






Redis学习笔记
目录
- 五大基本数据类型
- 三种特殊数据类型
- Redis事务
- Springboot整合Redis
- Redis配置文件
- Redis持久化
- Redis主从复制
- 哨兵模式
- Redis集群
- Redis缓存穿透、击穿和雪崩
五大基本数据类型
具体命令详解参考:Redis 命令参考
String

说明:以键值对的形式存储,值可以是字符串或数字
List

说明:List可以看做是一个双向链表,能够实现栈,队列,阻塞队列等操作
Set

说明:Set是一个无序不重复集合
Hash
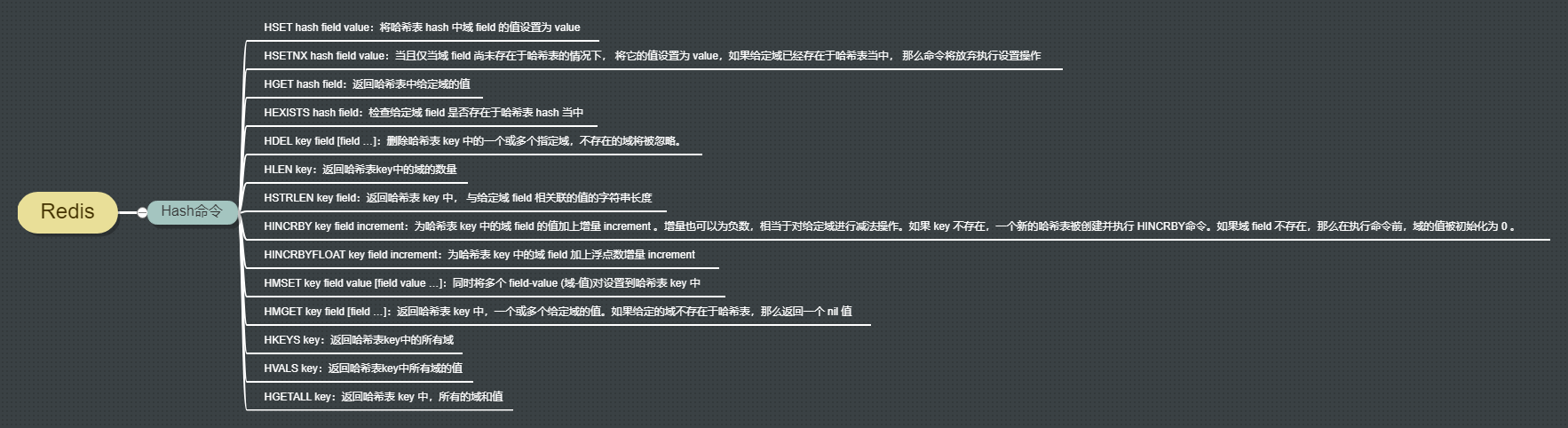
补充:也是键值对的形式,不过键值对的值是一个map,或者说值也是一个键值对。Hash可以用来存对象,比用字符串的存更加方便和高级
Zset

说明:Zset是一个有序集合,类似set,都是字符串的集合,都不允许重复的成员出现在一个set中,他们之间差别在于Zset中每一个元素都会有一个 score与之关联,这个score可用于排序和排名
三种特殊数据类型
具体命令详解参考:Redis 命令参考
Geospatial地理位置
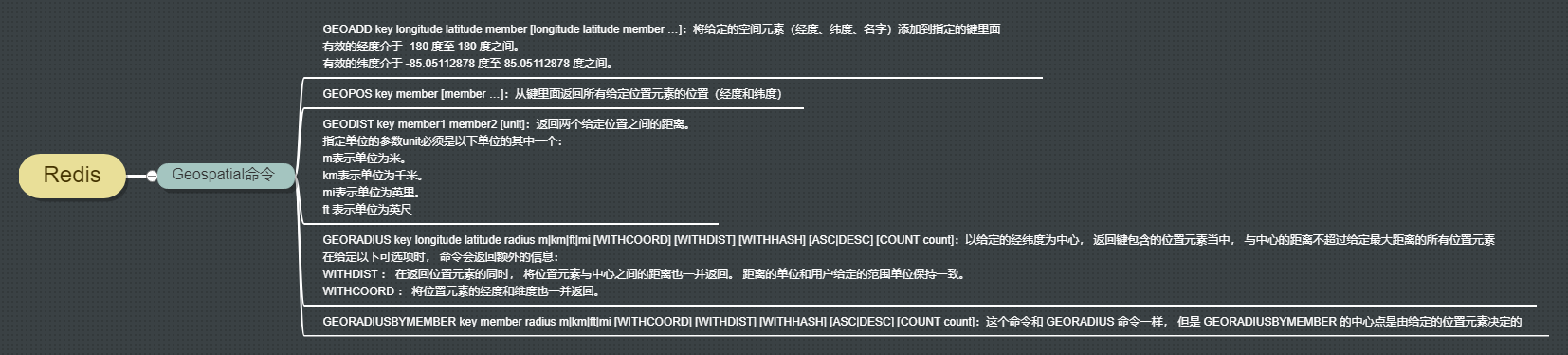
补充:Geospatial底层是用Zset实现,因此可以使用zrange命令查看所有位置名称,使用zrem命令删除位置信息
HyperLogLog
- 基数:比如数据集 {1, 3, 5, 7, 5, 7, 8}, 那么这个数据集的基数集为 {1, 3, 5 ,7, 8}, 基数(不重复元素)为5。基数估计就是在误差可接受的范围内,快速计算基数。

补充:每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基数
BitMaps

补充:只能存0和1。能够用于只有两个状态的情况。
Redis事务
- Redis单条命令保证原子性,但是事务不保证原子性
- Redis事务没有回滚
- Redis务中没有隔离级别
Redis事务概念
Redis事务其实是一组命令的集合。即在一个事务中执行多个命令,并且所有命令都会被序列化。在执行的过程中,会按照入队的顺序进行顺序执行,并且不会有其他命令插入到执行序列中。
总结:Redis事务具有一次性、顺序性和排他性。
Redis事务没有隔离级别
