSet" parameterType="pojo.Customer">
update t_customer
<set>
<if test="username != null and username != ''">
username = #{username},
</if>
<if test="jobs != null and jobs !=''">
jobs = #{jobs},
</if>
<if test="phone != null">
phone =#{phone}
</if>
</set>
where id = #{id}
</update>
<foreach item="id" index="index" co11ection="list" open="(" separator="," close=")">
#{id}
</foreach>
item: 配置的是循环中当前的元素
index: 配置的是当前元素在集合的位置下标
<select id="findCustomerByIds" parameterType="list" resultType="map">
select * from t_customer where id in
<foreach item="id" index="index" collection="list"
open="(" separator="," close=")">
#{id}
</foreach>
</select>
性能
一级缓存
是session级别的缓存。默认存在。
当在同一个session范围执行查询时,如果查询相同,第二次查询会从缓存中获取数据。
若在两次查询间,执行了增删改操作,则缓存会被清空。第二次查询会从数据库中查询。
二级缓存
默认关闭。
在不同的session内,进行两次相同的查询,则每次都会独立的去数据库查询。
开启二级缓存:
在mapper文件内添加:<cache/>
实体类中实现序列化接口。
每当有增删改语句执行,缓存会被清空。
一对一、一对多、多对一的关联查询
一对一
例如身份证和人是一一对应的关系。
<!--嵌套查询-->
<resultMap id="IdCardWithPersonResult" type="pojo.Person">
<id property="id" column="id"/>
<result property="name" column="name"/>
<result property="age" column="age"/>
<result property="sex" column="sex"/>
<association property="card" column="card_id" javaType="pojo.IdCard"
select="dao.IdCardDao.findCodeById"/>
</resultMap>
<!--结果映射-->
<resultMap id="IdCardWithPersonResult2" type="pojo.Person">
<id property="id" column="id"/>
<result property="name" column="name"/>
<result property="age" column="age"/>
<result property="sex" column="sex"/>
<association property="card" javaType="pojo.IdCard">
<id property="id" column="card_id"/>
<result property="code" column="code"/>
</association>
</resultMap>
<!--嵌套查询,实际上是执行了两次sql性能较差-->
<select id="selectPersonById" parameterType="integer" resultMap="IdCardWithPersonResult">
select * from tb_person where id = #{id}
</select>
<!--结果映射-->
<select id="selectPersonById2" parameterType="integer" resultMap="IdCardWithPersonResult2">
select p.*,idcard.code
from tb_person p,tb_idcard idcard
where p.card_id = idcard.id
and p.id = #{id}
</select>
<mapper namespace="dao.IdCardDao">
<select id="findCodeById" parameterType="integer" resultType="pojo.IdCard">
select * from tb_idcard where id = #{id}
</select>
</mapper>
控制台输出如下:
嵌套查询
* DEBUG [main] - ==> Preparing: select * from tb_person where id = ?
* DEBUG [main] - ==> Parameters: 1(Integer)
* TRACE [main] - <== Columns: id, name, age, sex, card_id
* TRACE [main] - <== Row: 1, rose, 29, girl, 1
* DEBUG [main] - ====> Preparing: select * from tb_idcard where id = ?
* DEBUG [main] - ====> Parameters: 1(Integer)
* TRACE [main] - <==== Columns: id, code
* TRACE [main] - <==== Row: 1, 429005199904010033
* DEBUG [main] - <==== Total: 1
* DEBUG [main] - <== Total: 1
* Person{id=1, name='rose', age=29, sex='girl', card=IdCard{id=1, code='429005199904010033'}}
结果映射
* DEBUG [main] - ==> Preparing: select p.*,idcard.code from tb_person p,tb_idcard idcard where p.card_id = idcard.id and p.id = ?
* DEBUG [main] - ==> Parameters: 1(Integer)
* TRACE [main] - <== Columns: id, name, age, sex, card_id, code
* TRACE [main] - <== Row: 1, rose, 29, girl, 1, 429005199904010033
* DEBUG [main] - <== Total: 1
* Person{id=1, name='rose', age=29, sex='girl', card=IdCard{id=1, code='429005199904010033'}}
一对多映射
一个用户可以有多个订单。Shopper类中有List<Order> 成员变量
<mapper namespace="dao.ShopperDao">
<!--嵌套查询-->
<resultMap id="shopper1" type="pojo.Shopper">
<id property="id" column="id"/>
<result property="name" column="name"/>
<collection property="orders" column="id" ofType="pojo.Order"
select="dao.OrderDao.findOrderById"/>
</resultMap>
<!--结果查询-->
<resultMap id="shopper2" type="pojo.Shopper">
<id property="id" column="id"/>
<result property="name" column="name"/>
<collection property="orders" ofType="pojo.Order">
<!--这里使用了别名,因为shopper表里也有个id字段-->
<id property="id" column="oreder_id"/>
<result property="number" column="number"/>
</collection>
</resultMap>
<select id="findShopperById" resultMap="shopper1" parameterType="integer">
select * from shopper where id = #{id}
</select>
<select id="findShopperById2" resultMap="shopper2" parameterType="integer">
select shopper.*, o.id as oreder_id ,o.number
from shopper ,tb_orders o
where shopper.id = #{id}
and shopper.id = o.shopper_id
</select>
</mapper>
<mapper namespace="dao.OrderDao">
<select id="findOrderById" resultType="map" parameterType="integer">
select id,number from tb_orders
where shopper_id = #{id}
</select>
</mapper>
控制台输出
* 一个shopper对应多个order
* 使用嵌套查询
* DEBUG [main] - ==> Preparing: select * from shopper where id = ?
