







推荐大体上可以分为两种:非定制化推荐 和 定制化推荐。
非定制化推荐 即 什么热门推荐什么,什么被浏览、购买得多就推荐什么。所谓的“热门”即是经过大数据统计而得来的,所以非定制化推荐可以说是一种基于统计学推荐。
定制化推荐 即 个性化推荐,针对不同用户的历史行为记录中分析用户对产品的偏好,猜测用户喜欢什么,从而进行推荐。
非定制化推荐的弊端很明显,热门产品并不总是每个用户喜欢的,可应用的场景也相对较少。相反,定制化推荐对不同用户的个性化推荐就有了相对明显的优势。因此,目前市场上定制化推荐算法层出不穷。
一、定制化推荐算法分类
定制化推荐算法大体上可以细分为以下五类,而前两种(基于内容推荐、基于协同过滤)则是最为常用的。其中,协同过滤算法又是推荐系统中的明星算法。那么,协同过滤到底是什么意思呢?协同过滤 侧重于从大数据(集体智慧)中寻找某些隐含的模式(我也不太懂,网上都解释不清楚!)
(1)基于内容(content based):根据用户的历史数据衡量用户对物品的喜好程度,计算物品相似度,推荐相似物品。
(2)基于协同: 基于协同过滤的推荐算法又可分为以下三类:
基于内容的协同过滤:根据所有用户对物品或者信息的评价,发现物品和物品之间的相似度,然后根据用户的历史偏好信 息将类似的物品推荐给该用户。
基于用户的协同过滤:寻找与目标用户有相同喜好的邻居,然后根据目标用户的邻居的喜好产生向目标用户的推荐。
基于模型的协同过滤:基模型的协同过滤推荐就是基于样本的用户喜好信息,训练一个推荐模型,然后根据实时的用户喜 好的信息进行预测推荐。根据训练推荐模型的方式的不同又可以分为以下四种:
a、基于分类、回归和聚类的模型
b、基于图的模型(Personal Rank)
c、基于矩阵分解的模型(LFM、CF)
d、基于神经网络的模型(item2vec)
(3)基于关联规则:通过关联规则挖掘找到不同商品在销售过程中的相关性,推荐相关物品。
(4)基于效用:
(5)基于知识:
二、实现的四种推荐算法
1)content based(基于内容)
2)LFM(基于矩阵分解模型的协同过滤)
3)CF(基于矩阵分解模型的协同过滤)
4)Personal Rank(基于图模型的协同过滤)
2.1基于矩阵分解的隐语义模型算法LFM(latent factor model)
LFM(latent factor model)隐语义模型核心思想是通过隐含特征联系用户和物品。通过如下公式计算用户u对电影i的兴趣:
| preferenceu,i=rLFMu,i=puTqi=f=1Fpu,fqi,f | (1) |
定义P矩阵是user-factor矩阵,矩阵值pu,k![]() 表示的是用户 u对隐含特征 f的偏好度;Q矩阵式factor-item矩阵,矩阵值qi,k
表示的是用户 u对隐含特征 f的偏好度;Q矩阵式factor-item矩阵,矩阵值qi,k![]() 表示的是隐含特征 f在电影 i中的权重,权重越高该item的特征性越强。如下图:
表示的是隐含特征 f在电影 i中的权重,权重越高该item的特征性越强。如下图:
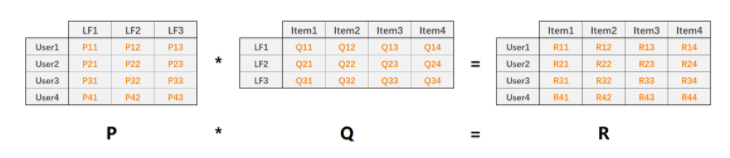
图 1
我们用监督学习的思想来得到pu![]() 和qi
和qi![]() 。在设定好隐含特征的个数F之后,
。在设定好隐含特征的个数F之后,![]() 和
和![]() 可以用随机正态分布初始化,并采用梯度下降进行迭代。迭代时需要计算损失函数loss:
可以用随机正态分布初始化,并采用梯度下降进行迭代。迭代时需要计算损失函数loss:
| loss=(u,i)∈D(ru,i-rLFM(u,i))2 | ( 2) |
ru,i![]() 是训练样本的label,也就是说如果用户对电影感兴趣,那么r(u,i)=1,否则r(u,i)=0。rLFM(u,i)
是训练样本的label,也就是说如果用户对电影感兴趣,那么r(u,i)=1,否则r(u,i)=0。rLFM(u,i)![]() 是模型预估的用户对电影的偏好度,也就是前面所说的模型产出的参数
是模型预估的用户对电影的偏好度,也就是前面所说的模型产出的参数![]() 和
和![]() 转置的乘积。这里的D是所有的训练样本的集合。
转置的乘积。这里的D是所有的训练样本的集合。
可以看到如果模型预估的数值与label越接近的话,损失函数数值越小,反之则越大。这里为了防止过拟合,增加了正则化项,并进行展开,得到如下:
| loss=(u,i)∈D(ru,i-rLFM(u,i))2+α|pu|2+α|qi|2 | (3) |
这里α![]() 是正则化系数,这里采用的是L2正则化,正则化目的是为了让模型更加简单化,防止由于
是正则化系数,这里采用的是L2正则化,正则化目的是为了让模型更加简单化,防止由于![]() 和
和![]() 过度拟合训练样本中的数据使模型的参数过度复杂,造成泛化能力减弱。求出损失函数loss后,分别对pu,f
过度拟合训练样本中的数据使模型的参数过度复杂,造成泛化能力减弱。求出损失函数loss后,分别对pu,f![]() 、qi,f
、qi,f![]() 求偏导:
求偏导:
| ∂loss∂pu,f=-2ru,i-rLFM(u,i)qi,f+2αpu,f | (4) |
| ∂loss∂qi,f=-2ru,i-rLFM(u,i)pu,f+2αqi,f | (5) |
得到偏导后,采用梯度下降的方法更新pu,f![]() 和qi,f
和qi,f![]() 的值:
的值:
| pu,f=pu,f-β∂loss∂pu,f | (6) |
| qi,f=qi,f-β∂loss∂qi,f | (7) |
其中,β![]() 是learning rate,即学习率。
是learning rate,即学习率。
2.1.3算法评估
对于算法的性能,我们将采用均方根误差进行评估,均方根误差越小,算法性能越好。
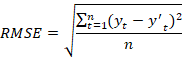
其中![]() 真实评分,
真实评分,![]() 为预测评分,n为样本个数。
为预测评分,n为样本个数。
哪些参数的设定会影响最终的模型效果?
