







1 简介
1.是什么
Hadoop是apache的一个大数据存储计算的开源软件。
2.可以干什么
a 大数据存储 b 分布式计算 c (计算机)资源调度
3.特点
高性能 低成本 高效率 可靠 使用起来通用简单
4.版本
4.1开源社区版本
更新迭代快,兼容性和稳定性较低
https://hadoop.apache.org/
4.2商业发行版本
5.组成
HDFS(分布式文件存储)
MapReduce(分布式数据处理,代码层面上的组件)
YARN(2.0出现 资源管理任务调度)
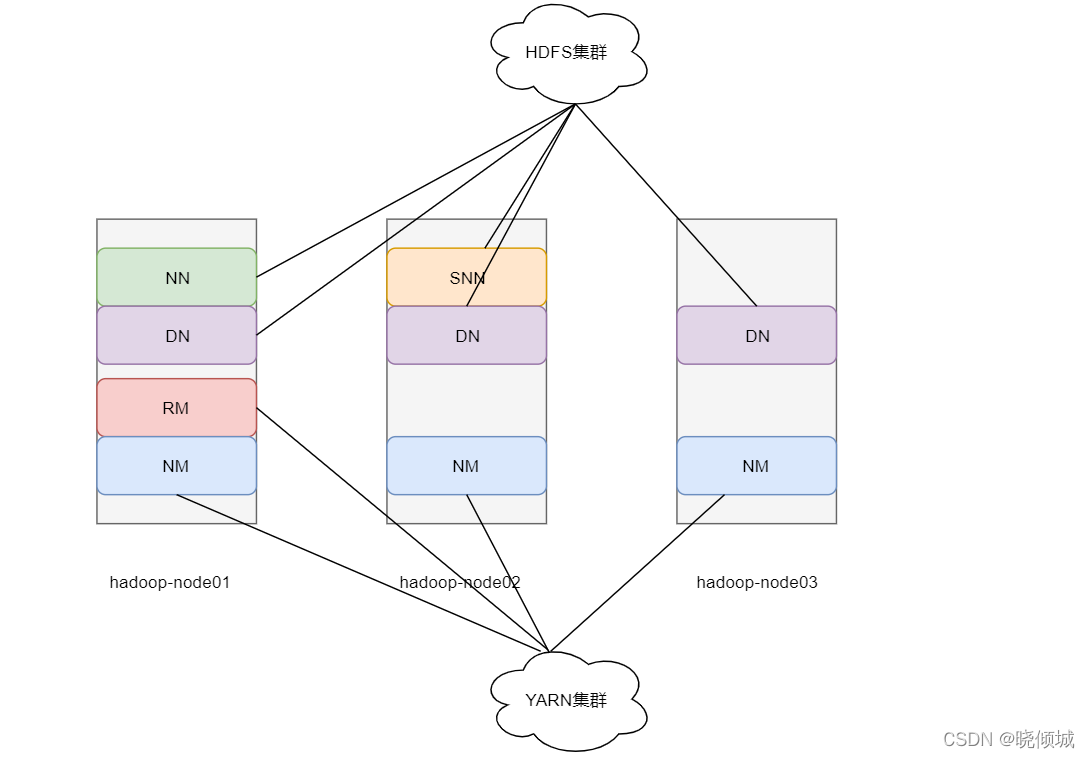
6.Hadoop集群
Hadoop 集群= HDFS + YARN
HDFS集群
主角色 NameNode
从角色 DataNode
主角色辅助角色 SecondaryNameNode
YARN集群
主角色 RecourceManager
从角色 NodeManager
可以看到在实验部署中,HDFS集群有一组NN加三从DN外加一个辅助角色SNN
YARN集群中一个主RM三个从NM
2 部署
1设置主机
hostnamectl set-hostname hadoop-node01
hostnamectl set-hostname hadoop-node02
hostnamectl set-hostname hadoop-node03
2设置hosts
这里建议也在宿主机上设置一下
cat /etc/hosts
192.168.67.200 hadoop-node01
192.168.67.201 hadoop-node02
192.168.67.202 hadoop-node03
3关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
4ssh免密登陆
全部在节点一进行操作,该操作主要用于linux主机间的远程操作
#node1生成公钥私钥 (一路回车)
ssh-keygen
#node1配置免密登录到node1 node2 node3
ssh-copy-id node1
ssh-copy-id node2
ssh-copy-id node3
5时间同步
ntpdate没有该命令可以使用yum安装一下
ntpdate ntp5.aliyun.com
6创建工作目录
mkdir -p /export/server 软件安装目录
mkdir -p /export/data 软件数据存储目录
mkdir -p /export/software 软件安装包存放目录
7在第一台机器上安装jdk1.8
配置环境变量并生效
[root@localhost server]# vi /etc/profile
[root@localhost server]# source /etc/profile
export JAVA_HOME=/export/server/jdk1.8.0_241
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
在节点一远程拷贝到其他两台机器
scp -r /export/server/jdk1.8.0_241/ root@hadoop-node02:/export/server/
环境变量文件也可以拷贝,记得生效
scp -r /etc/profile root@hadoop-node02:/etc/profile