* DEBUG [main] - ==> Parameters: 1(Integer)
* TRACE [main] - <== Columns: id, name
* TRACE [main] - <== Row: 1, mark
* DEBUG [main] - ====> Preparing: select id,number from tb_orders where shopper_id = ?
* DEBUG [main] - ====> Parameters: 1(Integer)
* TRACE [main] - <==== Columns: id, number
* TRACE [main] - <==== Row: 1, 1001
* TRACE [main] - <==== Row: 3, 1002
* DEBUG [main] - <==== Total: 2
* DEBUG [main] - <== Total: 1
* Shopper{id=1, name='mark', orders=[{number=1001, id=1}, {number=1002, id=3}]}
* 使用结果映射
* DEBUG [main] - ==> Preparing: select shopper.*, o.id as oreder_id ,o.number from shopper ,tb_orders o where shopper.id = ? and shopper.id = o.shopper_id
* DEBUG [main] - ==> Parameters: 1(Integer)
* TRACE [main] - <== Columns: id, name, oreder_id, number
* TRACE [main] - <== Row: 1, mark, 1, 1001
* TRACE [main] - <== Row: 1, mark, 3, 1002
* DEBUG [main] - <== Total: 2
* Shopper{id=1, name='mark', orders=[Order{id=1, number='1001'}, Order{id=3, number='1002'}]}
多对多
商品和订单
多对多关系由中间表orderitem来维护,每一行为order_id,product_id
<!--detailOrder组建:包含一个Order对象和List<Product>-->
<!--嵌套查询-->
<resultMap id="do1" type="pojo.OrderDetail">
<id property="order.id" column="id"/>
<result property="order.number" column="number"/>
<collection property="products" ofType="pojo.Product" column="id" select="dao.ProductDao.findProductByOrderId"/>
</resultMap>
<!--结果映射-->
<resultMap id="do2" type="pojo.OrderDetail">
<id property="order.id" column="id"/>
<result property="order.number" column="number"/>
<collection property="products" ofType="pojo.Product">
<id property="id" column="pid"/>
<result property="name" column="name"/>
<result property="price" column="price"/>
</collection>
</resultMap>
<select id="findOrderWithProduct1" parameterType="integer" resultMap="do1">
select * from tb_orders
where id = #{id}
</select>
<select id="findOrderWithProduct2" parameterType="integer" resultMap="do2">
select o.*,p.id as pid,p.name,p.price
from tb_orders o,tb_product p,orderitem oi
where o.id = #{id}
and oi.order_id = o.id
and oi.product_id = p.id
</select>
<mapper namespace="dao.ProductDao">
<select id="findProductByOrderId" resultType="map" parameterType="integer">
select * from tb_product
where id in (
select product_id from orderitem where order_id = #{id}
)
</select>
</mapper>
控制台输出
* 使用嵌套查询
* DEBUG [main] - ==> Preparing: select * from tb_orders where id = ?
