







一、概述
由Facebook开源用于解决海量结构化日志的数据统计工具
Hive是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。 Hive 查询操作过程严格遵守Hadoop MapReduce 的作业执行模型,Hive 将用户的HiveQL 语句通过解释器转换为提交到Hadoop 集群上,Hadoop 监控作业执行过程,然后返回作业执行结果给用户。 Hive 并非为联机事务处理而设计,Hive 并不提供实时的查询和基于行级的数据更新操作。Hive 的最佳使用场合是大数据集的批处理作业,例如,网络日志分析。

Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。同时,Hive也是建立在Hadoop上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),并且提供了存储、查询和分析Hadoop中的大规模数据的机制。Hive定义了简单的类SQL查询语言,称为HQL,它允许熟悉SQL的用户查询数据。这个语言也允许熟悉MapReduce的开发者的设计自定义的Mapper和Reducer来处理内建的Mapper和Reducer无法完成的复杂的分析工作。
Hive的命令行接口和关系数据库的命令行接口类似,但是Hive和关系数据库还是有很大的不同,主要体现在以下几点:(重点)
- Hive和关系数据库存储文件的系统不同,Hive使用的是Hadoop的HDFS,关系数据库则是服务器本地的文件系统。
- Hive使用的计算模型是MapReduce,而关系数据库则是自己设计的计算模型。
- 关系数据库都是为实时查询的业务进行设计的,而Hive则是为海量数据做数据挖掘设计的,实时性很差,实时性的区别导致Hive的应用场景和关系数据库有很大的不同。
- Hive很容易扩展自己的存储能力和计算能力,这个是继承Hadoop的特性,而关系数据库在这个方面要比Hive差很多。
二、Hive 安装
2.1 环境依赖
- 需要HDFS和MR就绪
- 需要安装Mysql服务并且启动远程连接
# 其中的一种安装方式
[root@ZK01 ~]# yum install -y mysql-server
[root@ZK01 ~]# service mysqld start
[root@ZK01 ~]# mysqladmin -uroot password 'root'
[root@ZK01 ~]# mysql -uroot -proot
mysql> use mysql
Database changed
mysql> delete from user where password='';
mysql> grant all privileges on *.* to 'root'@'%' identified by 'root' with grant option;
mysql> flush privileges;
# 需要自己创建Hive 数据库
mysql> create database hive;
mysql> show database;
# 自动安装的方式
MySQL-server-5.5.62-1.el6.x86_64.rpm
MySQL-client-5.5.62-1.el6.x86_64.rpm
在软件包找到上述的两个文件 将其拷贝到/root/app/
执行下面的命令即可 按照提示安装
[root@ZK01 app]# bash <(curl -s -k -L https://raw.githubusercontent.com/GuoJiafeng/ShellScript/master/src/main/resources/onekeyInstall/mysqlInstaller.sh)
2.2 安装配置Hive
[root@HadoopNode00 ~]# mkdir /home/hive
[root@HadoopNode00 ~]# tar -zxvf apache-hive-1.2.1-bin.tar.gz -C /home/hive/
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://HadoopNode00:3306/hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>1234</value>
</property>
</configuration>
2.3 拷贝相关依赖
- 将mysqljar包拷贝进入到hive安装目录下lib目录
- 拷贝/home/hive/apache-hive-1.2.1-bin/lib/的jline-2.12.jar到/home/hadoop/hadoop-2.6.0/share/hadoop/yarn/lib/下,删除原来的旧的版本的jar包
2.4 配置环境变量
[root@HadoopNode00 ~]# vi .bashrc
export HIVE_HOME=/home/hive/apache-hive-1.2.1-bin
export PATH=$PATH:$HIVE_HOME/bin
[root@HadoopNode00 ~]# source .bashrc
2.5 启动
(1)单机
[root@HadoopNode00 ~]# hive
Logging initialized using configuration in jar:file:/home/hive/apache-hive-1.2.1-bin/lib/hive-common-1.2.1.jar!/hive-log4j.properties
hive> show databases;
OK
default
Time taken: 0.585 seconds, Fetched: 1 row(s)
hive> create database baizhi;
OK
Time taken: 0.077 seconds
hive> show databases;
OK
baizhi
default
Time taken: 0.007 seconds, Fetched: 2 row(s)
[root@HadoopNode00 bin]# hive -e 'show databases;'
Logging initialized using configuration in jar:file:/home/hive/apache-hive-1.2.1-bin/lib/hive-common-1.2.1.jar!/hive-log4j.properties
OK
baizhi
default
Time taken: 0.749 seconds, Fetched: 2 row(s)
(2)HiveServer2 (JDBC服务)
# hiveserver2 服务为前台挂起服务
[root@HadoopNode00 bin]# hiveserver2
[root@HadoopNode00 ~]# beeline -u jdbc:hive2://$HOSTNAME:10000 -n root
三、Hive 表操作
3.1 Hive 数据类型
数据类型数据类型
-
原始数据类型(primitive)
- 整数:TINYINT SMALLINT INT BIGINT
- 布尔:BOOLEAN
- 小数:FLOAT,DOUBLE
- 字符:STRING CHAR VARCHAR
- 二进制:BINARY
- 时间:DATE
-
数组类型(array):array<数据类型>
-
key-value类型(map):map(原始类型,数据类型)
-
结构体类型(struct):struct,<字段名:数据类型,…>
3.2 创建表
create table t_user(
id int,
name string,
birthday date,
salary double,
hobbies array<string>,
card map<string,string>,
address struct<country:string,city:string>
)
3.3 默认分隔符
| 分割符 | 描述 |
|---|---|
| \n 换行符 | 对于文本来说,每一行就是一条记录 因此\n 就是分割记录 |
| ^A | \001 用于分割字段 |
| ^B | \002 用于分割array或者struct中的元素 | 用于map结构中k-v对的分隔符 |
| ^C | \003 用于map中k-v的分隔符 |

