







 这篇博客介绍了如何利用线性回归模型预测PM2.5含量。作者根据9小时的气象观测数据来预测第10个小时的PM2.5,详细阐述了数据预处理、模型建立(包括回归模型、损失函数、梯度更新和学习率调整)、源代码实现以及模型改进的策略。
这篇博客介绍了如何利用线性回归模型预测PM2.5含量。作者根据9小时的气象观测数据来预测第10个小时的PM2.5,详细阐述了数据预处理、模型建立(包括回归模型、损失函数、梯度更新和学习率调整)、源代码实现以及模型改进的策略。
1、作业说明
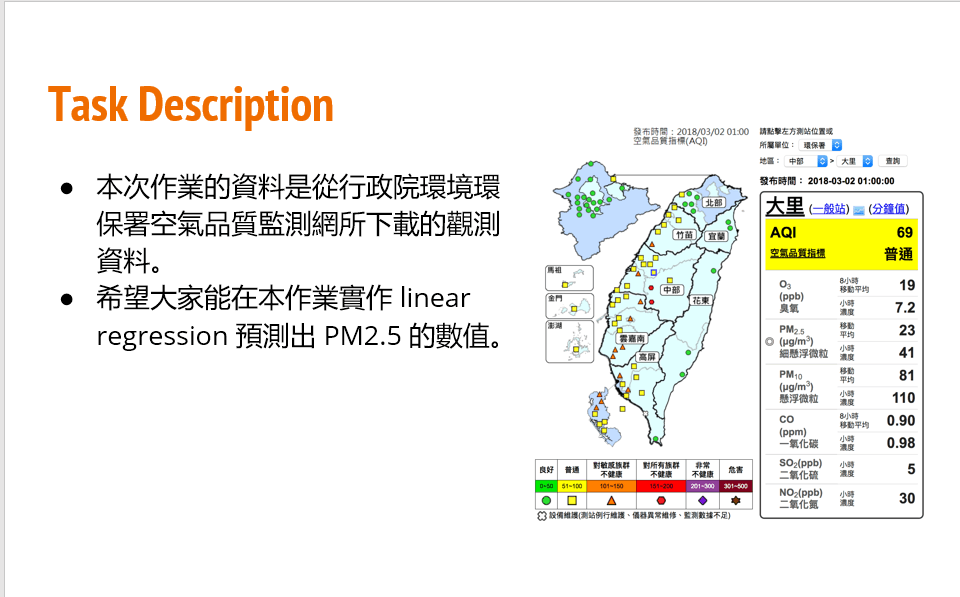

给定训练集train.csv,要求根据前9个小时的空气监测情况预测第10个小时的PM2.5含量。
训练集介绍:
(1)、CSV文件,包含台湾丰原地区240天的气象观测资料(取每个月前20天的数据做训练集,12月X20天=240天,每月后10天数据用于测试,对学生不可见);
(2)、每天的监测时间点为0时,1时......到23时,共24个时间节点;
(3)、每天的检测指标包括CO、NO、PM2.5、PM10等气体浓度,是否降雨、刮风等气象信息,共计18项;
(4)数据集地址:https://pan.baidu.com/s/1GBIPDhA8Xt63tVTt5D3LSQ 提取码:wugw
2、数据预处理
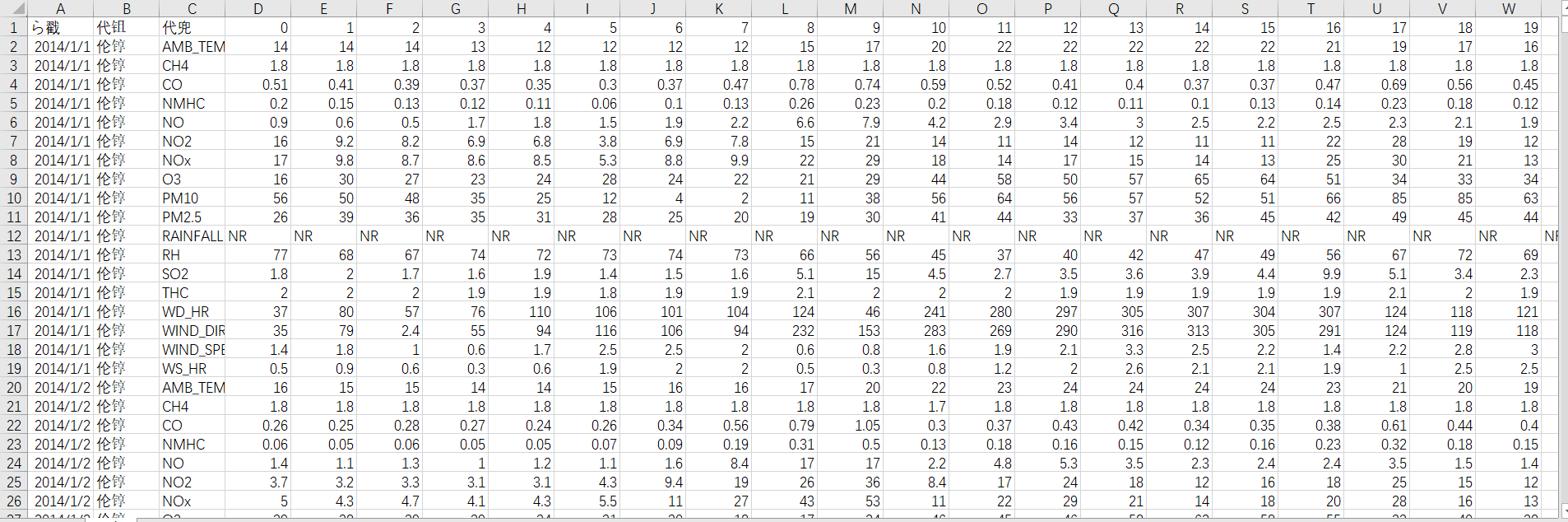
第一行是说明,分别是时间,地点,各空气中物质的名称,以及0-23时他们的浓度。
注意RAINFALL参数的值是NR,表示没有下雨,那么我们就可以将它的值改为0这样便于处理。
我们第一步肯定是数据预处理啦,因为在python中数据是通过矩阵来保存的,所以我们第一步就是删减掉不需要的行与列,然后将其保存到矩阵中。