Redis事务在执行EXEC命令前并不会真正的执行,只是放入到执行队列中,只有在执行了EXEC命令后才会开始执行事务中的命令,由于Redis使用单线程的方式来执行事务,并且服务器保证,在执行事务期间不会对事务进行中断,因此,Redis中没有事务隔离级别。
Redis事务三个阶段
- 开始事务(MULTI命令)
- 命令入队(执行什么命令,写什么命令)
- 执行事务(EXEC命令)
Redis事务相关命令
- multi : 标记一个事务块的开始
- exec : 执行所有事务块的命令
- discard : 取消事务,放弃事务块中的所有命令
- watch key1 key2 … : 监视一或多个key,如果在事务执行之前,被监视的key被其他命令改动,则事务被打断 ( 类似乐观锁 )
- unwatch : 取消watch对所有key的监控
若在事务队列中存在命令性错误(类似于java编译性错误),则执行EXEC命令时,所有命令都不会执行
若在事务队列中存在语法性错误(类似于java的1/0的运行时异常),则执行EXEC命令时,其他正确命令会被执行,错误命令抛出异常
Redis的乐观锁(Watch实现)
在执行multi之前,先执行watch key1 [key2],可以监视一个(或多个) key ,如果在事务执行之前这个(或这些) key被其他命令所改动,那么事务将被打断。
watch指令类似于乐观锁,在事务提交时,如果watch监控的多个KEY中任何KEY的值已经被其他客户端更改,则使用EXEC执行事务时,事务队列将不会被执行,同时返回Nullmulti-bulk应答以通知调用者事务执行失败。
Springboot整合Redis
在springboot2.x之后,原来使用的jedis被替换成了lettuce.
- Jedis在实现上是直连Redis服务,多线程环境下非线程安全,除非使用连接池,为每个 RedisConnection 实例增加物理连接。
- Lettuce是一种可伸缩,线程安全,完全非阻塞的Redis客户端,多个线程可以共享一个RedisConnection,它利用Netty NIO框架来高效地管理多个连接,从而提供了异步和同步数据访问方式,用于构建非阻塞的反应性应用程序。
- 导入jar包
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
- 配置连接
#Redis配置
spring.redis.host=localhost
spring.redis.port=6379
...