8Hadoop安装
目录结构
-
bin基本的管理脚本
-
sbin启动脚本
-
etc配置
-
share编译后的jar包和示例
9修改配置
hadoop-env.sh
#文件最后添加
export JAVA_HOME=/export/server/jdk1.8.0_241
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
core-site.xml

<!-- 设置默认使用的文件系统 Hadoop支持file、HDFS、GFS、ali|Amazon云等文件系统 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop-node01:8020</value>
</property>
<!-- 设置Hadoop本地保存数据路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/export/data/hadoop-3.3.0</value>
</property>
<!-- 设置HDFS web UI用户身份 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- 整合hive 用户代理设置 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<!-- 文件系统垃圾桶保存时间 -->
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
hdfs-site.xml
<!-- 设置SNN进程运行机器位置信息 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop-node02:9868</value>
</property>
mapred-site.xml
<!-- 设置MR程序默认运行模式: yarn集群模式 local本地模式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- MR程序历史服务地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop-node01:10020</value>
</property>
<!-- MR程序历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop-node01:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
yarn-site.xml
<!-- 设置YARN集群主角色运行机器位置 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop-node01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 是否将对容器实施物理内存限制 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!-- 是否将对容器实施虚拟内存限制。 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 开启日志聚集 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置yarn历史服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop-node01:19888/jobhistory/logs</value>
