






- equals
对于基本数据类型
==:比较值
对于复合数据类型(类)
==:内存中的存放地址
equals:继承object或者自己重写覆盖
object中采用双等号比较内存中的存放位置的地址值
public boolean equals(Object obj) {
return (this == obj);
}
- 放在集合里的元素要重写equals方法
- 当集合的结构发生改变时,迭代器必须重新获取,如果还使用原来的迭代器会出现异常 java.util.ConcurrentModificationException。
- 不能迭代时调用collection的remove方法,但是可以调用迭代器的remove方法
- list集合存储元素特点:有序可重复 有序-有下标,从0开始递增
- 通过for循环下标遍历是list特有的方法,set、map没有,因为只有list是有序的
- 接口与抽象类
抽象类和接口的区别,使用场景 - JDK8的ArrayList 默认初始化容量10(底层先创建一个长度为0的数组,当添加第一个元素的时候,初始化容量为10)-只知道JDK8是这样
底层先创建一个长度为0的数组
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
长度为0的数组
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
添加第一个元素的时候,初始化容量为10
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity) {
第一次加入的时候进入if
然后取DEFAULT_CAPACITY=10和minCapacity的最大值
minCapacity是元素个数
注意元素个数是size 容量是数组长度length
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
- modCount记录的是list被修改的次数,由迭代器使用
modCount - 因为数组扩容效率低,建议使用ArrayList集合时,估计元素的个数给定一个初始化容量。
就是说如果直接 new ArrayList()再一个add那么可能会存在多次扩容操作,所以采用preferred growth->oldCapacity/2可以一次多扩容,减少扩容次数。
如果使用new ArrayList(n) 那么就没有扩容操作 - 数组优点:检索效比较高, 向数组末尾添加元素,效率很高(因为数组地址连续,便于找到放进去),不受影响
- 缺点:随机增删效率比较低,不能存储大数据量,因为很难找到一块非常巨大的连续的空闲内存空间
- 所以常用的集合是ArrayList
- 链表优点:随机增删元素效率较高(因为不涉及到大量元素位移)
- 链表缺点:查询效率低,因为每一次都要从头节点开始遍历
- ArrayList是非线程安全的集合
- vector初始化容量10
- ArraysSupport newLength(int oldLength, int minGrowth, int prefGrowth) 方法,计算新的数组大小。简单来说,结果就是 Math.max(minGrowth, prefGrowth) + oldLength ,按照 minGrowth 和 prefGrowth 取大的。
- ArrayList的prefGrowth是0.5倍,vector是一倍
private Object[] grow(int minCapacity) {
int oldCapacity = elementData.length;
int newCapacity = ArraysSupport.newLength(oldCapacity,
minCapacity - oldCapacity, /* minimum growth */
oldCapacity就是说为设定capacityIncrement值,默认为0时,增长为oldCapacity+oldCapacity
capacityIncrement > 0 ? capacityIncrement : oldCapacity
/* preferred growth */);
return elementData = Arrays.copyOf(elementData, newCapacity);
}
- 向上转型、向下转型
向上转型 : 通过子类对象(小范围)实例化父类对象(大范围),这种属于自动转换
向下转型 : 通过父类对象(大范围)实例化子类对象(小范围),这种属于强制转换,需要使用instanceof - 泛型
优点:从集合中取出的元素类型是泛型指定的类型,不需要大量的“向下转型”
缺点:导致集合中存储的元素缺乏多样性 - 泛型是编译阶段的功能,与运行阶段没关系
- hashset 无序(无index)、不可重复、实际是放在hashMap集合的key部分
- treeset 无序、不可重复、但会按大小排序、实际是放在TreeMap…
- 自动装箱拆箱
- 内部类
- class加不加public
- 为什么public的类名和文件名要一样
- map的遍历方式
- Comparable和Comparator的区别
comparable 外比较器
comparator 内比较器 - 重点,记住:HashMap集合初始化容量必须是2的倍数,这也是官方推荐的,这是因为达到散列均匀,为了提高HashMap集合的存取效率,所必须的。
- 如果一个类的equals方法重写了,那么hashcode方法必须重写(只是hash表结构?)
public class maptest02 {
public static void main(String[] args) {
student s1=new student(12,"zhangsan");
student s2=new student(12,"lisi");
System.out.println(s1.hashCode()==s2.hashCode());
System.out.println(s1.equals(s2));
}
}
class student{
int age;
String name;
public student(int age, String name) {
this.age = age;