- 序列化配置和自定义RedisTemplate模板(转载于狂神说)
@Configuration
public class RedisConfig {
@Bean
@SuppressWarnings("all")
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) {
// 我们为了自己开发方便,一般直接使用 <String, Object>
RedisTemplate<String, Object> template = new RedisTemplate<String, Object>();
template.setConnectionFactory(factory);
// Json序列化配置
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
ObjectMapper om = new ObjectMapper();
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jackson2JsonRedisSerializer.setObjectMapper(om);
// String 的序列化
StringRedisSerializer stringRedisSerializer = new StringRedisSerializer();
// key采用String的序列化方式
template.setKeySerializer(stringRedisSerializer);
// hash的key也采用String的序列化方式
template.setHashKeySerializer(stringRedisSerializer);
// value序列化方式采用jackson
template.setValueSerializer(jackson2JsonRedisSerializer);
// hash的value序列化方式采用jackson
template.setHashValueSerializer(jackson2JsonRedisSerializer);
template.afterPropertiesSet();
return template;
}
}
- 编写工具类实际使用 RedisUtils工具类
Redis配置文件
#网络
bind 127.0.0.1 # ip
protected-mode yes # 保护模式是否开启
port 6379 # 端口
#通用
daemonize yes # 后台运行,需要修改为yes
pidfile /var/run/redis_6379.pid # 以后台方式运行,指定一个pid文件
loglevel notice # 日志级别
logfile "" # 日志文件名
databases 16 # 数据库的数量,默认为16个
#RDB配置
save 900 1 # 900秒内有1个key进行修改,则进行持久化
save 300 10 # 300秒内有10个key进行修改,则进行持久化
save 60 10000 # 60秒内有10000个key进行修改,则进行持久化
stop-writes-on-bgsave-error yes # 持久化出错后是否继续工作
rdbcompression yes # 是否压缩rdb文件
rdbchecksum yes # 报错rdb文件时候进行错误的检查校验
dbfilename dump.rdb # dbf文件名
dir ./ # rdb文件保存的目录,默认为当前目录
#主从复制
replicaof <masterip> <masterport> # masterip主机IP,masterport主机端口,用于配置主机信息
masterauth <master-password> # 如果主机有密码,这里配置主机密码
replica-read-only yes # 配置从机只读,默认yes
#安全
可以设置Redis密码
#客户端
maxclients 10000 # 客户端最大连接数
maxmemory <bytes> # redis最大的内存容量
maxmemory-policy noeviction # 内存达到上限的处理策略
#内存达到上限的处理策略的6个处理策略
1、noeviction: 不删除策略, 达到最大内存限制时, 如果需要更多内存, 直接返回错误信息。(默认值)
2、allkeys-lru: 所有key通用; 优先删除最近最少使用(LRU) 的 key。
3、volatile-lru: 只限于设置了 expire 的部分; 优先删除最近最少使用(LRU) 的 key。
4、allkeys-random: 所有key通用; 随机删除一部分 key。
5、volatile-random: 只限于设置了 expire 的部分; 随机删除一部分 key。
6、volatile-ttl: 只限于设置了 expire 的部分; 优先删除剩余时间(TTL) 短的key。
#AOF配置
appendonly no # 默认不开启aof模式,默认使用rdb方式持久化
appendfilename "appendonly.aof" # 持久化文件名
# appendfsync always # 每次修改都会同步,消耗性能
appendfsync everysec # 每秒都同步一次 sync,可能会丢失这1s数据
# appendfsync no #误信息。(默认值) 不执行同步,这时候操作系统自己同步数据,速度最快
...
