







AMQP协议定义
AMQP(Advanced Message Queuing Protocol,高级消息队列协议)是一个进程间传递异步消息的网络协议。

消息队列的定义
- 消息队列: 简称它为MQ(Message Queue)
- 生产者: 把数据放到消息队列叫做生产者
- 消费者:从消息队列里边取数据叫做消费者
消息队列的好处
优势: 解耦、异步、消峰(限流)
使用场景:使用场景
常用的消息队列
| 特性 | ActiveMQ | RabbitMQ | RocketMQ | Kafka |
|---|---|---|---|---|
| 单机吞吐量 | 万级,比 RocketMQ、Kafka 低一个数量级 | 同 ActiveMQ | 10 万级,支撑高吞吐 | 10 万级,高吞吐,一般配合大数据类的系统来进行实时数据计算、日志采集等场景 |
| topic 数量对吞吐量的影响 | topic 可以达到几百/几千的级别,吞吐量会有较小幅度的下降,这是 RocketMQ 的一大优势,在同等机器下,可以支撑大量的 topic | topic 从几十到几百个时候,吞吐量会大幅度下降,在同等机器下,Kafka 尽量保证 topic 数量不要过多,如果要支撑大规模的 topic,需要增加更多的机器资源 | ||
| 时效性 | ms 级 | 微秒级,这是 RabbitMQ 的一大特点,延迟最低 | ms 级 | 延迟在 ms 级以内 |
| 可用性 | 高,基于主从架构实现高可用 | 同 ActiveMQ | 非常高,分布式架构 | 非常高,分布式,一个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可用 |
| 消息可靠性 | 有较低的概率丢失数据 | 基本不丢 | 经过参数优化配置,可以做到 0 丢失 | 同 RocketMQ |
| 功能支持 | MQ 领域的功能极其完备 | 基于 erlang 开发,并发能力很强,性能极好,延时很低 | MQ 功能较为完善,还是分布式的,扩展性好 | 功能较为简单,主要支持简单的 MQ 功能,在大数据领域的实时计算以及日 |
选择用哪种消息队列
一般的业务系统要引入MQ,最早大家都用ActiveMQ,但是现在确实大家用的不多了,没经过大规模吞吐量场景的验证,社区也不是很活跃
后来大家开始用RabbitMQ,但是确实erlang语言阻止了大量的java工程师去深入研究和掌控他,对公司而言,几乎处于不可控的状态,但是确实人家是开源的,比较稳定的支持,活跃度也高;
不过现在确实越来越多的公司,会去用RocketMQ,确实很不错,但是要想好社区万一突然黄掉的风险
所以中小型公司,技术实力较为一般,技术挑战不是特别高,用RabbitMQ是不错的选择;大型公司,基础架构研发实力较强,用RocketMQ是很好的选择
如果是大数据领域的实时计算、日志采集等场景,用Kafka是业内标准的,绝对没问题,社区活跃度很高,绝对不会黄,何况几乎是全世界这个领域的事实性规范
使用消息队列需要考虑的问题
JDK实现的队列种类虽然有很多种,但是都是简单的内存队列。满足不了我们的需求 所以需要我们的中间件
高可用
无论是我们使用消息队列来做解耦、异步还是削峰,消息队列肯定不能是单机的。试着想一下,如果是单机的消息队列,万一这台机器挂了,那我们整个系统几乎就是不可用了。所以在开发过程中一般都是分布式的
数据丢失问题
我们将数据写到消息队列上,系统B和C还没来得及取消息队列的数据,就挂掉了。如果没有做任何的措施,我们的数据就丢了。所以一般需要把他们存储一下
- 存储的地方
磁盘?
数据库?
Redis?
分布式文件系统? - 同步存储还是异步存储?
消费者怎么得到消息队列的数据?
消费者怎么从消息队列里边得到数据?有两种办法:
生产者将数据放到消息队列中,消息队列有数据了,主动叫消费者去拿(俗称push)
消费者不断去轮训消息队列,看看有没有新的数据,如果有就消费(俗称pull)
RabbitMQ的简介与安装
RabbitMQ的5种模式与Activemq的2种模式
RabbitMQ的5种模式
rabbitMQ的5种模式
简单队列模式、工作队列模式、发布订阅模式、路由模式、主题模式,以下将大概说一下,具体百度
rabbitMQ的代码案例
简单队列模式
只包含一个生产者以及一个消费者,生产者Producer将消息发送到队列中,消费者Consumer从该队列接收消息。(单生产单消费)
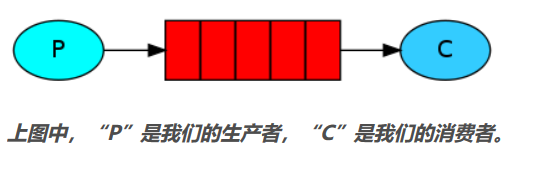
生产者发送消息到队列上:
 消费者从队列上取出消息:
消费者从队列上取出消息:

