






1. abort 中止目前的事务
abort [work | transaction]
2. alter aggregate 更改聚集函数的定义
alter aggregate 名称 (type) rename to 新的名称
alter aggregate 名称 (type) owner to {新的属主 | current_user | session_user }
3. alter conversion 更改一个字符编码转换的定义
alter conversion 名称 rename to 新的名称
alter conversion 名称 owner to {新的属主 |current_user | session_user}
alter conversion 名称 set schema 新的模式
4. alter database 更改一个数据库 (注:这是更改一个数据库,并不是像mysql中的use database)
alter database 名称 rename to 新的名称
alter database 名称 owner to {新的属主 | current_user | session_user}
alter database 名称 set tablespace 新的表空间
alter database 名称 set 配置参数 { to | =} {值 | default}
alter database 名称 set 配置参数 from current
alter database 名称 reset 配置参数
alter database 名称 reset all
5. alter domain 更改共同值域的定义
alter domain 名称 {set default 表达式 | drop default}
alter domain 名称 {set | drop } not null
alter domain 名称 add 域值 [ not valid]
alter domain 名称 drop constraint [ if exists ] 约束名称 [restrict | cascade]
alter domain 名称 rename constraint 约束名称 to 新的约束名称
alter domain 名称 validate constraint 约束名称
alter domain 名称 owner to { 新的属主 | current_user | session_user}
alter domain 名称 rename to 新的名称
alter domain 名称 set schema 新的模式
6. alter function 更改函数的定义
具体语法查看 、help alter function
7. alter group 更改角色名称或者成员状态
alter group role_specification(可以是current_user,或者是session_user) add user 用户名 [,... ]
alter group role_specification(可以是current_user,或是session_User) drop user 用户名 [,...]
alter group 组名称 rename to 新的名称
8. alter index 更改索引的定义
alter index [if exists] 名称 rename to 新的名称
alter index [if exists] 名称 set tablespace 表空间的名称
alter index 名称 depends on extension 扩展名
alter index [ if exists ] 名称 set (存储参数 = 值 [ ,...])
alter index [ if exists] 名称 reset (存储参数 = 值 [ ,...])
alter index all in tablespace 名称 [ owner by 角色名称 [,...]] set tablespace 新的表空间 [nowait]
9. alter operator 更改运算子的定义
ALTER OPERATOR 名称 ( { 操作符左边操作数的类型 | NONE } , { 操作符右边操作数的类型 | NONE } )
OWNER TO { 新的属主 | CURRENT_USER | SESSION_USER }
10. alter operator class 更改运算子类别的定义
ALTER OPERATOR CLASS 名称 USING 访问索引的方法
RENAME TO 新的名称
查看数据库 \l
查看数据表结构 \dt 表名或者 \d 表名
创建数据库 create database 数据库名
获取时间差 select age(timestamp '2017-01-10',timestamp '2016-01-10');
当前DATE/TIME()
带时区的:current_date,current_time,current_timestamp,current_time(precision),current_timestamp(precision)
不带时区的:localtime,localtimestamp,localtime(precision),localtimestamp(precision)
alter table 更改表中列的data type(修改字段类型):
alter table 表名 alter column 列名 type 数据类型;
这与mysql中的alter table 表名 modify 字段名 数据类型 [属性] [位置];不同
alter table 向表中的列添加NOT NULL约束:
alter table 表名 modify 列名 数据类型 not null;
alter table 添加唯一约束add unique constraint 到表中:
alter table 表名 add constraint 约束名 unique(column1,column2,....);
与mysql中alter table 表名 add unique key(column1,column2,...)不同;
alter table 将“检查约束”添加到表中:
alter table 表名 add constraint 约束名 check(condition);
alter table 添加主键:
alter table 表名 add constraint 约束名 primary key(column1,column2,...);
与mysql中alter table 表名 add primary key(column1,column2,...)不一样;
删除约束:
alter table 表名 drop constraint 约束名 ;(包括主键,唯一解等)
mysql中:drop primary key;drop index 唯一键名;不同
事务:
事务开始:begin transaction(与mysql中start transaction不同),或简单的直接用begin
commit
rollback
pg数据库中的自增长:
pg中有数据类型smallserial,serial,bigserial;这些不是真正的类型,而只有在创建唯一标识符列的标志以方便使用。类似于其他数据库的auto_increment属性。
类型名称serial用于创建整数列,bigserial创建一个bigint类型的列。
create table tablename(column_name serial);
授予权限:
grant privilege [,...] on object [,...] to {public|group groupname |username};
其中privilege可以是select,insert,update,delete,rule,all;object是授予访问权限的对象的名称,可以是表,视图,序列;
撤回权限:
revoke privilege [,...] on object [,...] from {public|group groupname |username};
python连接pg数据库:
import psycopg2
conn = psycopg2.connect(database="",user = "",password = "",host = "",port = 5432)
cur = conn.cursor()
cur.execute("sql 语句;")
rows = cur.fetchall()
for row in rows:
print()...
conn.commit
conn.close()
聚合函数:
聚合得到数组,null计入数组:array_agg(expression) select array_agg(id) from (values(null),(1),(2)) as t(id);
avg(),max(),min(),sum()
bit_and(expression) 所有非空值的位与运算,如果没有则为空
bit_or(expression) 所有非空值的位或,如果没有则为空
bool_and(expression) 所有输入值为true则为true,输入数据类型为bool
bool_or(expression) 至少有一个为true则为true
count(*) 统计所有行,包括null
count(expression) 统计输入行,输入值非空
every(expression) 等价于bool_and
json_agg(expression) json数组的聚合,没有key值
json_object_agg(name,value) json对象name/value对的数组聚合,有key值
string_agg(expression,delimiter) 字符串的连接,通过delimiter连接
xmlagg(expression) xml值的连接
窗口函数:
window子句:
preceding:往前
following:往后
current row :当前行
unbounded :起点,unbounded preceding表示从前面的起点,unbounded following表示到后面的终点
复制别人的例子:
select name,orderdate,cost,
sum(cost) over() as sample1,--所有行相加
sum(cost) over(partition by name) as sample2,--按name分组,组内所有数据相加
sum(cost) over(partition by name order by orderdate) as sample3,--按name分组并按orderdate排序,组内数据累加
sum(cost) over(partition by name order by orderdate rows between unbounded preceding and current row) as sample4,--和sample3一样,由起点到当前行的聚合
sum(cost) over(partition by name order by orderdate rows between 1 preceding and current row) as sample5,--当前行和前面一行做聚合
sum(cost) over(partition by name order by orderdate rows between 1 preceding and 1 following) as sample6,--当前行和前一行及后面一行
sum(cost) over(partition by name order by orderdate rows between current row and unbounded following) as sample7; --当前行及后面所有行