</property>
<!-- 历史日志保存的时间 7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
vi workers
hadoop-node01
hadoop-node02
hadoop-node03
10分发安装包到其他机器
cd /export/server
scp -r hadoop-3.3.0 root@hadoop-node02:$PWD
scp -r hadoop-3.3.0 root@hadoop-node03:$PWD
11添加Hadoop到环境变量
vim /etc/profile
export HADOOP_HOME=/export/server/hadoop-3.3.0
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
输入hadoop后可以看到相关命令(此处拍一个快照)
12HDFS系统初始化(格式化)
在节点一上执行初始化命令,只能启动一次
hdfs namenode -format
初始化成功
13在节点一启动服务
启动HDFS服务
start-dfs.sh
验证服务是否启动成功
node1
[root@localhost server]# jps
3732 Jps
3445 DataNode
3323 NameNode
node2
[root@localhost ~]# jps
14880 DataNode
14993 SecondaryNameNode
15116 Jps
node3
[root@localhost ~]# jps
2680 Jps
2618 DataNode
启动YARN服务,只在第一台机器启动即可
start-yarn.sh

验证服务是否启动成功
node01
[root@localhost server]# jps
4321 Jps
3987 NodeManager
3445 DataNode
3864 ResourceManager
3323 NameNode
node02
[root@localhost ~]# jps
14880 DataNode
14993 SecondaryNameNode
15475 NodeManager
15615 Jps
node03
[root@localhost ~]# jps
2738 NodeManager
2618 DataNode
2828 Jps
3 系统UI及简单使用
HDFS
http://hadoop-node01:9870/
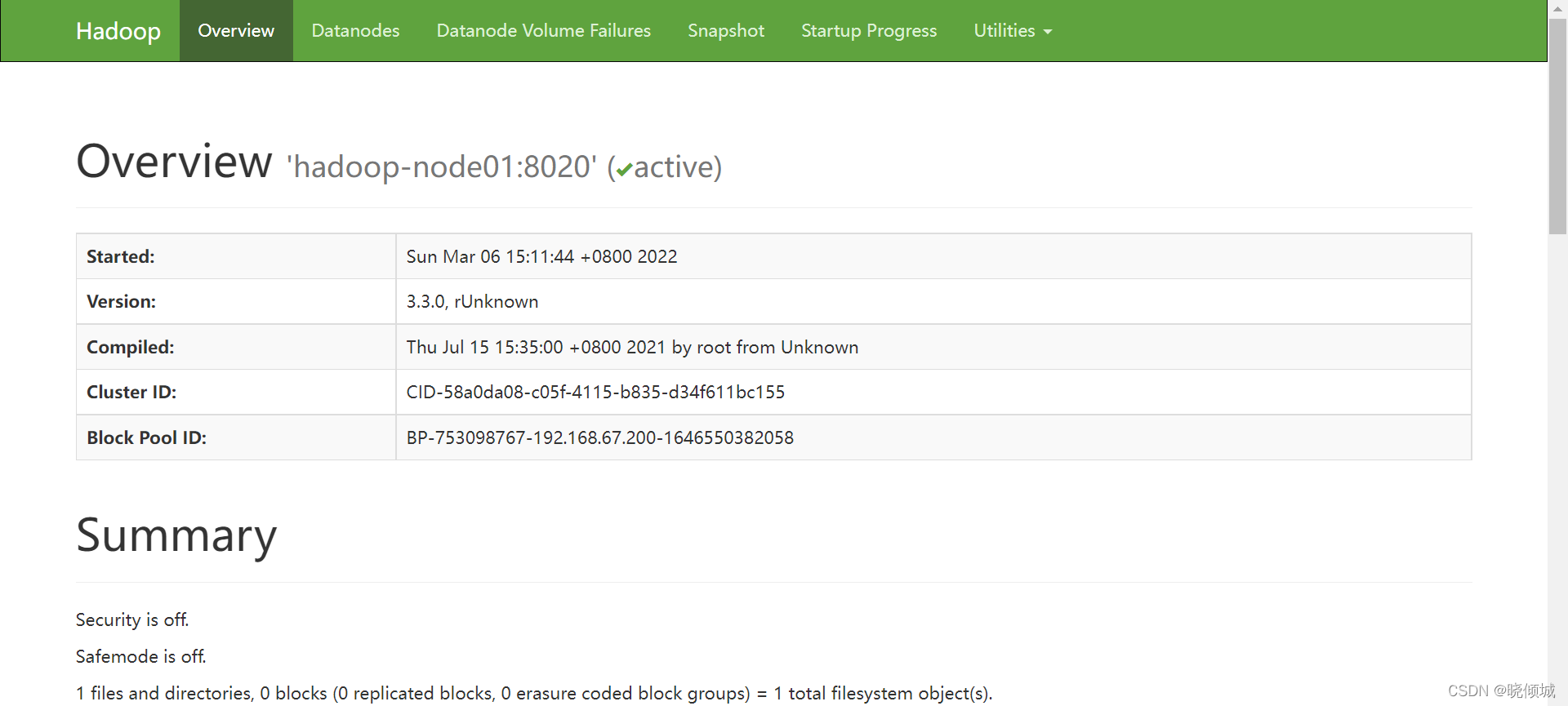
浏览文件系统
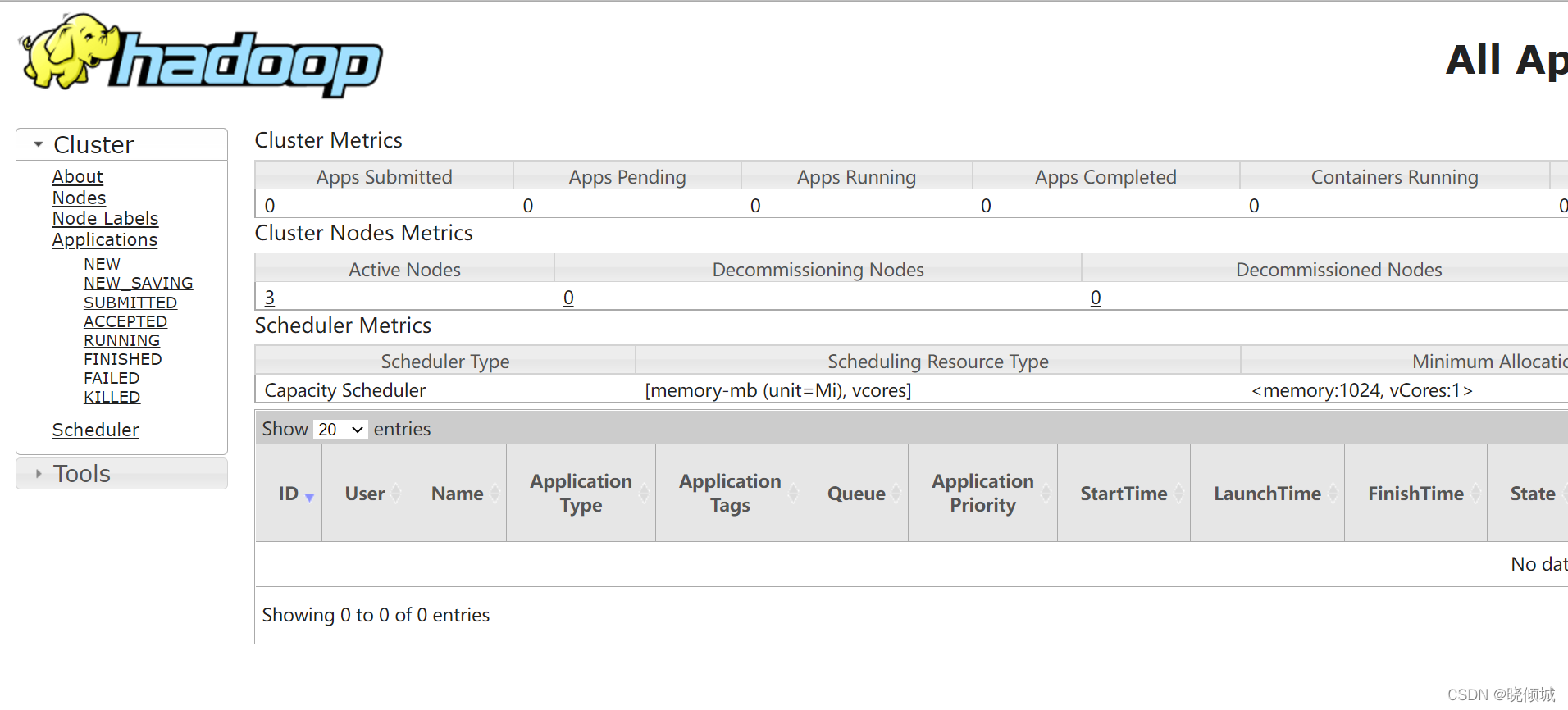
YARN 8088
4 系统基本操作
HDFS
[root@localhost server]# hadoop fs -ls /
[root@localhost server]# hadoop fs -mkdir /hellohdfs
[root@localhost server]# ls