3.4 数据导入
# 第一种 不常用
# 将准备好的结构化(符合表的分隔符的条件) 传入到hdfs中对应的表目录中
[root@HadoopNode00 ~]# hadoop fs -put t_user /user/hive/warehouse/baizhi.db/t_user
# 第二种 经常用
# 直接在hive line 中load data 即可
jdbc:hive2://HadoopNode00:10000> load data local inpath '/root/t_user' overwrite into table t_user;
3.5 JDBC 访问Hive
package com.baizhi;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class App {
public static void main(String[] args) throws Exception {
/*
*获取连接
* */
Class.forName("org.apache.hive.jdbc.HiveDriver");
Connection connection = DriverManager.getConnection("jdbc:hive2://HadoopNode00:10000/baizhi", "root", null);
Statement statement = connection.createStatement();
ResultSet resultSet = statement.executeQuery("select name from t_user");
while (resultSet.next()) {
String name = resultSet.getString("name");
System.out.println(name);
}
resultSet.close();
statement.close();
connection.close();
}
}
3.6 自定义分隔符
create table t_user_c(
id int,
name string,
birthday date,
salary double,
hobbies array<string>,
card map<string,string>,
address struct<country:string,city:string>
)
row format delimited
fields terminated by ','
collection items terminated by '|'
map keys terminated by '>'
lines terminated by '\n';
1,zhangsan,2018-10-10,1000.0,TV|Game,jiangshe>001|zhaoshang>002,china|bj
# 如果向load hdfs 上的数据 去掉loacl 即可
load data local inpath '/root/t_user_c' into table t_user_c;
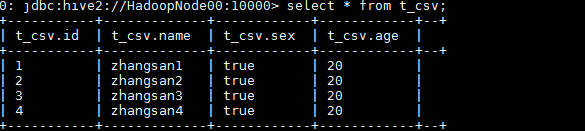
3.7 CSV 文件
create table t_csv(
id int,
name string,
sex boolean,
age int
)
row format serde 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
with serdeproperties(
"separatorChar" = ",",
"escapeChar" = "\\"
)
1,zhangsan1,true,20
2,zhangsan2,true,20
3,zhangsan3,true,20
4,zhangsan4,true,20
load data local inpath '/root/t_csv' into table t_csv;
3.8 JSON 格式数据
# 在创建之前需要先在hive中引入此jar包
add jar /home/hive/apache-hive-1.2.1-bin/hcatalog/share/hcatalog/hive-hcatalog-core-1.2.1.jar;
create table t_json(
id int,
name string,
sex boolean,
age int
)
row format serde 'org.apache.hive.hcatalog.data.JsonSerDe'
{"id":1,"name":"zhangsan1","sex":true,"age":20}
{"id":2,"name":"zhangsan2","sex":true,"age":20}
{"id":3,"name":"zhangsan3","sex":true,"age":20}
{"id":4,"name":"zhangsan4","sex":true,"age":20}
load data local inpath '/root/testjson.txt' into table t_json;