Redis持久化
Redis是内存数据库,如果数据不进行持久化,当服务器进程退出或者服务器断电,数据就会丢失,因此Redis需要进行持久化操作。Redis提供两种持久化操作,即RDB和AOF。
RDB
RDB(Redis Database):在指定的时间间隔内将内存中的数据集快照写入磁盘,实际操作过程是fork一个子进程,先将数据集写入临时文件,写入成功后,再替换之前的文件,用二进制压缩存储,默认生成dump.rdb文件,默认放在redis安装目录,文件名和路径都可以通过配置文件进行修改配置。Redis启动时会自动加载rdb文件。RDB是默认的持久化操作。
Redis.conf配置:下面是默认配置
save 900 1 # 900秒内有1个key进行修改,则进行持久化
save 300 10 # 300秒内有10个key进行修改,则进行持久化
save 60 10000 # 60秒内有10000个key进行修改,则进行持久化
stop-writes-on-bgsave-error yes # 持久化出错后是否继续工作
rdbcompression yes # 是否压缩rdb文件
dbfilename dump.rdb # dbf文件名
rdbchecksum yes # 报错rdb文件时候进行错误的检查校验
dir ./ # rdb文件保存的目录,默认为当前目录
RDB触发机制
- 满足save命令条件
- 执行flushall命令
- 退出Redis
RDB持久化过程:
- Redis 调用forks. 同时拥有父进程和子进程。
- 子进程将数据集写入到一个临时 RDB 文件中。
- 当子进程完成对新 RDB 文件的写入时,Redis 用新 RDB 文件替换原来的 RDB 文件,并删除旧的 RDB 文件。
优点
- RDB文件紧凑,全量备份,非常适合用于进行备份和灾难恢复。
- 生成RDB文件的时候,redis主进程会fork()一个子进程来处理所有保存工作,主进程不需要进行任何磁盘IO操作。
- RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。
缺点
- 需要一定时间间隔进行存储,系统一旦在定时持久化之前出现宕机现象,此前没有来得及写入磁盘的数据都将丢失
- RDB是通过fork子进程来协助完成数据持久化工作的,如果当数据量较大时,还是比较消耗性能
总结:RDB是Redis默认的持久化操作,速度快,但是可能存在数据丢失的情况
AOF
AOF(Append Only File):把所有的对Redis的服务器进行修改的命令(读命令不记录)都存到一个文件里,命令的集合。
Redis.conf配置:下面是默认配置
appendonly no # 默认不开启aof模式,默认使用rdb方式持久化
appendfilename "appendonly.aof" # 持久化文件名
# appendfsync always # 总是写入aof文件,并完成磁盘同步
appendfsync everysec # 每一秒写入aof文件,并完成磁盘同步,可能会丢失这一秒的数据(默认值)
# appendfsync no # 写入aof文件,不等待磁盘同步,操作系统自己调度,速度最快
AOF重写过程(当aof文件过大时执行重写):
- Redis 执行 fork() ,现在同时拥有父进程和子进程。
- 子进程开始将新 AOF 文件的内容写入到临时文件。
- 对于所有新执行的写入命令,父进程一边将它们累积到一个内存缓存中,一边将这些改动追加到现有 AOF 文件的末尾,这样样即使在重写的中途发生停机,现有的 AOF 文件也还是安全的。
- 当子进程完成重写工作时,它给父进程发送一个信号,父进程在接收到信号之后,将内存缓存中的所有数据追加到新 AOF 文件的末尾。
- 现在 Redis 原子地用新文件替换旧文件,之后所有命令都会直接追加到新 AOF 文件的末尾。
优点
- 数据完整性强
- 当文件过大时,提供文件重写功能,同时也能保证重写过程中的数据记录
缺点
- AOF日志文件通常比RDB数据快照文件更大
- 数据恢复慢
总结:AOF较RDB来说,数据完整性更强,能够保证数据的安全性。提供redis-check-aof工具来对aof文件进行修复。
Redis持久化总结:
1.选用哪种持久化操作是根据需求来决定的。Redis支持同时开启两种持久化操作。
2.如果需要进行持久化操作,建议两者都打开,双重保险。在这种情况下,当redis重启的时候会优先载入AOF文件来恢复原始的数据,因为在通常情况下AOF文件保存的数据集要比RDB文件保存的数据集要完整。
3.如果只是做缓存,只希望在服务器运行的时候存在,可以不适用持久化。
Redis主从复制