窗口函数中的序列函数:
常用的序列函数有下面几个:
ntile(n),将分组数据按照顺序切分成n片,返回当前切片值
ntile不支持rows between,如果切片不均匀,默认增加第一个切片的分布
例子:
select name,orderdate,cost,
ntile(3) over() as sample1,--全局数据切片
ntile(3) over(partition by name),--按name进行分组,在分组内将数据切分成3份
ntile(3) over(order by cost),--全局按cost升序排列,数据切成3份
ntile(3) over(partition by name order by cost) from order1;--按照name分组,在分组内按照cost升序排列,数据切分成3份

row_number,rank,dense_rank:
row_number:不管是不是相同的,排序按照12345来
rank:有相同的排名相同,下一个排序按人头来
dense_rank:有相同的排名相同,下一个排序按照连续序号来,保证排序不间断
lag和lead函数:
以订单表为例,查看顾客上n次的购买时间:
select name,orderdate,cost,
lag(orderdate,1,'1900-01-01') over(partition by name order by orderdate) as time1,
lag(orderdate,2) over(partition by name order by orderdate) as time2
from order1;
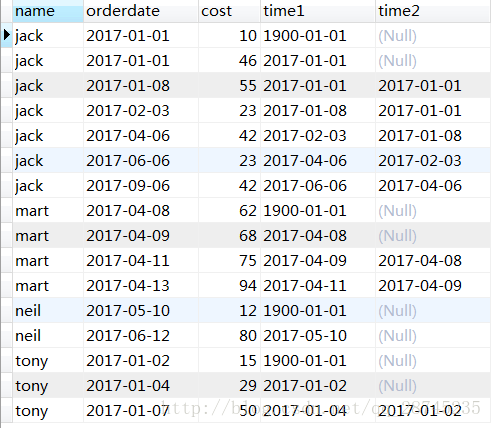
time1取得是按name分组,按orderdate排序,取上一行数据值,
time2取的是按name分组,组内升序,取上面两行的数据的值,注意当log函数为设置时,默认为1行。未设定取不到默认值时,取null值。
lead函数与lag函数方向相反,取向下的数据。
first_value取的是分组内排序后,截止到当前行,第一个值
last_value取的是分组内排序后,截止到当前行,最后一个值
















 2100
2100











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