3.9 其他数据导入形式
# 创建一个普通的表
create table t(id string,name string);
# 此步骤会启动MR 任务
insert into t(id,name) values('1','gjf'),('2','zkf');
# 从 t_json中查询数据插入到 表 t 中
insert into table t select id ,name from t_json;
# 在创建表的时候将其他的表的数据拿过来
create table t1 as select * from t1;
# 创建表的时候复制其他表的表结构
create table t2 like t ;
四、表分类
4.1 内部表
默认创建的就是内部表,在删除表时,元数据和数据都会被删除,一般不建议使用
4.2 外部表
外部表在删除是不会删除数据
推荐外部表 ‘external’
create external table t_user_c_e(
id int,
name string,
birthday date,
salary double,
hobbies array<string>,
card map<string,string>,
address struct<country:string,city:string>
)
row format delimited
fields terminated by ','
collection items terminated by '|'
map keys terminated by '>'
lines terminated by '\n';
1,zhangsan,2018-10-10,1000.0,TV|Game,jiangshe>001|zhaoshang>002,china|bj
# 如果向load hdfs 上的数据 去掉loacl 即可
load data local inpath '/root/t_user_c' into table t_user_c_e;
4.3 分区表
庞大的数据集可能需要耗费大量的时间去处理。在许多场景下,可以通过分区或切片的方法减少每一次扫描总数据量,这种做法可以显著地改善性能。数据会依照单个或多个列进行分区,通常按照时间、地域或者是商业维度进行分区。比如电影表,分区的依据可以是电影的种类和评级,另外,按照拍摄时间划分可能会得到更一致的结果。为了达到性能表现的一致性,对不同列的划分应该让数据尽可能均匀分布。最好的情况下,分区的划分条件总是能够对应where语句的部分查询条件。
为了对表进行合理的管理以及提高查询效率,Hive可以将表组织成“分区”。分区是表的部分列的集合,可以为频繁使用的数据建立分区,这样查找分区中的数据时就不需要扫描全表,这对于提高查找效率很有帮助。分区表是一种根据“分区列”(partition column)的值对表进行粗略划分的机制。Hive中的每个分区表对应数据库中相应分区列的一个索引,每个分区表对应着表下的一个目录,在HDFS上的表现形式与表在HDFS上的表现形式相同,都是以子目录的形式存在。但是由于HDFS并不支持大量的子目录,这也给分区的使用带来了限制。我们有必要对表中的分区数量进行预估,从而避免因为分区数量过大带来一系列问题。Hive查询通常使用分区的列作为查询条件。这样的做法可以指定MapReduce任务在HDFS中指定的子目录下完成扫描的工作。HDFS的文件目录结构可以像索引一样高效利用。
create external table t_user_c_p(
id int,
name string,
birthday date,
salary double,
hobbies array<string>,
card map<string,string>
)
partitioned by (country string,city string)
row format delimited
fields terminated by ','
collection items terminated by '|'
map keys terminated by '>'
lines terminated by '\n';
1,zhangsan,2018-10-10,1000.0,TV|Game,jiangshe>001|zhaoshang>002
load data local inpath '/root/t_user_c_p' into table t_user_c_p partition(country='china',city='bj');

五、Hive QL 操作
5.1 Select 语句
(1)使用正则查找指定列
create table
logs
(
uuid string,
userid string ,
fromUrl string ,
dateString string,
timeString string,
ipAddress string,
browserName string,
pcSystemNameOrmobileBrandName string ,
systemVersion string,
language string,
cityName string
)
partitioned BY (day string)
row format delimited fields terminated
by ' ';
# 必须加上此属性
set hive.support.quoted.identifiers=none;
# 在使用的时候注意下面的是反引号 也就是esc 下面的那个按键
select userid ,`.*string` from logs;

(2)Limit 语句
典型的查询会返回多行数据 LIMIIT语句用于限制返回的行数
select * from logs limit 2;

5.2 Where 语句
mvn install:install-file -DgroupId=org.pentaho -DartifactId=pentaho-aggdesigner-algorithm -D version=5.1.5-jhyde -Dpackaging=jar -Dfile=D:\Downloads\pentaho-aggdesigner-algorithm-5.1.5-jhyde.jar -DskipTests
elect userid ,.*string from logs;
[外链图片转存中...(img-N1Euwggh-1577535361441)]
### (2)Limit 语句
> 典型的查询会返回多行数据 LIMIIT语句用于限制返回的行数
select * from logs limit 2;
[外链图片转存中...(img-F9n8VAzU-1577535361441)]
## 5.2 Where 语句
mvn install:install-file -DgroupId=org.pentaho -DartifactId=pentaho-aggdesigner-algorithm -D version=5.1.5-jhyde -Dpackaging=jar -Dfile=D:\Downloads\pentaho-aggdesigner-algorithm-5.1.5-jhyde.jar -DskipTests

















 3448
3448











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