this.name = name;
}
public student() {
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
student student = (student) o;
return age == student.age;
}
}
结果:
false
true
equal但是hashcode不等
- hashtable的key和value都不可以为null
- hashmap的key和value都可以为null
- Properties是一个Map集合,继承Hashtable,Properties的key和value都是String类型。
- TreeSet集合底层实际上是一个TreeMap
- TreeMap集合底层是一个二叉树。
- 放到TreeSet集合中的元素,等同于放到TreeMap集合key部分了
- 多继承、接口与抽象类
- 凡是双引号的都在字符串常量池中有一份,就是创建了对象
- new对象时一定在堆内存开辟空间
- String比较
==比较的是变量中的内容
【加个内存图】
package com.yst.javase.String;
public class stringTest01 {
public static void main(String[] args) {
String a="abc";
String c="abc";
System.out.println(a);
System.out.println(c);
System.out.println(a==c);//true
System.out.println(a.equals(c));//true
a=new String("abc");
c=new String("abc");
System.out.println(a);
System.out.println(c);
System.out.println(a==c);//false
System.out.println(a.equals(c));//true
a=new String("abc");
c="abc";
System.out.println(a);
System.out.println(c);
System.out.println(a==c);//false
System.out.println(a.equals(c));//true
}
}
- 垃圾回收器不会释放常量池
- Object的toString()方法,会自动输出对象的内存地址,是变量中存储的对象的内存地址
- 判断数组长度是length属性,判断字符串长度是length()方法
- java面试题
【加个内存图】
// 这两行代码表示底层创建了3个字符串对象,都在字符串常量池当中。
String s1 = "abcdef";
String s2 = "abcdef" + "xy";
- 技巧
String k = new String("testString");
// "testString"这个字符串可以后面加"."呢?
// 因为"testString"是一个String字符串对象。只要是对象都能调用方法。
"testString".equals(k) // 建议使用这种方式,因为这个可以避免空指针异常。
k.equals("testString") // 存在空指针异常的风险。不建议这样写。
-
byte,即字节,由8位的二进制组成。在Java中,byte类型的数据是8位带符号的二进制数。
-
在计算机中,8位带符号二进制数的取值范围是[-128, 127],所以在Java中,byte类型的取值范围也是[-128, 127]。
-
编码(由看得懂到看不懂):字符串变字节数组
解码(由看不懂到看得懂):字符数组变字符串
String–》byte[];//str.getBytes();//str.getBytes(String CharsetName);
byte[]–》String;//new String(byte[] bytes)//new String(byte[] bytes,String CharsetName); -
面试题:String为什么是不可变的?
我看过源代码,String类中有一个byte[]数组,这个byte[]数组采用了final修饰,
因为数组一旦创建长度不可变。并且被final修饰的引用一旦指向某个对象之后,不可再指向其它对象,所以String是不可变的!
“abc” 无法变成 “abcd” -
StringBuilder/StringBuffer为什么是可变的呢?
我看过源代码,StringBuffer/StringBuilder内部实际上是一个byte[]数组,
这个byte[]数组没有被final修饰,StringBuffer/StringBuilder的初始化
容量我记得应该是16,当存满之后会进行扩容,底层调用了数组拷贝的方法
System.arraycopy()…是这样扩容的。所以StringBuilder/StringBuffer
适合于使用字符串的频繁拼接操作。 -
StringBuffer和StringBuilder的区别?
StringBuffer中的方法都有:synchronized关键字修饰。表示StringBuffer在多线程环境下运行是安全的。
StringBuilder中的方法都没有:synchronized关键字修饰,表示StringBuilder在多线程环境下运行是不安全的。StringBuffer是线程安全的。
StringBuilder是非线程安全的。 -
整数型常量池
java中为了提高程序的执行效率,将[-128,127]之间所有的包装对象提前创建好,放到了一个方法区的“整数型常量池”当中了,目的是只要用这个区间的数据不需要再new了,直接从整数型常量池当中取出来。
于是[-128,127]之间的Integer地址是一样的
Integer a=100;
Integer b=100;
System.out.println(a==b);//true
System.out.println(a.equals(b));//true
a=200;
b=200;
System.out.println(a==b);//false
System.out.println(a.equals(b));//true
