







电影中单纯而美好的爱情总是让人陷入美好无瑕的幻想。
代码已上传至个人GitHub,可供查看:获取豆瓣电影爱情片榜单封面图片
爬虫:获取豆瓣电影爱情片榜单封面图片
目的:获取豆瓣电影爱情片榜单封面图片,并保存到本地。
思路:
1、分析网页URL,查看规律
2、敲代码(图片名设置为该电影名称)
一、打开豆瓣电影分类排行榜-爱情片,F12审查元素
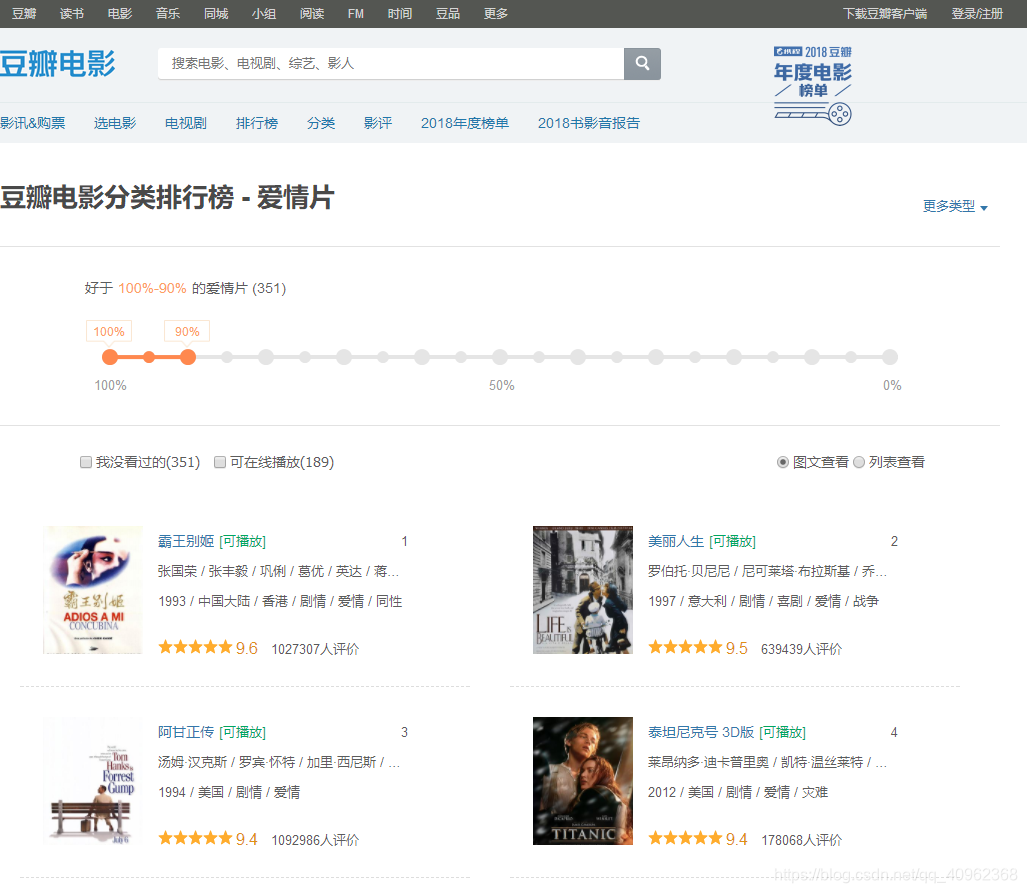
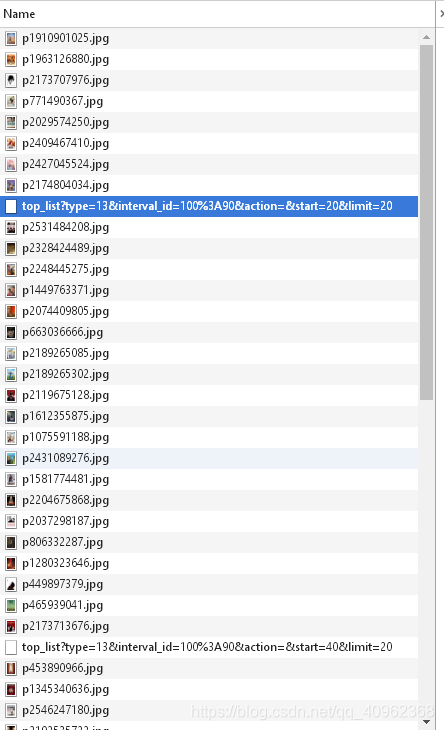
在向下滑动的过程中,发现如下规律,每过20张图片就出现一个url,查看URL,就可以发现一些马脚