hadoop-3.3.0 hadoop-3.3.0-Centos7-64-with-snappy.tar.gz hadoop-3.3.0-src.tar.gz jdk1.8.0_241 jdk-8u241-linux-x64.tar.gz
[root@localhost server]# echo hello > hello.txt
[root@localhost server]# hadoop fs -put hello.txt /hellohdfs
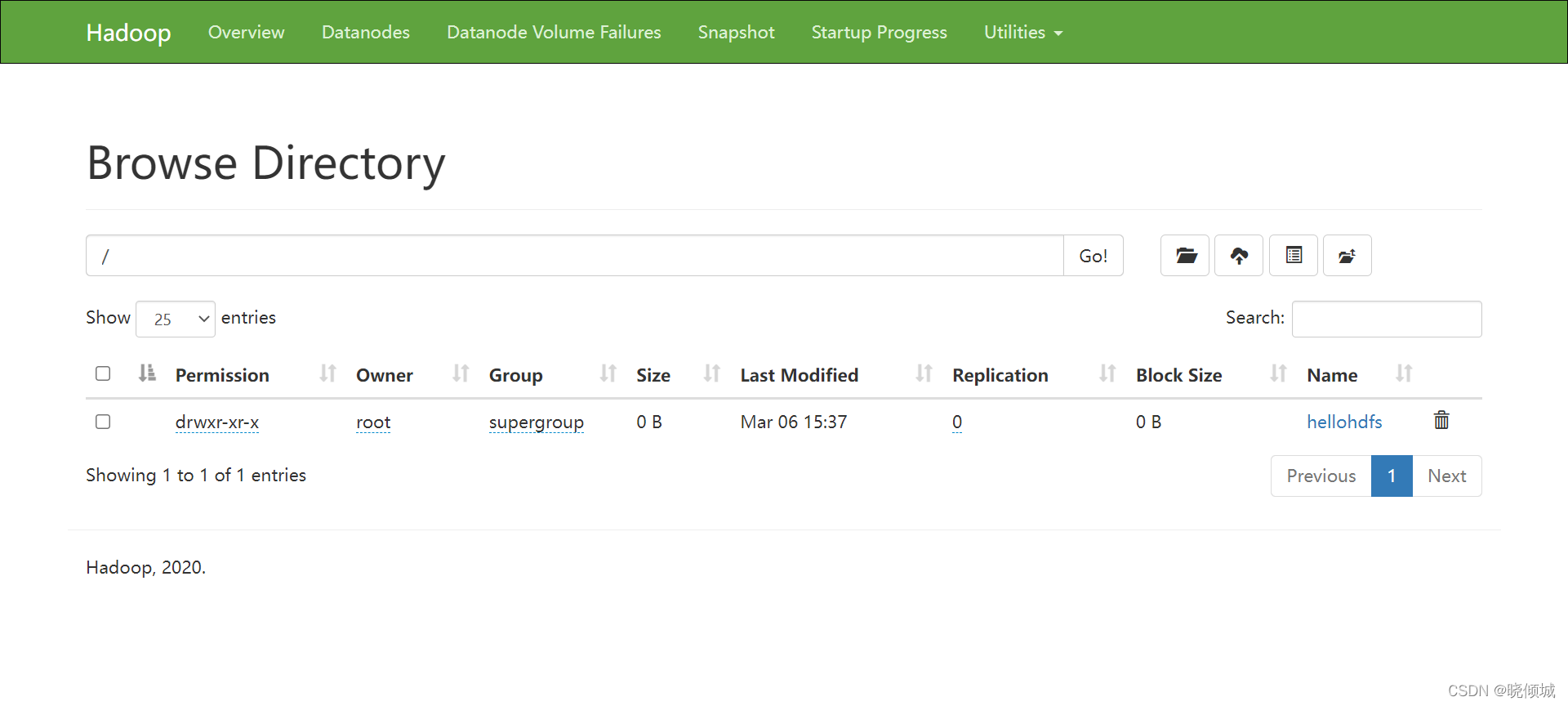
YARN
cd /export/server/hadoop-3.3.0/share/hadoop/mapreduce
案例一:计算圆周率
hadoop jar hadoop-mapreduce-examples-3.3.0.jar pi 2 2
[root@localhost mapreduce]# hadoop jar hadoop-mapreduce-examples-3.3.0.jar pi 2 2
Number of Maps = 2
Samples per Map = 2
Wrote input for Map #0
Wrote input for Map #1
Starting Job
2022-03-06 15:44:32,206 INFO client.DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at hadoop-node01/192.168.67.200:8032
2022-03-06 15:44:34,363 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/root/.staging/job_1646551219840_0001
2022-03-06 15:44:35,119 INFO input.FileInputFormat: Total input files to process : 2
2022-03-06 15:44:35,395 INFO mapreduce.JobSubmitter: number of splits:2
2022-03-06 15:44:36,376 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1646551219840_0001
2022-03-06 15:44:36,377 INFO mapreduce.JobSubmitter: Executing with tokens: []
2022-03-06 15:44:37,306 INFO conf.Configuration: resource-types.xml not found
2022-03-06 15:44:37,308 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2022-03-06 15:44:39,455 INFO impl.YarnClientImpl: Submitted application application_1646551219840_0001
2022-03-06 15:44:39,947 INFO mapreduce.Job: The url to track the job: http://hadoop-node01:8088/proxy/application_1646551219840_0001/