- String int Integer之间互相转换
// String --> int
int i1 = Integer.parseInt("100"); // i1是100数字
System.out.println(i1 + 1); // 101
// int --> String
String s2 = i1 + ""; // "100"字符串
System.out.println(s2 + 1); // "1001"
// int --> Integer
// 自动装箱
Integer x = 1000;
// Integer --> int
// 自动拆箱
int y = x;
// String --> Integer
Integer k = Integer.valueOf("123");
// Integer --> String
String e = String.valueOf(k);
- 知识点1:怎么获取系统当前时间
Date nowTime = new Date();
- 知识点2:String —> Date
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss SSS");
String nowTimeStr = sdf.format(nowTime);
yyyy 年(年是4位)
MM 月(月是2位)
dd 日
HH 时
mm 分
ss 秒
SSS 毫秒(毫秒3位,最高999。1000毫秒代表1秒)
注意:在日期格式中,除了y M d H m s S这些字符不能随便写之外,剩下的符号格式自己随意组织。
- 知识点3:Date —> String
String time = "2008-08-08 08:08:08 888";
//SimpleDateFormat sdf2 = new SimpleDateFormat("格式不能随便写,要和日期字符串格式相同");
// 注意:字符串的日期格式和SimpleDateFormat对象指定的日期格式要一致。不然会出现异常:java.text.ParseException
SimpleDateFormat sdf2 = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss SSS");
Date dateTime = sdf2.parse(time);
- 简单总结一下System类的相关属性和方法:
System.out 【out是System类的静态变量。】
System.out.println() 【println()方法不是System类的,是PrintStream类的方法。】
System.gc() 建议启动垃圾回收器
System.currentTimeMillis() 获取自1970年1月1日到系统当前时间的总毫秒数。
System.exit(0) 退出JVM。
- BigDecimal 属于大数据,精度极高。
不属于基本数据类型,属于java对象(引用数据类型)
这是SUN提供的一个类。专门用在财务软件当中 - 数字格式化
数字格式有哪些?
# 代表任意数字
, 代表千分位
. 代表小数点
0 代表不够时补0
###,###.##
表示:加入千分位,保留2个小数。
*/
DecimalFormat df = new DecimalFormat("###,###.##");
//String s = df.format(1234.56);
String s = df.format(1234.561232);
System.out.println(s); // "1,234.56"
DecimalFormat df2 = new DecimalFormat("###,###.0000"); //保留4个小数位,不够补上0
String s2 = df2.format(1234.56);
System.out.println(s2); // "1,234.5600"
- java.io.InputStreamReader
想读字节文件为字符时用
InputStream-输入的是字节流
Readed-读到的是字符
前半句是流 后半句是内存
bfr=new BufferedReader(new InputStreamReader(new FileInputStream("frtest")));
String s=null;
while ((s=bfr.readLine())!=null){
System.out.println(s);
}
- java.io.OutputStreamWriter
写字符到字节流
OutputStream-输出的是字节流
Writer-写的是字符
bfw=new BufferedWriter(new OutputStreamWriter(new FileOutputStream("fostest")));
bfw.write("去你大爷的");
bfw.write("去你大爷的");
-
如果需要判断包含 采用hash表 通过hashcode()可以快速判断
HashSet不能添加重复的元素,当调用add(Object)方法时候,
首先会调用Object的hashCode方法判hashCode是否已经存在,如不存在则直接插入元素;
如果已存在则调用Object对象的equals方法判断是否返回true,如果为true则说明元素已经存在,如为false则插入元素。 -
队列的offer和add的区别
区别:两者都是往队列尾部插入元素,不同的时候,当超出队列界限的时候,
add()方法是抛出异常让你处理,
offer()方法是直接返回false
-队列中 poll和remove的区别
Queue 中 remove() 和 poll()都是用来从队列头部删除并获取一个元素。
在队列元素为空的情况下,
remove() 方法会抛出NoSuchElementException异常
poll() 方法只会返回 null 。 -
PriorityQueue
优先队列的底层是基于堆排序
按照对象实现的比较器 -
集合里面的线程安全问题
collection- Array - vector 底层和ArrayList都是数组实现的 但是是线程安全的
- Set -没有
map
- map-hashtable 底层和hashmap一样是哈希表实现的 但是是线程安全的
collections包装器