* DEBUG [main] - ==> Parameters: 1(Integer)
* TRACE [main] - <== Columns: id, number, shopper_id
* TRACE [main] - <== Row: 1, 1001, 1
* DEBUG [main] - ====> Preparing: select * from tb_product where id in ( select product_id from orderitem where order_id = ? )
* DEBUG [main] - ====> Parameters: 1(Integer)
* TRACE [main] - <==== Columns: id, name, price
* TRACE [main] - <==== Row: 1, phone, 8848
* TRACE [main] - <==== Row: 2, aircondition, 8848
* DEBUG [main] - <==== Total: 2
* DEBUG [main] - <== Total: 1
* OrderDetail{order=Order{id=1, number='1001'}, products=[Product{id=1, name='phone', price=8848.0}, Product{id=2, name='aircondition', price=8848.0}]}
* 使用结果映射
* DEBUG [main] - ==> Preparing: select o.*,p.id as pid,p.name,p.price from tb_orders o,tb_product p,orderitem oi where o.id = ? and oi.order_id = o.id and oi.product_id = p.id
* DEBUG [main] - ==> Parameters: 1(Integer)
* TRACE [main] - <== Columns: id, number, shopper_id, pid, name, price
* TRACE [main] - <== Row: 1, 1001, 1, 1, phone, 8848
* TRACE [main] - <== Row: 1, 1001, 1, 2, aircondition, 8848
* DEBUG [main] - <== Total: 2
* OrderDetail{order=Order{id=1, number='1001'}, products=[Product{id=1, name='phone', price=8848.0}, Product{id=2, name='aircondition', price=8848.0}]}
鉴别器
根据查询结果的某一栏,来确定哪个属性值或者resultMap被加载。
<!--根据vehicle_type的值决定哪个属性字段被映射-->
<resultMap id="vehicleResult" type="Vehicle">
<id property="id" column="id" />
<result property="vin" column="vin"/>
<result property="year" column="year"/>
<discriminator javaType="int" column="vehicle_type">
<case value="1" resultType="carResult">
<result property="doorCount" column="door_count" />
</case>
<case value="2" resultType="truckResult">
<result property="boxSize" column="box_size" />
<result property="extendedCab" column="extended_cab" />
</case>
</discriminator>
</resultMap>
选择指定resultMao被加载请看文档。
构造器映射
让resultMap使用构造器进行映射。
注意事项:
1.必须写明 javaType。可以想象,底层借由反射去寻找相应的构造函数。
2.参数顺序要和构造函数的参数顺序匹配。不然会错位映射。
3.依然可以添加其他节点到resultMap,如 <result />
<resultMap id="userConstructor" type="pojo.User">
<constructor>
<idArg column="user_name" javaType="String"/>
<arg column="nick_name" javaType="String"/>
<arg column="password" javaType="String"/>
<arg column="phone" javaType="Integer"/>
</constructor>
</resultMap>
延迟加载
假设有这样一种业务情况:
一篇博客Blog对应一个作者Author。Blog类依赖Author类。
你写了一条关联查询语句(<association />),在查出Blog后(第一次查询)会根据author_id查询Author(第二次)。
1、积极加载。(默认开启)
在调用关联查询语句时,无论后续业务是否用到了Author,都会进行第二次查询。
2、积极的延迟加载。
在mybatis配置文件中添加:
<settings>
<setting name="lazyLoadingEnabled" value="true"/>
<setting name="aggressiveLazyLoading" value="true"/>
</settings>
只要业务使用了属于Blog类的属性,第二次查询就会在使用前被执行。
3、非积极的延迟加载
在mybatis配置文件中添加:
<settings>
<setting name="lazyLoadingEnabled" value="true"/>
<setting name="aggressiveLazyLoading" value="false"/>
</settings>
只有在业务中使用了Author的属性前,才会执行第二次查询。使用Blog的属性,不会引起第二次查询。
注意:lazyLoadingEnabled和aggressiveLazyLoading有自己默认的属性,但在不同的版本默认值不一样,所以为了正确使用,还是显示给出配置,而非使用默认值。
#和$的区别
mybatis中的#和$的区别:
1、#将传入的数据都当成一个字符串,会对自动传入的数据加一个双引号。
如:where username=#{username},如果传入的值是111,那么解析成sql时的值为where username="111", 如果传入的值是id,则解析成的sql为where username="id".
2、$将传入的数据直接显示生成在sql中。
如:where username=${username},如果传入的值是111,那么解析成sql时的值为where username=111;
如果传入的值是:drop table user;,则解析成的sql为:select id, username, password, role from user where username=;drop table user;
3、#方式能够很大程度防止sql注入,$方式无法防止Sql注入。
4、$方式一般用于传入数据库对象,例如传入表名.
5、一般能用#的就别用$,若不得不使用“${xxx}”这样的参数,要手工地做好过滤工作,来防止sql注入攻击。
6、在MyBatis中,“${xxx}”这样格式的参数会直接参与SQL编译,从而不能避免注入攻击。但涉及到动态表名和列名时,只能使用“${xxx}”这样的参数格式。所以,这样的参数需要我们在代码中手工进行处理来防止注入。
【结论】在编写MyBatis的映射语句时,尽量采用“#{xxx}”这样的格式。若不得不使用“${xxx}”这样的参数,要手工地做好过滤工作,来防止SQL注入攻击。
jdbcType和javaType对照表
| jdbcType | 映射的类型 |
|---|---|
| _byte | byte |
| _long | long |
| _short | short |
| _int | int |
| _integer | int |
| _double | double |
| _float | float |
| _boolean | boolean |
| string | String |
| byte | Byte |
| long | Long |
| short | Short |
| int | Integer |
| integer | Integer |
| double | Double |
| float | Float |
| boolean | Boolean |
| date | Date |
| decimal | BigDecimal |
| bigdecimal | BigDecimal |
| object | Object |
| map | Map |
| hashmap | HashMap |
| list | List |
| arraylist | ArrayList |
| collection | Collection |
| iterator | Iterator |














 1296
1296











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