1.负样本的选取
比起正样本,负样本的数量是非常多的。因为展现给用户的电影比用户评分的电影要多的多,而用户未评分的电影都属于负样本。因此,我们要有一定的负采样规则,我们选取那些充分展现(即对于所有用户而言,具有高评分的电影)而用户没有评分或评分较低的电影作为负样本。然后,为了保证正负例样本的均衡,将负例样本按评分排序,取前n个与正例样本数目相同的负例样本。比如,一个用户有100个正例样本,那么同样也取100个负样本来保证正负样本的均衡。
2.隐含特征个数F、正则参数![]() 、学习率
、学习率![]()
以上是对模型比较重要的三个参数。其中![]() 通常设置为0.01-0.05,
通常设置为0.01-0.05,![]() 通常设置0.1-0.5,隐特征个数F通常设置为10-32之间。
通常设置0.1-0.5,隐特征个数F通常设置为10-32之间。
2.1.4算法分析
优点:
1、典型的机器学习算法,有比较好的数学理论基础
2、指标一般会稍高于ItemCF和UserCF
3、训练过程中占用较少的内存
缺点:
1、由于需要迭代,计算时间要多于ItemCF或UserCF
2、不能在线实时计算
3、难以解释模型的合理性
2.2基于图模型的协同过滤算法Personal Rank
2.2.1算法描述
在电影推荐系统中,我们可以把历史用户评分数据用二部图(二分图)的形式表示,如图1.2。大写字母为用户,小写字母为电影。
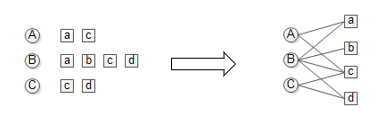
给用户u推荐电影就可以转化为度量用户顶点Vu和与Vu没有直接边相连的电影顶点在图上的相关性,相关性越高的电影在推荐列表上的权重就越高,推荐位置就越靠前。而相关性较高的一对顶点一般具有如下特征:
- 两个顶点之间有很多路径相连
2)连接两个顶点之间的路径长度都比较短
3)连接两个顶点之间的路径不会经过出度比较大的顶点
对A进行个性化推荐:
从用户A结点开始在用户-物品二分图随机游走,以alpha的概率从A的出边中等概率地选择一条出边游走过去,假设游走到了结点a,又可以以alpha的概率从a的出边中等概率地继续游走到下一个结点,或者以(1-alpha)的概率回到起点A,多次迭代,直到各结点对用户A的重要度收敛。
也就是说,每次游走都有alpha的概率游走到下一个结点,或者1-alpha的概率回到起点,而游走到下一个结点时,选择出边的概率是相等的。alpha在0-1,需根据经验设置(0.6-0.8)。
PR(v) = 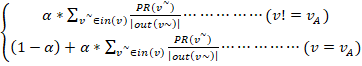
2.2.4算法分析
虽然PersonalRank算法可以通过随机游走进行比较好的理论解释,但该算法在时间复杂度上有明显的缺点。因为在为每个用户进行推荐时,都需要在整个用户物品二分图上进行迭代,直到整个图上的每个顶点的PR值收敛。这一过程的时间复杂度非常高,不仅无法在线提供实时推荐,甚至离线生成推荐结果也很耗时。
2.3 基于内容的推荐算法Content Based
2.3.1算法描述
Content Based算法是基于内容的推荐算法,具有用户推荐的独立性,即推荐结果不受到其他用户的影响。Content Based算法的流程如下:
(1)对内容的划分。对内容的划分方式有两种:关键词划分和类别划分。例如一篇新闻,我们可以对其进行关键词划分如“奥运会”、“世界杯”,也可以对其进行类别划分如“体育”、“财经”等。在本次的推荐算法中,采用的是类别划分的方式对电影数据集进行内容的划分。
(2)对内容排序。根据用户评分数据集,对不同分类下的电影计算平均评分并排序。
(3)对用户的划分。我们基于用户评分数据集对用户的电影类型偏好度进行计算,从而得到用户的电影类型偏好。
(4)线上推荐。根据用户的电影类型偏好,将该类型的高评分电影推荐给用户。
2.3.3算法分析
优点:
1、思路极简,可解释性强
2、具有用户推荐的独立性
3、问世较早,流行度高
缺点:
1、对于推荐的扩展性差(倾向于在单一领域内不断挖掘)
2、需要积累一定量的用户行为




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