collection+List+(sorted)map+(sorted)set -
基本数据类型字节占用
1个字节-boolean、byte
2个字节-short、char
4个字节-int,float
8个字节-double、long -
foreach
foreach语句是java5的新特征之一,在遍历数组、集合方面,foreach为开发人员提供了极大的方便。 -
iterable和iterator的区别
Iterable:接口。由英文的命名规则知道,后缀是able的意思就是可怎么样的,因此iterable就是可迭代的意思。
Iterator:接口。由英文的命名规则知道,后缀是or或者er的都是指代名词,所以iterator的意思是迭代器。

iterator
是一个接口
package java.util;
public interface Iterator
{
public abstract boolean hasNext();
public abstract Object next();
public abstract void remove();
}
ArrayList中对iterator
private class Itr implements Iterator<E> {
int cursor; // index of next element to return
int lastRet = -1; // index of last element returned; -1 if no such
int expectedModCount = modCount;
public boolean hasNext() {
return cursor != size;
}
@SuppressWarnings("unchecked")
public E next() {
checkForComodification();
int i = cursor;
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData[lastRet = i];
}
public void remove() {
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
try {
ArrayList.this.remove(lastRet);
cursor = lastRet;
lastRet = -1;
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
- 高并发的三大特性—原子性、有序性、可见性
添加链接描述 - 同步
线程以原子的形式修改变量 - 自动装箱/自动拆箱
添加链接描述
自动装箱:Integer b=a; 这段代码等同于:Integer b=Integer.valueOf ( a )
public static Integer valueOf(int i) {
if (i >= -128 && i <= 127)
return IntegerCache.cache[i + 127];
//如果i的值大于-128小于127则返回一个缓冲区中的一个Integer对象
return new Integer(i);
//否则返回 new 一个Integer 对象
}
自动拆箱:int a=b,这段代码等价于:int a=b.intValue()
public int intValue() {
return value;
}
-数据类型


-clone
就是之前做那个子树那样
浅拷贝/深拷贝 clone
程序执行到new操作符时, 首先去看new操作符后面的类型,因为知道了类型,才能知道要分配多大的内存空间。分配完内存之后,再调用构造函数,填充对象的各个域,这一步叫做对象的初始化,构造方法返回后,一个对象创建完毕,可以把他的引用(地址)发布到外部,在外部就可以使用这个引用操纵这个对象。而clone在第一步是和new相似的, 都是分配内存,调用clone方法时,分配的内存和源对象(即调用clone方法的对象)相同,然后再使用原对象中对应的各个域,填充新对象的域, 填充完成之后,clone方法返回,一个新的相同的对象被创建,同样可以把这个新对象的引用发布到外部。

clone是浅拷贝的

-
加载器图

-
类加载
添加链接描述
当程序主动使用某个类时,如果该类还未被加载到内存中,则JVM会通过加载、连接、初始化3个步骤来对该类进行初始化。如果没有意外,JVM将会连续完成3个步骤,所以有时也把这个3个步骤统称为类加载或类初始化(与步骤中的加载初始化进行区分)