![]()
![]()
![]()
![]()
通过对网页和URL的分析,可以得出以下结论:
- 每过20张图片就出现一个URL,即翻页,所以每页的图片数量为20张,这在URL中也有体现:limit=20;
- URL中的start=xx表示该页是从第几张开始的;
- URL中的interval_id=100%3A90表示的是评价在前10%的电影;
- URL中的type=13表示的是电影类型的代号,13指的是爱情片;
- 在以上条件的限制下,满足要求的电影数量为351部。
二、上代码,为了防止IP被封,我使用了一些代理,并随机设置了睡眠时间,能够更有效的获取数据
from urllib import request
import json
import time
import randomclass douban_love_moives():
def __init__(self, k):
self.k = k
def load_moive(self, start):
url = 'https://movie.douban.com/j/chart/top_list?type=13&interval_id=100%3A90&action=&start=' + str(
start) + '&limit=20'
time.sleep(random.randint(1, 4))
rsp = request.urlopen(url)
json_data = json.loads(rsp.read().decode())
for moive in json_data:
self.k += 1
time.sleep(random.randint(2, 5))
try:
request.urlretrieve(moive['cover_url'], 'F:\文件存放处\爱情片电影封面\\' + moive['title'] + '.jpg')
print('第' + str(self.k) + '张图片下载成功:' + moive['cover_url'])
except Exception:
print('第' + str(self.k) + '张图片下载失败:' + moive['cover_url'])
def get_moives(self):
for start in range(0, 351, 20):
# 使用代理步骤
# - 1、设置代理地址
proxys = [{'http': '39.137.69.10:8080'},
{'http': '60.255.186.169:8888'},
{'http': '117.191.11.108:80'}]
# - 2、创建ProxyHandler
proxy = random.choice(proxys)
proxy_handler = request.ProxyHandler(proxy)
# - 3、创建Opener
opener = request.build_opener(proxy_handler)
# - 4、导入Opener
request.install_opener(opener)
self.load_moive(self.k)
if __name__ == '__main__':
print('开始下载图片......')
moive = douban_love_moives(k=0)
moive.get_moives()运行结果:

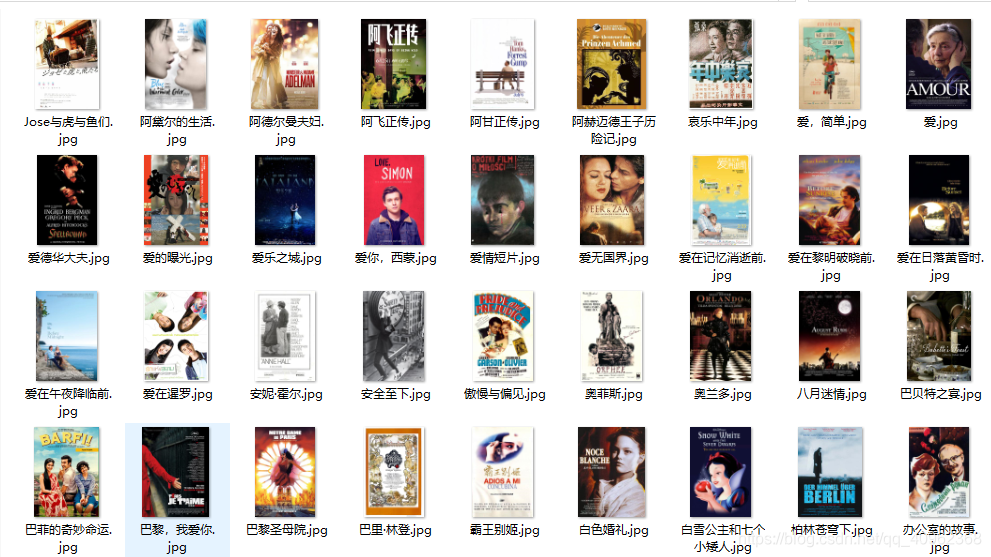
代码已上传至个人GitHub,可供查看:获取豆瓣电影爱情片榜单封面图片


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