2022-03-06 15:44:39,948 INFO mapreduce.Job: Running job: job_1646551219840_0001
2022-03-06 15:45:10,432 INFO mapreduce.Job: Job job_1646551219840_0001 running in uber mode : false
2022-03-06 15:45:10,437 INFO mapreduce.Job: map 0% reduce 0%
2022-03-06 15:45:41,275 INFO mapreduce.Job: map 100% reduce 0%
2022-03-06 15:45:57,587 INFO mapreduce.Job: map 100% reduce 100%
2022-03-06 15:45:58,682 INFO mapreduce.Job: Job job_1646551219840_0001 completed successfully
2022-03-06 15:45:59,575 INFO mapreduce.Job: Counters: 54
File System Counters
FILE: Number of bytes read=50
FILE: Number of bytes written=795297
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=536
HDFS: Number of bytes written=215
HDFS: Number of read operations=13
HDFS: Number of large read operations=0
HDFS: Number of write operations=3
HDFS: Number of bytes read erasure-coded=0
Job Counters
Launched map tasks=2
Launched reduce tasks=1
Data-local map tasks=2
Total time spent by all maps in occupied slots (ms)=52488
Total time spent by all reduces in occupied slots (ms)=13859
Total time spent by all map tasks (ms)=52488
Total time spent by all reduce tasks (ms)=13859
Total vcore-milliseconds taken by all map tasks=52488
Total vcore-milliseconds taken by all reduce tasks=13859
Total megabyte-milliseconds taken by all map tasks=53747712
Total megabyte-milliseconds taken by all reduce tasks=14191616
Map-Reduce Framework
Map input records=2
Map output records=4
Map output bytes=36
