






打开fiddler,Ctrl+X清空左边所有的信息,然后浏览器打开sogou.com,然后在fiddler找到 sogou.com并点击,然后在右边的请求和响应模块均选择Raw,然后在响应进行解压缩,再用记事本打开,我们分析其中的文本的含义
以下是请求模块
以下是响应模块,也跟请求一样的四个模块,请求头改成响应头,我就不细标了(鼠标写字太慢了)
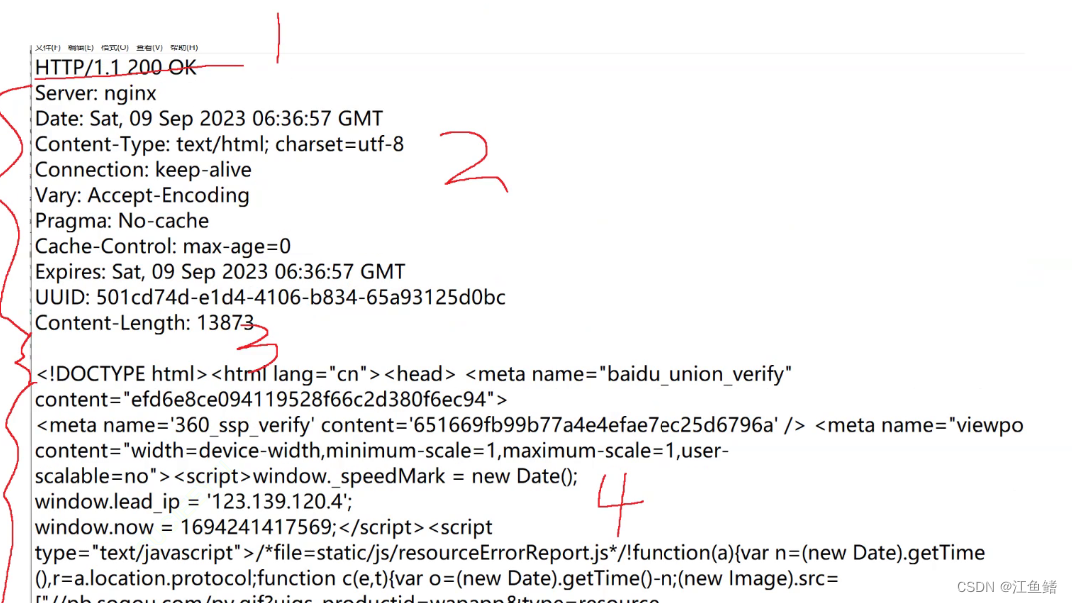
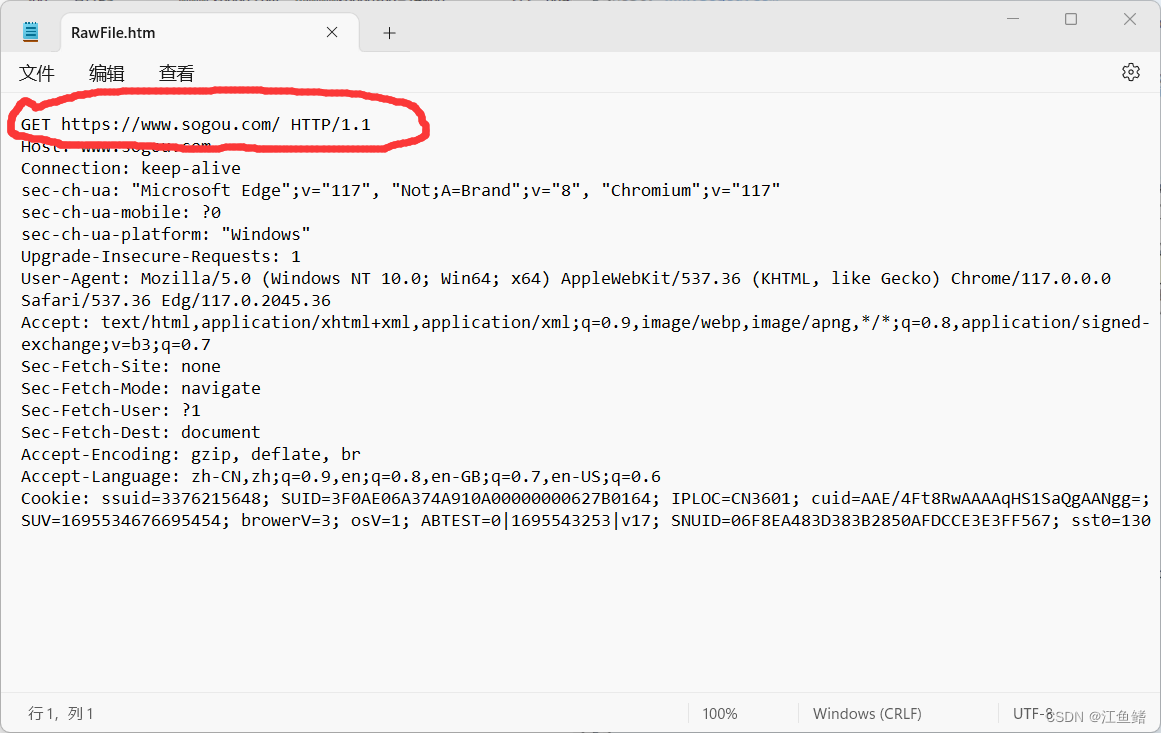
我们把请求的首行拉出来看
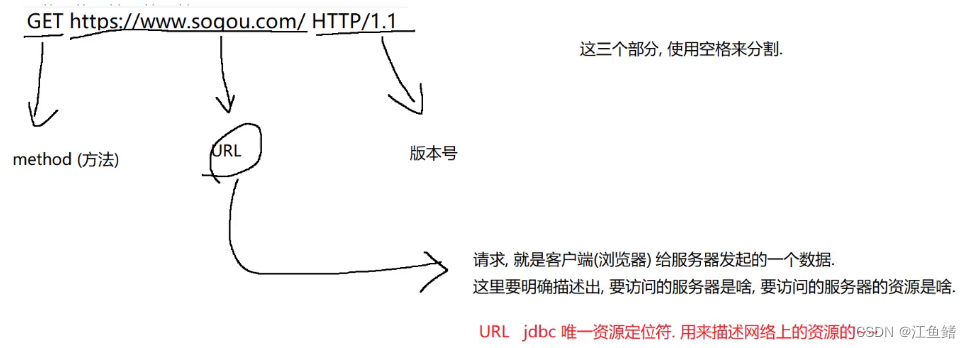
一个完整的URL是啥样的嘞,如下图