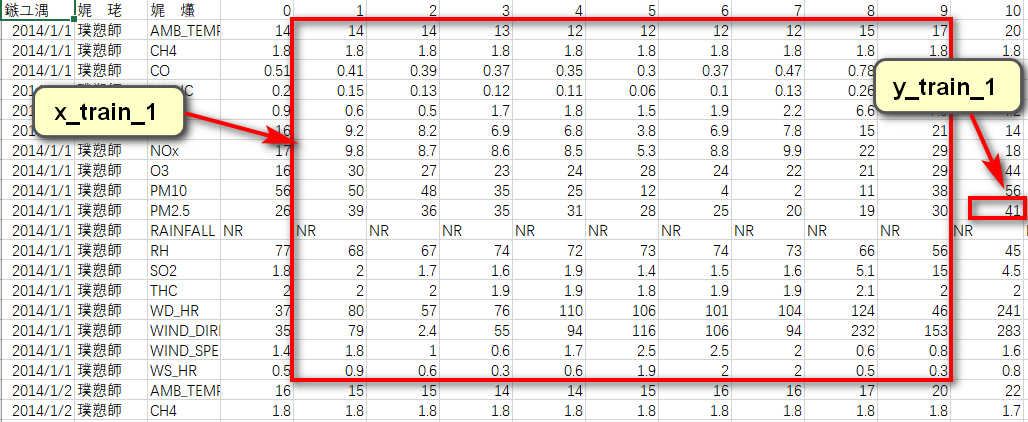
根据作业要求可知,需要用到连续9个时间点的气象观测数据,来预测第10个时间点的PM2.5含量。针对每一天来说,其包含的信息维度为(18,24)(18项指标,24个时间节点)。可以将0到8时的数据截取出来,形成一个维度为(18,9)的数据帧,作为训练数据,将9时的PM2.5含量取出来,作为该训练数据对应的label;同理可取1到9时的数据作为训练用的数据帧,10时的PM2.5含量作为label......以此分割,可将每天的信息分割为15(24-9)个shape为(18,9)的数据帧和与之对应的15个label。训练集中共包含240天的数据,因此共可获得240X15=3600个数据帧和与之对应的3600个label。
# 引入必要的包
import pandas as pd
import numpy as np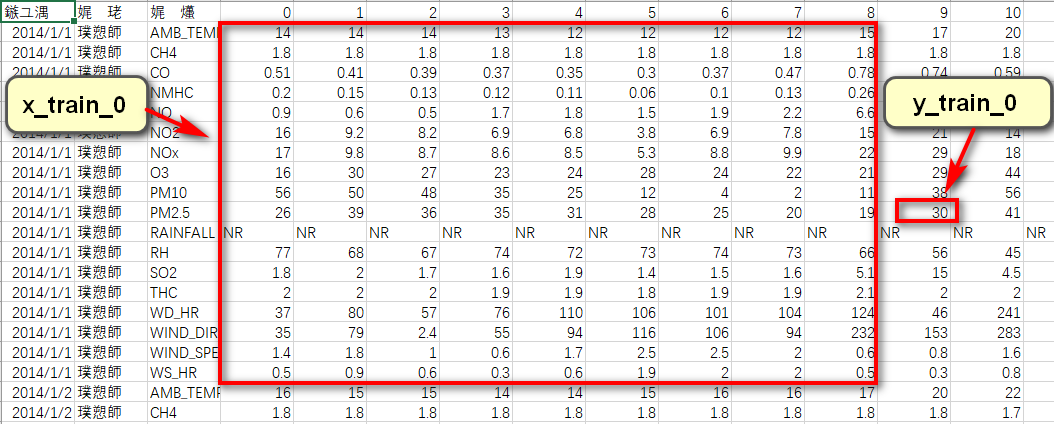
#数据预处理
def dataProcess(df):
x_list, y_list = [], []
df = df.replace(['NR'], [0.0]) # 将所有NR的值全部置为0方便之后处理
array = np.array(df).astype(float) # astype() 转换array中元素数据类型
# train_hung_1_pm2.5.csv文件中去除第一行,所以剩下一共是4320行数据,因为每一天是一共有18行的,
# 所以步长是18,第一 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