Map output materialized bytes=56
Input split bytes=300
Combine input records=0
Combine output records=0
Reduce input groups=2
Reduce shuffle bytes=56
Reduce input records=4
Reduce output records=0
Spilled Records=8
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=1004
CPU time spent (ms)=4930
Physical memory (bytes) snapshot=504107008
Virtual memory (bytes) snapshot=8212619264
Total committed heap usage (bytes)=263778304
Peak Map Physical memory (bytes)=198385664
Peak Map Virtual memory (bytes)=2737340416
Peak Reduce Physical memory (bytes)=109477888
Peak Reduce Virtual memory (bytes)=2741846016
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=236
File Output Format Counters
Bytes Written=97
Job Finished in 88.0 seconds
Estimated value of Pi is 4.00000000000000000000
案例二:单词统计
hadoop fs -mkdir -p /wordcount/input
hadoop fs -put mywords.txt /wordcount/input
hadoop jar hadoop-mapreduce-examples-3.3.0.jar wordcount /wordcount/input /wordcount/output
[root@localhost mapreduce]# hadoop jar hadoop-mapreduce-examples-3.3.0.jar wordcount /wordcount/input /wordcount/output
2022-03-06 15:52:46,025 INFO client.DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at hadoop-node01/192.168.67.200:8032
2022-03-06 15:52:48,220 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/root/.staging/job_1646551219840_0002
2022-03-06 15:52:49,299 INFO input.FileInputFormat: Total input files to process : 1
2022-03-06 15:52:49,673 INFO mapreduce.JobSubmitter: number of splits:1