主从复制:是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(master),后者称为从节点(slave);数据的复制是单向的,只能由主节点到从节点。Master以写为主,Slave以读为主。
主从复制作用
- 读写分离:主节点写,从节点读,提高服务器的读写负载能力
- 数据冗余︰主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。
- 故障恢复︰当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复 ; 实际上是一种服务的冗余。
- 负载均衡︰在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务(即写Redis数据时应用连接主节点,读Redis数据时应用连接从节点),分担服务器负载 ; 尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量。
- 高可用(集群)基石︰除了上述作用以外,主从复制还是哨兵和集群能够实施的基础,因此说主从复制是Redis高可用的基础。
主从复制环境配置
需要几个从机就复制几个配置文件,修改对应的信息
port 6379 # 端口
pidfile /var/run/redis_6379.pid # pid
logfile "" # 日志文件名
dbfilename dump.rdb # dbf文件名
默认每一台服务器都是主节点,只需要进行从机的配置
info replication # 能够查看主从复制相关信息
# 用命令配置主机信息,但是这种配置是暂时的,从机重启后还是会变成主机
slaveof host port # 主机IP为host,主机端口为port
# 配置文件中配置主机信息,永久的
replicaof <masterip> <masterport> # <masterip>主机IP,<masterport>主机端口
masterauth <master-password> # 如果主机有密码,这里配置主机密码
主机可以读写,从机只能读不能写。主机中的所有信息和数据,都会自动同步到从机,从机一旦认定主机,也会自动同步主机信息。主机断开连接,从机依旧连接到主机,但是没有写操作,如果主机重新连接,从机会自动同步主机信息。
哨兵模式
哨兵模式:是一种特殊的模式。在主机宕机后能够自动的选择新主机。哨兵是一个独立的进程,作为进程,它会独立运行。其原理是哨兵通过发送命令,等待Redis服务器响应,从而监控运行的多个Redis实例。
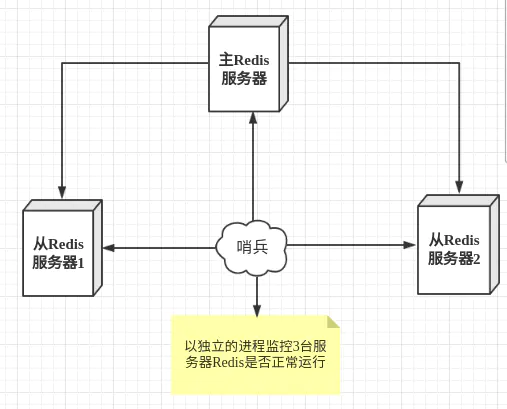
哨兵模式作用:
- 通过发送命令,让Redis服务器返回监控其运行状态,包括主服务器和从服务器。
- 当哨兵监测到master宕机,会自动将slave切换成master,然后通过发布订阅模式通知其他的从服务器,修改配置文件,让它们切换主机。
多哨兵模式:一个哨兵进程对Redis服务器进行监控,可能会出现问题,为此,我们可以使用多个哨兵进行监控。各个哨兵之间还会进行监控,这样就形成了多哨兵模式
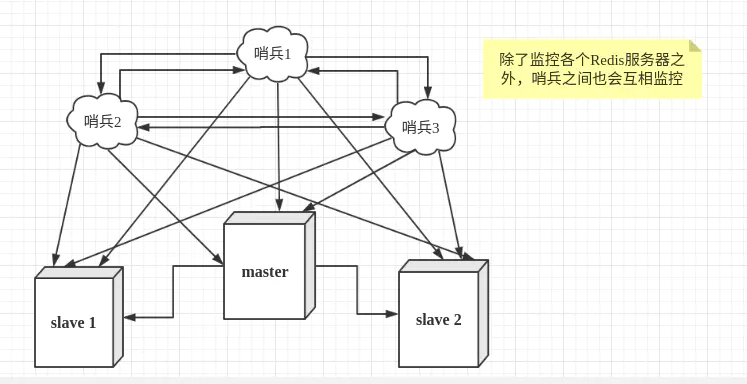
故障切换过程:假设主服务器宕机,哨兵1先检测到这个结果,系统并不会马上进行故障切换过程,仅仅是哨兵1主观的认为主服务器不可用,这个现象成为主观下线。当后面的哨兵也检测到主服务器不可用,并且数量达到一定值时,那么哨兵之间就会进行一次投票,投票由一个哨兵发起,得票高的服务器成为新主机,完成故障切换操作。切换成功后,就会通过发布订阅模式,让各个哨兵把自己监控的从机实现切换主机,这个过程称为客观下线。
哨兵配置流程
- 新建sentinel.conf文件,几个哨兵新建几份
- 配置一下内容
# 关闭保护模式
protected-mode no
# 端口
port 26379
# 配置监听的主服务器,这里sentinel monitor代表监控,mymaster代表服务器的名称,可以自定义,192.168.11.128代表监控的主服务器,6379代表端口,2代表只有两个或两个以上的哨兵认为主服务器不可用的时候,才会进行故障切换操作。
sentinel monitor mymaster 192.168.11.128 6379 2
# (可选)sentinel author-pass定义服务的密码,<master-name>是服务名称,<password>是Redis服务器密码
sentinel auth-pass <master-name> <password>
- 通过redis-sentinel sentinel.conf命令启动哨兵
注意启动顺序,先启动主机,再启动从机,最后启动哨兵
优点
- 对节点进行监控,来完成自动的故障发现与转移