-
双亲委派机制
package java.lang;
public class String {
@Override
public java.lang.String toString() {
return "不是我o";
}
public static void main(String[] args) {
String a =new String();
System.out.println(a.toString());
}
}


双亲委派模式优势
避免重复加载 + 避免核心类篡改
采用双亲委派模式的是好处是Java类随着它的类加载器一起具备了一种带有优先级的层次关系,通过这种层级关可以避免类的重复加载,当父亲已经加载了该类时,就没有必要子ClassLoader再加载一次。其次是考虑到安全因素,java核心api中定义类型不会被随意替换,假设通过网络传递一个名为java.lang.Integer的类,通过双亲委托模式传递到启动类加载器,而启动类加载器在核心Java
API发现这个名字的类,发现该类已被加载,并不会重新加载网络传递的过来的java.lang.Integer,而直接返回已加载过的Integer.class,这样便可以防止核心API库被随意篡改。
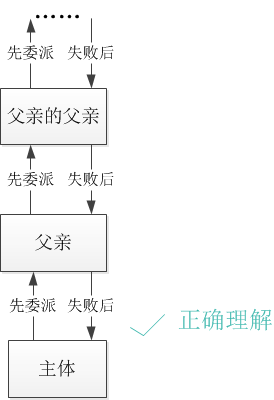
双亲委派模型工作工程:
1.当Application ClassLoader 收到一个类加载请求时,他首先不会自己去尝试加载这个类,而是将这个请求委派给父类加载器Extension ClassLoader去完成。
2.当Extension ClassLoader收到一个类加载请求时,他首先也不会自己去尝试加载这个类,而是将请求委派给父类加载器Bootstrap
ClassLoader去完成。3.如果Bootstrap ClassLoader加载失败(在<JAVA_HOME>\lib中未找到所需类),就会让Extension ClassLoader尝试加载。
4.如果Extension ClassLoader也加载失败,就会使用Application ClassLoader加载。
5.如果Application ClassLoader也加载失败,就会使用自定义加载器去尝试加载。
- 反射获取结构的一点总结
//类名
//属性-有父类
//方法-有父类
//构造器-无父类
//getDeclaredxxx-自己所有
//getxxx-可能有父类
//s-列表
//不加s-需要指定 属性:名 方法:名+参数类型
- Entry
map的内部接口
添加链接描述
一.java中Map及Map.Entry
(1).Map是java中的接口,Map.Entry是Map的一个内部接口。
(2).Map提供了一些常用方法,如keySet()、entrySet()等方法。
(3).keySet()方法返回值是Map中key值的集合;entrySet()的返回值也是返回一个Set集合,此集合的类型为Map.Entry。
(4).Map.Entry是Map声明的一个内部接口,此接口为泛型,定义为Entry<K,V>。它表示Map中的一个实体(一个key-value对)。接口中有getKey(),getValue方法。

- hashMap的存储结构是 Map.Entry<K,V>数组
- Java中几种常用的队列
阻塞队列-和线程相关
阻塞队列与普通队列的区别在于,当队列是空的时,从队列中获取元素的操作将会被阻塞,或者当队列是满时,往队列里添加元素的操作会被阻塞。试图从空的阻塞队列中获取元素的线程将会被阻塞,直到其他的线程往空的队列插入新的元素。同样,试图往已满的阻塞队列中添加新元素的线程同样也会被阻塞,直到其他的线程使队列重新变得空闲起来,如从队列中移除一个或者多个元素,或者完全清空队列.
添加链接描述
Queue<Integer> q1=new LinkedList<>();
采用linkedList<>
- ConcurrentHashMap和hashMap在entry上的区别

static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;

- 迭代器的强一致性和弱一致性
HashMap是强一致性
ConcurrentHashMap是弱一致性
迭代时,迭代过的内容发生改变,迭代器无反应
未迭代的内容发生改变,会有反应
弱一致性的好处是,迭代器线程可以基于原本的内容遍历,同时写线程可以修改内容,达到性能提升

















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