2022-03-06 15:52:50,671 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1646551219840_0002
2022-03-06 15:52:50,672 INFO mapreduce.JobSubmitter: Executing with tokens: []
2022-03-06 15:52:51,504 INFO conf.Configuration: resource-types.xml not found
2022-03-06 15:52:51,505 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2022-03-06 15:52:51,755 INFO impl.YarnClientImpl: Submitted application application_1646551219840_0002
2022-03-06 15:52:52,019 INFO mapreduce.Job: The url to track the job: http://hadoop-node01:8088/proxy/application_1646551219840_0002/
2022-03-06 15:52:52,036 INFO mapreduce.Job: Running job: job_1646551219840_0002
2022-03-06 15:53:17,361 INFO mapreduce.Job: Job job_1646551219840_0002 running in uber mode : false
2022-03-06 15:53:17,380 INFO mapreduce.Job: map 0% reduce 0%
2022-03-06 15:53:41,194 INFO mapreduce.Job: map 100% reduce 0%
2022-03-06 15:54:08,530 INFO mapreduce.Job: map 100% reduce 100%
2022-03-06 15:54:09,601 INFO mapreduce.Job: Job job_1646551219840_0002 completed successfully
2022-03-06 15:54:10,177 INFO mapreduce.Job: Counters: 54
File System Counters
FILE: Number of bytes read=3367
FILE: Number of bytes written=536181
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=4681
HDFS: Number of bytes written=2551
HDFS: Number of read operations=8
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
HDFS: Number of bytes read erasure-coded=0
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=18564
