







从零实现
# 从零实现
import torch
import torchvision
import numpy as np
import sys
sys.path.append("..") # 为了导⼊上层⽬录的d2lzh_pytorch
import d2lzh_pytorch as d2l# 获取和读取数据
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size) #用for返循环读取具体的数据# 初始化模型参数
num_inputs = 784
num_outputs = 10
W = torch.tensor(np.random.normal(0, 0.01, (num_inputs,num_outputs)), dtype=torch.float)
b = torch.zeros(num_outputs, dtype=torch.float)# 模型参数梯度
W.requires_grad_(requires_grad=True)
b.requires_grad_(requires_grad=True) ![]()
# 定义softmax函数
def softmax(X):
X_exp = X.exp()
partition = X_exp.sum(dim=1, keepdim=True) #行求和
return X_exp / partition # 这⾥应⽤了⼴播机制# 例子
X = torch.rand((2, 5))
X_prob = softmax(X)
print(X)
print(X_prob, X_prob.sum(dim=1)) 
# 定义模型
def net(X):
return softmax(torch.mm(X.view((-1, num_inputs)), W) + b)# 定义损失函数
def cross_entropy(y_hat, y):
return - torch.log(y_hat.gather(1, y.view(-1, 1)))
# 注意这里为什么是找到对应的概率,然后直接取负对数
# 因为标签值实际上是一个one-hot向量,只有一个1,其余都是0,而1对应的就是预测的概率值
# 至于cross-entropy公式怎么来的,并不关心
# 例子
y_hat = torch.tensor([[0.1, 0.3, 0.6], [0.3, 0.2, 0.5]])
y = torch.LongTensor([0, 2])
print(y_hat.gather(1, y.view(-1, 1))) #gather函数表示用行(1)或者列(0)索引,求对应位置的值
# print("*"*50)
print(cross_entropy(y_hat,y))

# 计算分类准确率
def accuracy(y_hat, y):
return (y_hat.argmax(dim=1) == y).float().mean().item()print(accuracy(y_hat, y)) #0.5
print(net) #<function net at 0x000001EF5BC40598># 训练模型
num_epochs, lr = 5, 0.1
# 本函数已保存在d2lzh包中⽅便以后使⽤
def train_ch3(net, train_iter, test_iter, loss, num_epochs,
batch_size,params=None, lr=None, optimizer=None):
for epoch in range(num_epochs):
train_l_sum, train_acc_sum, n = 0.0, 0.0, 0
for X, y in train_iter:
y_hat = net(X)
l = loss(y_hat, y).sum()
# 梯度清零
if optimizer is not None:
optimizer.zero_grad()
elif params is not None and params[0].grad is not None:
for param in params:
param.grad.data.zero_()
l.backward()
if optimizer is None:
d2l.sgd(params, lr, batch_size)
else:
optimizer.step() # “softmax回归的简洁实现”⼀节将⽤到
train_l_sum += l.item()
train_acc_sum += (y_hat.argmax(dim=1) ==y).sum().item()
n += y.shape[0]
test_acc = evaluate_accuracy(test_iter, net)
print('epoch %d, loss %.4f, train acc %.3f, test acc %.3f'
% (epoch + 1, train_l_sum / n, train_acc_sum / n,test_acc))train_ch3(net, train_iter, test_iter,
cross_entropy, num_epochs,batch_size, [W, b], lr)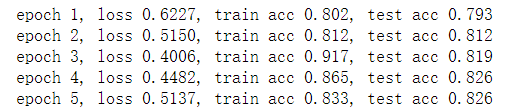
# 预测
X, y = iter(test_iter).next()
print(net(X)[0],net(X).shape) #net的输出就是一个256x10的矩阵,每一行sum都是1
true_labels = d2l.get_fashion_mnist_labels(y.numpy()) #这里因为y是tensor所以要转换为numpy
pred_labels =d2l.get_fashion_mnist_labels(net(X).argmax(dim=1).numpy())
titles = [true + '\n' + pred for true, pred in zip(true_labels,pred_labels)]
d2l.show_fashion_mnist(X[0:9], titles[0:9])
简化版
# 导包
import torch
from torch import nn
from torch.nn import init
import numpy as np
import sys
sys.path.append("..")
import d2lzh_pytorch as d2l# 读取数据和读取
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
num_inputs = 784
num_outputs = 10创建网络:方式1
# 定义初始化模型,这部分可以不运行,下面重新定义了更简化的,习惯用哪个就用哪个
class LinearNet(nn.Module):
def __init__(self, num_inputs, num_outputs):
super(LinearNet, self).__init__()
self.linear = nn.Linear(num_inputs, num_outputs)
def forward(self, x): # x shape: (batch, 1, 28, 28)
y = self.linear(x.view(x.shape[0], -1))
return y
net = LinearNet(num_inputs, num_outputs)print(net)
for param in net.parameters():
print(param,param.shape)
创建网络:方式二
# 我们将对 x 的形状转换的这个功能⾃定义⼀个 FlattenLayer 并记录在 d2lzh_pytorch 中⽅便后⾯使⽤
# 本函数已保存在d2lzh_pytorch包中⽅便以后使⽤
class FlattenLayer(nn.Module):
def __init__(self):
super(FlattenLayer, self).__init__()
def forward(self, x): # x shape: (batch, *, *, ...)
return x.view(x.shape[0], -1)# 这样我们就可以更⽅便地定义我们的模型:
from collections import OrderedDict
net = nn.Sequential(
# FlattenLayer(),
# nn.Linear(num_inputs, num_outputs)
OrderedDict([
('flatten', FlattenLayer()),
('linear', nn.Linear(num_inputs, num_outputs))])
) #注意这nn.Module和nn.Sequential的区别print(net)
for param in net.parameters():
print(param,param.shape)
# 然后,我们使⽤均值为0、标准差为0.01的正态分布随机初始化模型的权重参数。
import random
np.random.seed(1) #加随机数保证参数唯一,这里可以看出,网络一旦定义就会有个初始化的值
init.normal_(net.linear.weight, mean=0, std=0.01)
init.constant_(net.linear.bias, val=0)# SOFTMAX和交叉熵损失函数
# 如果做了上⼀节的练习,那么你可能意识到了分开定义softmax运算和交叉熵损失函数可能会造成数值
# 不稳定。因此,PyTorch提供了⼀个包括softmax运算和交叉熵损失计算的函数。它的数值稳定性更好
loss = nn.CrossEntropyLoss()# 定义优化算法
optimizer = torch.optim.SGD(net.parameters(), lr=0.1)# 训练模型,跟前面的训练一样
num_epochs = 5
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs,
batch_size, None, None, optimizer)















 1011
1011











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