这个规定出自于RFC文档,像TCP,UDP,IP,HTTP网络协议,也是出自这里

我们针对这个格式举个例子:

我们随便打开一个b站的视频和蛋糕的网页
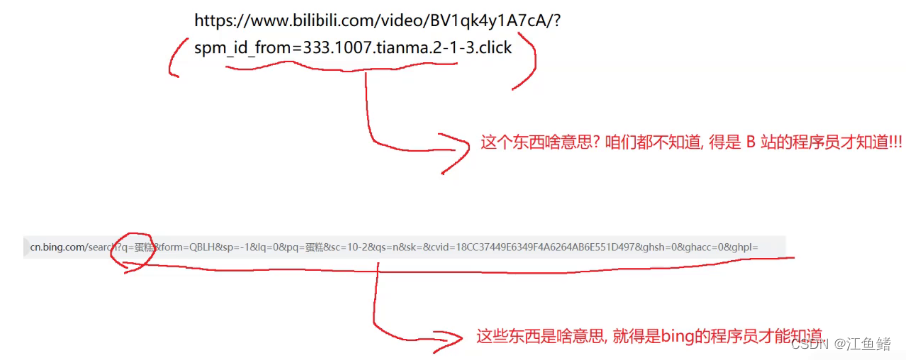
实际上,URL来说,上述的几个部分,都是可以省略的,不是哪个部分都是必须得有的,IP地址/域名如果省略,此时相当于是访问房钱服务器的地址.
打个比方就是说,我们访问b站主页,请求里必须要带有bilibili 域名,响应的内容就是 bilibili 主页的html,这个html 里又会触发一些其他的 http 请求,这些后续触发的 http 请求,就可以省略 ip,省略 ip就相当于使用和刚才获取 bilibili html 一样的 ip
端口号 也可以省略,这是非常常见的,这个端口号表示的是访问目标服务器的哪个端口.如果是 http 协议,自动添加的端口就是80,如果是https 协议,自动添加的端口就是443
知名端口号<1024,都被一些常用的知名服务器给瓜分了,号码越小,资历越老,和公司的工号差不多,创始人都是工号1
因此一个商业产品部署服务器的时候,往往就会遵守上述规则,把http 服务器绑定到80,把https 绑定到443,这样用户用浏览器访问你的服务器的时候就不用显示指定端口
当然不遵守上述规则也是可以的,咱后面就不遵守,咱用别的端口
带层次的路径也是可以省略的
比如搜狗:https://www.sogou.com/
如果省略,相当于访问的就是 / , / 称为根目录,我们知道目录结构往往是树形结构,根目录就相当于树根一样,我们可以认为服务器提供的资源,也是类似于目录结构一样的树形结构来组织的.
既然是树,就会有树根. / 就是根节点.而通常根节点就会对应到服务器的主页(约定俗成的规则)
查询字符串也可以没有
有和没有都是可以让后端代码根据情况来处理的,就比如那个熏肉大饼的例子,如果没有查询字符串,那做饭师父就会根据自己的经验给你做大饼,如果你手动修改,那就按照你修改的去做大饼
url encode
我们在搜狗主页中搜索c++,就会出现这样的内容,++变成%2B%2B了
这是因为 query string 中可能会带有一些特殊符号,而这些特殊符号,可能在 url 本身就有一定的含义,就导致浏览器/服务器解析失败,而c++中的+就属于特殊符号,会被转义成=>%2B
同理 : / ? & = # 都需要转换,中文也需要转换
怎么转义呢?其实规则很简单,我们可以再浏览器中搜索urlencode,这样就会有在线转码工具
我们随便打开一个
转换规则就是把要转换的内容的二进制的每个字节,都使用 十六进制 表示出来,然后每个字节前面加上一个%

字符就查ASCII码表,文字查utf8表
这是加号的码

这是你好的码

经过urlencode 之后,此时 query string 中就不会出现特殊含义的符号,浏览器和服务器才能正确识别,这就跟写代码不能用关键字作为变量名一样的道理
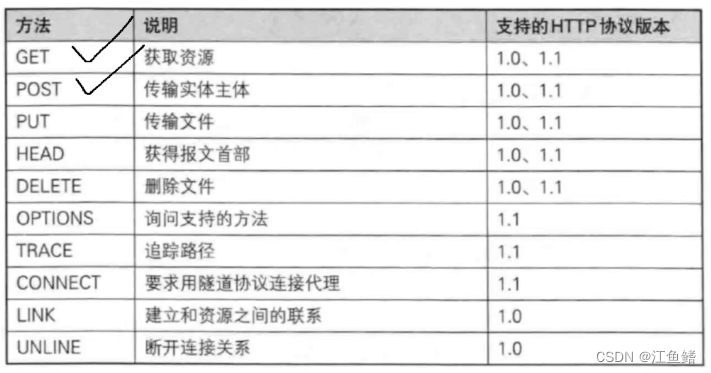
HTTP请求的方法
方法就是对于这次操作有个解释,这次操作具体是干啥的
下面那个表是HTTP中一些典型的方法,GET和POST是最常用的