Total time spent by all reduces in occupied slots (ms)=23913
Total time spent by all map tasks (ms)=18564
Total time spent by all reduce tasks (ms)=23913
Total vcore-milliseconds taken by all map tasks=18564
Total vcore-milliseconds taken by all reduce tasks=23913
Total megabyte-milliseconds taken by all map tasks=19009536
Total megabyte-milliseconds taken by all reduce tasks=24486912
Map-Reduce Framework
Map input records=86
Map output records=428
Map output bytes=5358
Map output materialized bytes=3367
Input split bytes=118
Combine input records=428
Combine output records=204
Reduce input groups=204
Reduce shuffle bytes=3367
Reduce input records=204
Reduce output records=204
Spilled Records=408
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=583
CPU time spent (ms)=4690
Physical memory (bytes) snapshot=285466624
Virtual memory (bytes) snapshot=5475692544
Total committed heap usage (bytes)=139329536
Peak Map Physical memory (bytes)=190091264
Peak Map Virtual memory (bytes)=2733432832
Peak Reduce Physical memory (bytes)=95375360
Peak Reduce Virtual memory (bytes)=2742259712
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=4563
File Output Format Counters
Bytes Written=2551
执行完毕后HDFS会自动生成输出目录
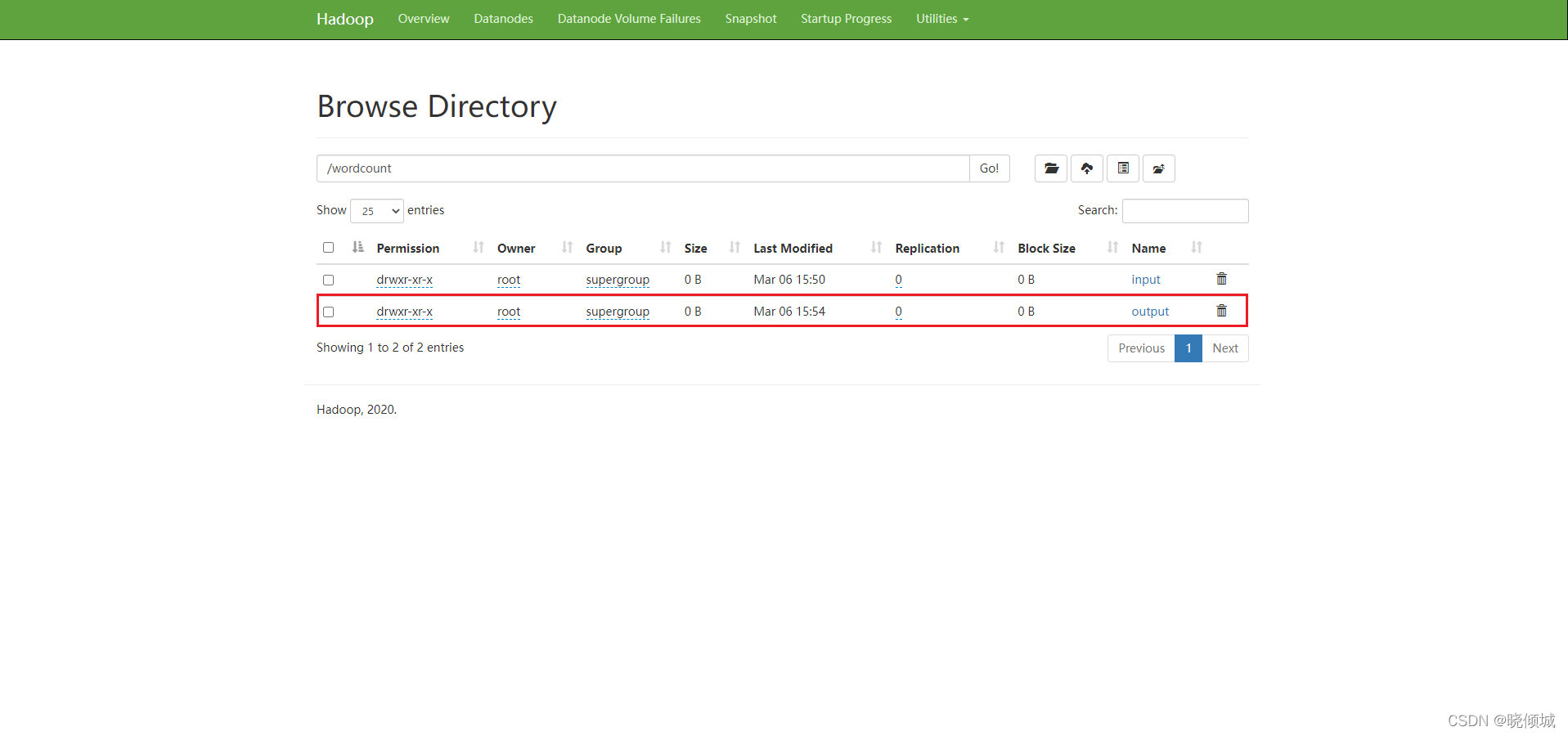
进入目录
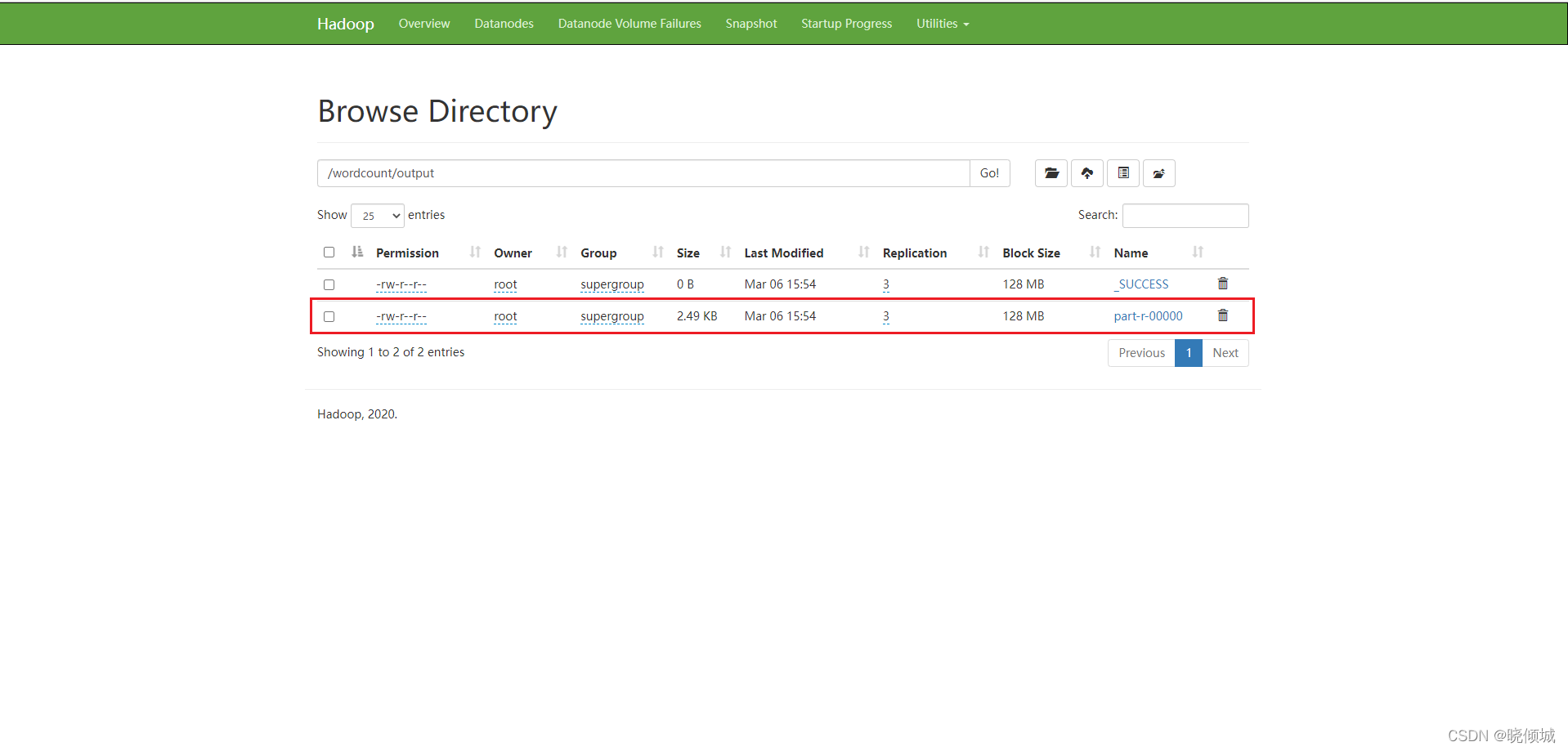
下载文件后使用notepad++打开

注:如果你使用的是虚拟机,搭配宿主机使用的时候需要在宿主机hosts文件中填写虚拟机ip和域名映射否则会下载失败。















 4605
4605











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