工作队列模式
多个消费者绑定到同一个队列上,一条消息只能被一个消费者进行消费。工作队列有轮训分发和公平分发两种模式。
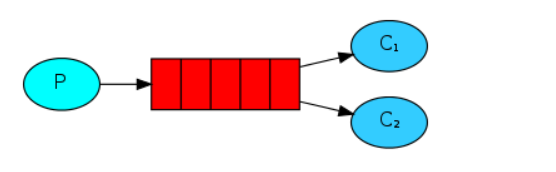
发布-订阅模式(Publish/Subscribe)
生产者将消息发送到交换器,然后交换器绑定到多个队列,监听该队列的所有消费者消费消息
思路解读(重点理解):
(1)一个生产者,多个消费者
(2)每一个消费者都有自己的一个队列
(3)生产者没有直接发消息到队列中,而是发送到交换机
(4)每个消费者的队列都绑定到交换机上
(5)消息通过交换机到达每个消费者的队列
该模式就是Fanout Exchange(扇型交换机)将消息路由给绑定到它身上的所有队列

交换机的类型
生产者发送消息不会向传统方式直接将消息投递到队列中,而是先将消息投递到交换机中,在由交换机转发到具体的队列,队列在将消息以推送或者拉取方式给消费者进行消费,这和我们之前学习Nginx有点类似。
交换机的作用根据具体的路由策略分发到不同的队列中,交换机有四种类型。
Direct exchange(直连交换机)是根据消息携带的路由键(routing key)将消息投递给对应队列的
Fanout exchange(扇型交换机)将消息路由给绑定到它身上的所有队列
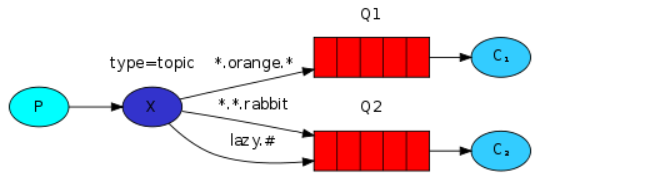
Topic exchange(主题交换机)队列通过路由键绑定到交换机上,然后,交换机根据消息里的路由值,将消息路由给一个或多个绑定队列
Headers exchange(头交换机)类似主题交换机,但是头交换机使用多个消息属性来代替路由键建立路由规则。通过判断消息头的值能否与指定的绑定相匹配来确立路由规则。
路由模式(Routing)
生产者将消息发送到direct交换器,它会把消息路由到那些binding key与routing key完全匹配的Queue中,这样就能实现消费者有选择性地去消费消息。

主题(Topic)模式
类似于正则表达式匹配的一种模式。主要使用#、*进行匹配。
#表示多个
*表示1个
DefaultConsumer与QueueingConsumer
原来QueueingConsumer内部用LinkedBlockingQueue来存放消息的内容,而LinkedBlockingQueue:一个由链表结构组成的有界队列,照先进先出的顺序进行排序 ,未指定长度的话,默认 此队列的长度为Integer.MAX_VALUE,那么问题来了,如果生产者的速度远远大于消费者的速度,也许没等到队列阻塞的条件产生(长度达到Integer.MAX_VALUE)内存就完蛋了,在老的版本你可以通过设置 rabbitmq的prefetch属性channel.basicQos(prefetch)来处理这个问题如果不设置可能出现内存问题(比如因为网络问题只能向rabbitmq生产不能消费,消费者恢复网络之后就会有大量的数据涌入,出现内存问题,oom fgc等)。















 142
142











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









