









与前文差不多
1.前置知识
- html一些知识
- python基本语法
- 简单的一些爬虫库api调用
2.所用到的包
- requests
- bs4 import BeautifulSoup Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库(可以理解为 一个处理文本工具吧)
- os
- sys
https://cn.python-requests.org/zh_CN/latest/
https://beautifulsoup.readthedocs.io/zh_CN/latest/
3.我练习所遇到的问题
- 爬取时不知道 串(帖子) 有多少页 (用了个不太好的办法判断)
正文
这次我尝试去abnmb 女装版 爬取图片(震惊)
基本操作与练习一 差不多
步骤1
与之前一样
获得html返回
user_agent = [
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60',
'Opera/8.0 (Windows NT 5.1; U; en)',
'Mozilla/5.0 (Windows NT 5.1; U; en; rv:1.8.1) Gecko/20061208 Firefox/2.0.0 Opera 9.50',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; en) Opera 9.50',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0',
'Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.57.2 (KHTML, like Gecko) Version/5.1.7 Safari/534.57.2 ',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36',
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.133 Safari/534.16',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.101 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 SE 2.X MetaSr 1.0',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; SE 2.X MetaSr 1.0)'
]
ers = 1
def get_html(url) :
while 1 :
try :
res = requests.get(url, headers = {'User-Agent':random.choice(user_agent)}, timeout=3 + random.random())
break
except Exception as e:
global ers
print("第 ", ers, " loop ", e)
ers = ers + 1
continue
# print(res.encoding) #查看网页返回的字符集类型
return res
步骤2
这里我们打开页面 我们发现如果不点开回应 就无法得到所有链接 点开回应之后进入新页面

所以我构建了一个新函数 获得当前页面所有的回应指向的地址
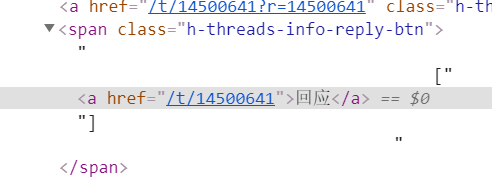
def get_h_threads_list(t) :
url = 'https://adnmb2.com/f/%E6%91%84%E5%BD%B12'
url = url + '?page=' + str(t)
print(url)
base_url = 'https://adnmb2.com'
time.sleep(1 + random.random())
html = get_html(url)
with open("adnmb/html.txt", "w", 1000, "utf-8") as f:
f.write(html.text)
f.close()
soup = BeautifulSoup(html.text)
btn_list = soup.find_all('span', class_='h-threads-info-reply-btn')
a_href = BeautifulSoup(str(btn_list))
btn_url_list = a_href.find_all('a')
global url_list
for i in btn_url_list :
url_list.append(base_url + i.get('href'))
print(base_url + i.get('href'))
步骤3
获得我们得到串地址 内所有的图片 src

获得class=“h-threads-img-a” href 并且 以 class=“h-threads-info-id” id 作为文件名
def get_page_pic(url) :
sum = get_page(url)
print(sum)
for t in range(1, sum + 1) :
time.sleep(1 + random.random())
nxt_url = url + '?page=' + str(t)
print(nxt_url)
html = get_html(nxt_url)
soup = BeautifulSoup(html.text)
div_reply = soup.find_all('div', class_='h-threads-item-reply')
for i in div_reply :
pic_href = i.find_all('a', class_='h-threads-img-a')
if(len(pic_href) == 0) :
continue
a_id = i.find_all('a', class_='h-threads-info-id')
id = a_id[0].string
if(download(pic_href[0].get('href'), id) == True or id != 'No.9999999') : continue
下载图片并保存本地
def download(url, name):
cnt = 0
if(os.path.exists('adnmb/data2/' + name + '.jpg')) : return False
while 1 :
cnt = cnt + 1
if(cnt > 10) : break
try:
with closing(requests.get(url, headers = {'User-Agent':random.choice(user_agent)}, timeout=3 + random.random())) as r:
with open('adnmb/data2/' + name + '.jpg', 'ab+') as f:
for chunk in r.iter_content(chunk_size = 1024):
if chunk:
f.write(chunk)
f.flush()
break
except Exception as e:
global ers
print("第 ", ers, " loop ", e)
ers = ers + 1
continue
return True
步骤4
获得当前串有多少页