方法描述的是"语义"这次请求要干啥
GET:"从服务器获取xxx"
POST:"向服务器传输一个xxxx"
虽然HTTP 协议设计之初,大佬们是希望程序员能够遵守这里的语义来使用HTTP 的,但是大家用着用着就放飞自我了,GET也能传输,post也能获取,不一定遵守之前的语义了
接下来我们看看搜狗的GET请求,GET请求一般没有body
POST请求最常见的场景:1.登录 2.上传
所以我们登录一下Gitee,看看POST请求
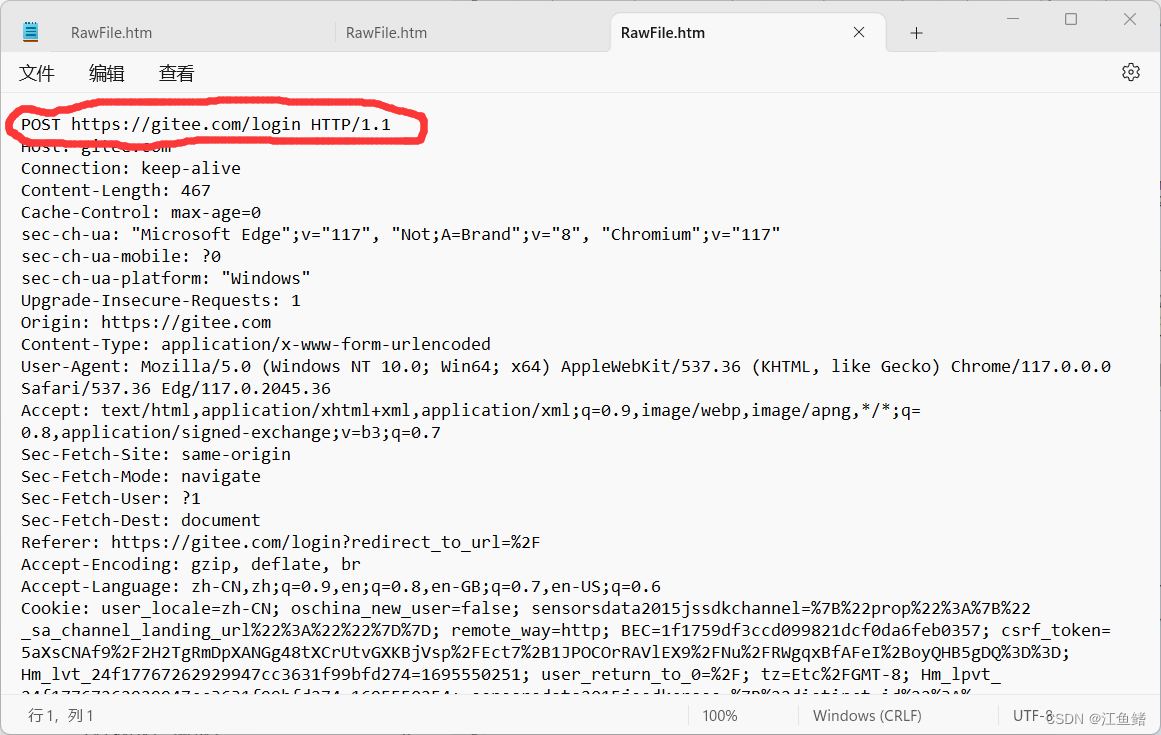
前面都跟GET差不多,但是往下滑就不一样了,后面有空行,还有body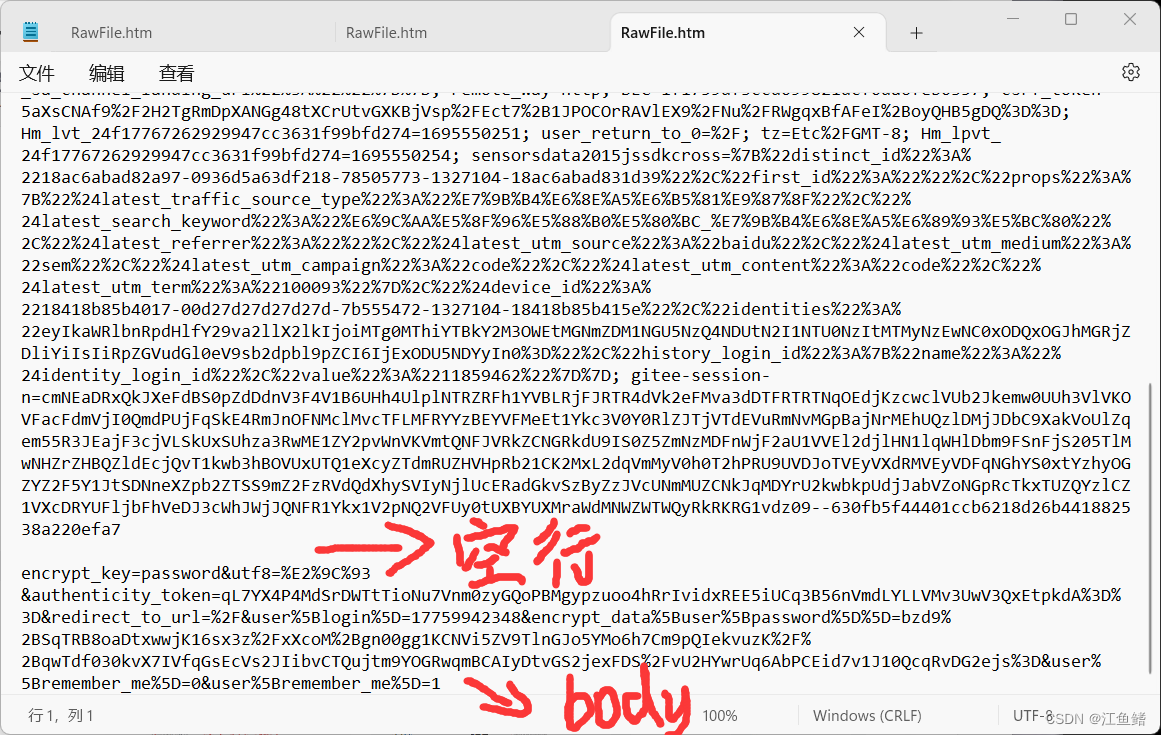
空行相当于是一个分隔符,分割了header和body,描述了body是从哪里开始的
body里的格式其实是可以有很多种,此处这个body的格式,和刚才说过的 query string 非常相似,是一个一个的键值对,中间用&进行连接,在登录场景中,这里就会包含这次登录的用户名和密码(密码是加密的,一般密码不会明文传输)
