







Two-Stream Convolutional Networks for Action Recognition in Videos
最近阅读了视频动作识别中一篇经典的Two-stream识别方法,本文对文中的主要做法做一些大致的描述。如有问题,可以留言讨论。
一、本文主要的贡献如下:
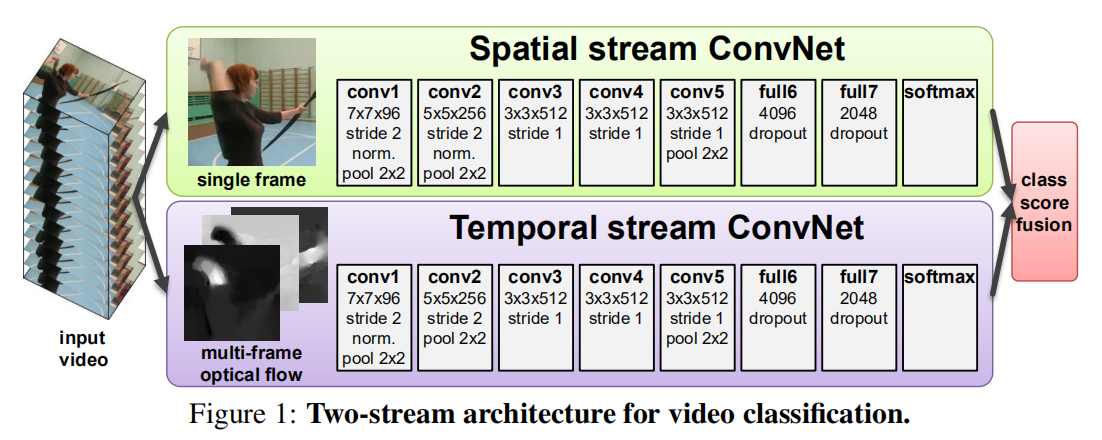
- 提出了一种 two-stream 卷积网络结构, 分别为时间以及空间网络的结合,即two-stream(个人认为是文中最重要的贡献),其结构如Figure 1所示;
- 证实了尽管在有限数据集的情况下,使用多帧稠密光流场作为输入训练的卷积网络表现依然是不错的;
- 由于受训练数据的限制,作者使用了multi-task learning的方法,它既能增加训练数据同时也提高了模型的表现。
二、简略的介绍文章的内容
1. Spatial stream ConvNet:
空间流卷积,就是将视频帧作为一张一张图片在卷积网络中进行训练,有效地从静止图像中执行动作识别。这样的分类网络其实有很多,例如AlexNext,GoogLeNet等,可以现在imageNet上预训练,再进行参数迁移。文中使用的是 Pre-training on ImageNet ILSVRC-2012。
2. Temporal stream ConvNet :
文中使用the input to our model is formed by stacking optical flow displacement fields between several consecutive frames,即是通过在几个连续帧之间光流位移形成的stack作为模型的输入(翻译的不好,原句已贴出),作者在文中考量了几种基于光流的不同变体:

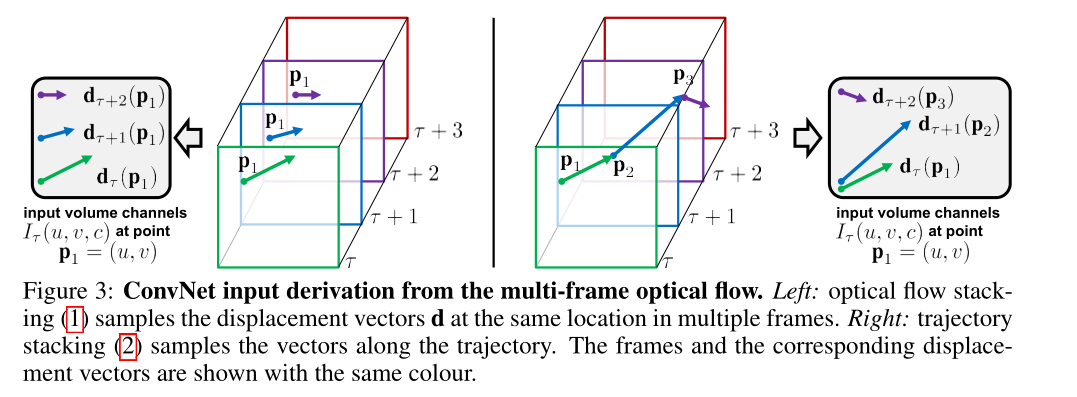
2.1. Optical flow stacking : 这种光流可以被视为在连续帧对
t
t
t和
t
+
1
t+1
t+1之间的一组位移矢量场
d
t
dt
dt,光流场如上
(
c
)
(c)
(c)所示,不懂的话请参考:光流,注意作者将光流作为输入时,分别将
x
x
x轴方向以及
y
y
y轴方向作为作为输入的两个通道;
2.2. Trajectory stacking: 这使得我想起了传统的动作识别的方法iDT,所谓的轨迹就是指一个
i
n
t
e
r
e
s
t
interest
interest
p
o
i
n
t
point
point从
t
t
t时间移动到
t
+
1
t+1
t+1时间的那个
p
o
i
n
t
point
point,这时候stack不是记录光流的位移矢量(u,v)而记录了轨迹位移上的点,如下图所示;
2.3.Bi-directional optical flow:上述两个方法其实考虑的都是前馈光流,我们都是依靠后一帧计算相对于前一帧的光流。当我们考虑T帧时,我们不再一直往后堆L帧,而是计算T帧之前L/2和T帧之后的L/2帧。
2.4. Mean flow subtraction :从每个位移场
d
t
d_t
dt中减去它的平均向量,这是为了缓解摄像头运动引起的相对位移。
3. Multi-task learning
对于空间卷积网络,因为它输入的只是图像,而且只是一个分类网络,它有大量的数据集可供预训练,这是为了应对过拟合的问题。但是对于时间卷积网络,可供训练的视频集很少。作者使用多任务训练的方法,提供两个softmax输出层,但网络只有一个。论文的依据是,提供两个softmax输出层相当于正则化的过程。这样融合两个数据集对网络进行训练时,其中一个softmax层对其中一个数据集的视频进行分类,另一个softmax层对另一个数据集进行分类,在最后BP(后向传播)算法时,把两个softmax层的输出加和,作为总的误差执行BP算法更新网络的权值。
论文之后的内容是详细讲解网络执行步骤的一些细节以及实验结果对比,感兴趣的话可以阅读原论文。















 5571
5571











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