其实这样我获取的 最多只有前11页
如果我们考虑 判断某页元素重复出现break就好了
def get_page(url) :
html = get_html(url)
soup = BeautifulSoup(html.text)
ul_page = soup.find('ul', class_='uk-pagination uk-pagination-left h-pagination')
li_page = BeautifulSoup(str(ul_page))
li_url = li_page.find_all('li')
# print(li_url)
return len(li_url) - 2
以下完整代码
import requests
import time
import random
from bs4 import BeautifulSoup
import os
import sys
from urllib import parse
from urllib import request
from contextlib import closing
import json
user_agent = [
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60',
'Opera/8.0 (Windows NT 5.1; U; en)',
'Mozilla/5.0 (Windows NT 5.1; U; en; rv:1.8.1) Gecko/20061208 Firefox/2.0.0 Opera 9.50',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; en) Opera 9.50',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0',
'Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.57.2 (KHTML, like Gecko) Version/5.1.7 Safari/534.57.2 ',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36',
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.133 Safari/534.16',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.101 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 SE 2.X MetaSr 1.0',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; SE 2.X MetaSr 1.0)'
]
ers = 1
def get_html(url) :
while 1 :
try :
res = requests.get(url, headers = {'User-Agent':random.choice(user_agent)}, timeout=3 + random.random())
break
except Exception as e:
global ers
print("第 ", ers, " loop ", e)
ers = ers + 1
continue
# print(res.encoding) #查看网页返回的字符集类型
return res
url_list = []
def get_h_threads_list(t) :
url = 'https://adnmb2.com/f/%E6%91%84%E5%BD%B12'
url = url + '?page=' + str(t)
print(url)
base_url = 'https://adnmb2.com'
time.sleep(1 + random.random())
html = get_html(url)
with open("adnmb/html.txt", "w", 1000, "utf-8") as f:
f.write(html.text)
f.close()
soup = BeautifulSoup(html.text)
btn_list = soup.find_all('span', class_='h-threads-info-reply-btn')
a_href = BeautifulSoup(str(btn_list))
btn_url_list = a_href.find_all('a')
global url_list
for i in btn_url_list :
url_list.append(base_url + i.get('href'))
print(base_url + i.get('href'))
def download(url, name):
cnt = 0
if(os.path.exists('adnmb/data2/' + name + '.jpg')) : return False
while 1 :
cnt = cnt + 1
if(cnt > 10) : break
try:
with closing(requests.get(url, headers = {'User-Agent':random.choice(user_agent)}, timeout=3 + random.random())) as r:
with open('adnmb/data2/' + name + '.jpg', 'ab+') as f:
for chunk in r.iter_content(chunk_size = 1024):
if chunk:
f.write(chunk)
f.flush()
break
except Exception as e:
global ers
print("第 ", ers, " loop ", e)
ers = ers + 1
continue
return True
def get_page(url) :
html = get_html(url)
soup = BeautifulSoup(html.text)
ul_page = soup.find('ul', class_='uk-pagination uk-pagination-left h-pagination')
li_page = BeautifulSoup(str(ul_page))
li_url = li_page.find_all('li')
# print(li_url)
return len(li_url) - 2
def get_page_pic(url) :
sum = get_page(url)
print(sum)
for t in range(1, sum + 1) :
time.sleep(1 + random.random())
nxt_url = url + '?page=' + str(t)
print(nxt_url)
html = get_html(nxt_url)
soup = BeautifulSoup(html.text)
div_reply = soup.find_all('div', class_='h-threads-item-reply')
for i in div_reply :
pic_href = i.find_all('a', class_='h-threads-img-a')
if(len(pic_href) == 0) :
continue
a_id = i.find_all('a', class_='h-threads-info-id')
id = a_id[0].string
if(download(pic_href[0].get('href'), id) == True or id != 'No.9999999') : continue
if __name__ == "__main__" :
for i in range(1, 10) :
get_h_threads_list(i)
print(len(url_list))
for i in url_list :
get_page_pic(i)
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