- 哨兵模式是基于主从模式的,所有主从的优点,哨兵模式都具有
缺点
- 在主从切换的瞬间存在访问瞬断的情况,等待时间比较长
- Redis较难支持在线扩容,在集群容量达到上限时在线扩容会变得很复杂
- 主节点只有一个,主节点写压力较大
Redis集群
Redis 的哨兵模式基本已经可以实现高可用,读写分离,但是在这种模式下每台Redis服务器都存储相同的数据,很浪费内存,所以在redis3.0上加入了Cluster 集群模式,实现了Redis的分布式存储,也就是说每台Redis节点上存储不同的内容。
根据官方推荐,集群部署至少要 3 台以上的master节点,最好使用 3 主 3 从六个节点的模式
配置
修改redis.conf中集群配置,
daemonize yes #可选操作,该项设置后台方式运行
port 7000 # 端口
cluster-enabled yes #开启集群模式
cluster-config-file nodes.conf #集群配置文件
cluster-node-timeout 5000 # 集群内节点之间支持最长响应时间
更多集群配置参数可参考默认配置文件redis.conf中Cluster模块的说明
每一个实例都会生成一个Node ID,用来作为Redis实例的集群中的唯一表示,并不是通过IP和Port,因为IP和Port可能会变,但是该Node ID不会改变。
集群工作方式
在 Redis的每一个节点上,都有这么两个东西,一个是插槽(slot),它的的取值范围是:0-16383。还有一个就是cluster,可以理解为是一个集群管理的插件。当我们的存取的Key到达的时候,Redis会根据CRC16的算法得出一个结果,然后把结果对16384求余数,这样每个key都会对应一个编号在0-16383之间的哈希槽,通过这个值,去找到对应的插槽所对应的节点,然后直接自动跳转到这个对应的节点上进行存取操作。
优点
- 所有的Redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽。
- 节点的fail是通过集群中超过半数的节点检测失效时才生效。
- 客户端与 Redis 节点直连,不需要中间代理层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可,就不存在中间节点一说了
Redis缓存穿透、击穿和雪崩
缓存穿透
缓存穿透:访问一个缓存和数据库都不存在的key,此时会直接打到数据库上,并且查不到数据,没法写缓存,所以下一次同样会打到数据库上。此时,缓存起不到作用,请求每次都会走到数据库,流量大时数据库可能会被打挂。此时缓存就好像被“穿透”了一样,起不到任何作用。
解决方案
- 接口校验。在正常业务流程中可能会存在少量访问不存在 key 的情况,但是一般不会出现大量的情况,所以这种场景最大的可能性是遭受了非法攻击。可以在最外层先做一层校验:用户鉴权、数据合法性校验等,例如商品查询中,商品的ID是正整数,则可以直接对非正整数直接过滤等等。
- 缓存空值。当访问缓存和DB都没有查询到值时,可以将空值写进缓存,但是设置较短的过期时间,该时间需要根据产品业务特性来设置。
- 布隆过滤器。使用布隆过滤器存储所有可能访问的 key,不存在的 key 直接被过滤,存在的 key 则再进一步查询缓存和数据库。
缓存击穿
缓存击穿:某一个热点key,在缓存过期的一瞬间,同时有大量的请求打进来,由于此时缓存过期了,所以请求最终都会走到数据库,造成瞬时数据库请求量大、压力骤增,甚至可能打垮数据库。
解决方案
- 使用互斥锁。在并发的多个请求中,只有第一个请求线程能拿到锁并执行数据库查询操作,其他的线程拿不到锁就阻塞,等到第一个线程将数据写入缓存后,直接走缓存。
- 热点数据不过期(根据场景使用)
缓存雪崩
缓存雪崩:大量的热点key设置了相同的过期时间,导在缓存在同一时刻全部失效,造成瞬时数据库请求量大、压力骤增,引起雪崩,甚至导致数据库被打挂。缓存雪崩其实有点像“升级版的缓存击穿”,缓存击穿是一个热点key,缓存雪崩是一组热点 key。
解决方案
- 过期时间打散。既然是大量缓存集中失效,那最容易想到就是让他们不集中生效。可以给缓存的过期时间时加上一个随机值时间,使得每个key的过期时间分布开来,不会集中在同一时刻失效。
- 热点数据不过期。该方式和缓存击穿一样,也是要着重考虑刷新的时间间隔和数据异常如何处理的情况。
- 使用互斥锁。该方式和缓存击穿一样,按key维度加锁,对于同一个key,只允许一个线程去访问数据库,其他线程原地阻塞等待第一个线程的计算结果,然后直接走缓存即可。















 234
234











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