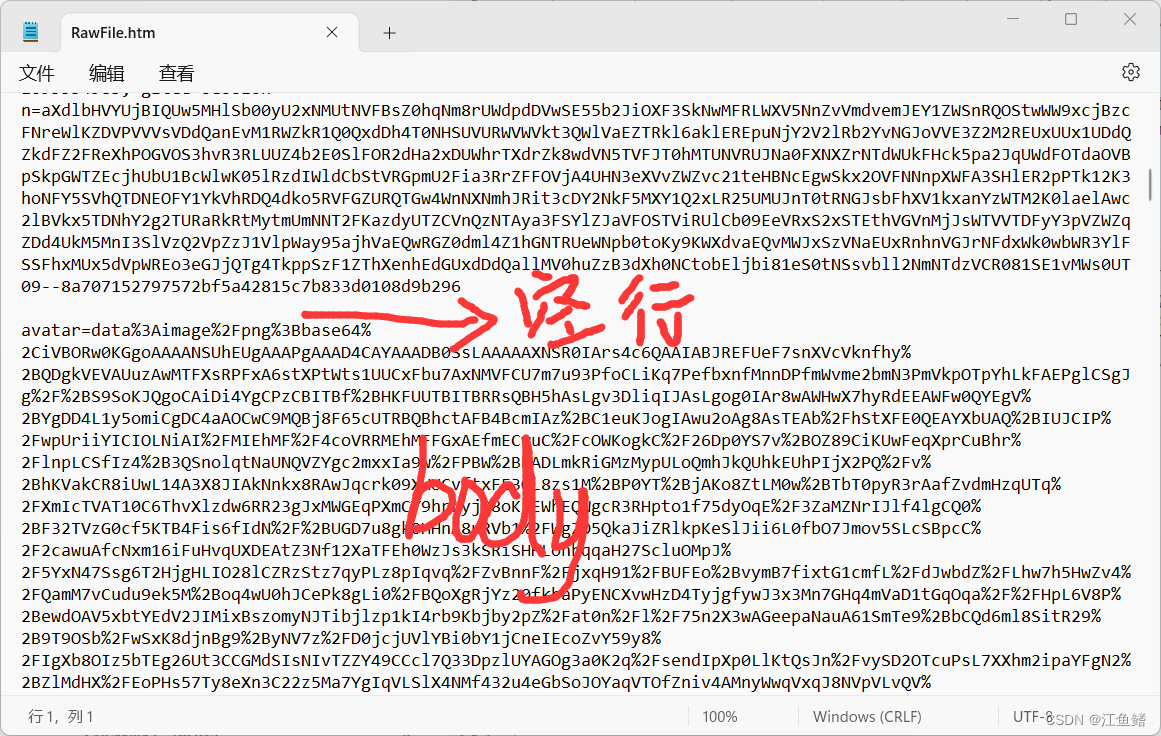
接下来我们试试上传的POST,我们给Gitee换个头像
我们可以看到这也是个POST请求
往下翻就会发现,这个也有空行和body
POST 和 GET 最主要的区别就在于说
GET是把一些自定义的数据放到query string 中,body 通常是空的
POST 是把一些自定义的数据放到 body 里,query string 通常是空的
其实都是要传输给服务器的,放在哪都行,本质上没有区别,只不过放在url中的话用户能直接看到(浏览器收藏夹也能收藏),放在 body 中用户看不见(收藏夹也不能收藏)
但是上传和登录还是使用POST更多,因为登录的时候,涉及到用户名密码,属于比较敏感的信息,直接展示在url里会让用户觉得不太安全
正是因为 POST 和 GET 数据放在哪里本质上都是一样的,所以两者经常可以相互替代

设计互联网产品,有些时候也是要考虑幂等性的,有的时候期望是幂等的,有的时候期望不幂等
比如我们希望账户余额是幂等的
但是浏览器搜索出来的广告就不希望是幂等的,比如我们搜索蛋糕,要根据用户的地点和广告主投放的情况以及广告主的出价,谁出钱多谁排前面
要根据实际情况灵活应对

接下来我们看看 head
这个请求报头也是键值对结构,每一行是一个键值对,键和值之间使用 冒号和空格 来分割
query string / body 的键值对完全是由程序员自定义的
header 中的键值对是由标准规定的(有哪些键,对应的取值有哪些,都是有规定的),也有可以自定义的部分,我们上面的都是标准规定的
Host : 表示服务器主机的地址和端口
Content-Length : 表示 body 中的数据长度 (有的请求有body,有的请求没有,如果没body,可以没有这个字段,如果有body,这个字段必须有,否则就是非法请求)
body 是从空行开始的,从空行开始数,数 Content-Length 这么长,body就结束了,这样做可以解决粘包问题,当浏览器连续给服务器发送多个请求的时候,或者服务器连续多个返回HTTP响应的时候.服务器或者浏览器要如何区别从哪里到哪里是一个完整的HTTP数据呢?
1.使用分隔符
2.使用长度
如果是GET,没有body,就使用空行作为结束标志
如果是POST,有body,就使用长度来区分结尾
Content-Type : 表示请求的 body 中的数据格式
(因为HTTP协议有很多用途,传输的数据也有很多种类,所以针对这个数据要如何解析,如何理解,这就是个很重要的问题,Content-Type此时就能起到作用)
















 217
217











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









