







目录
1 串的定义
字符串简称串。串是零个或多个字符串组成的有限序列。
S: 串名;a: 每一个字符;n=0时,串称为空串
。
- 子串:主串种任意多个连续的字符组成的子序列。
- 主串:包含子串的串。
- 空格串:由一个或多个空格组成的串(空格串不是空串)。
2 串的存储结构
串存储结构有:定长顺序存储、块链存储、堆分配存储(文章采用该存储方式)。
2.1 定长顺序存储
定长顺序存储类似于顺序存储结构,用一组连续的存储单元存储字符序列。
串的长度不会超过MAXLEN,超过该长度就会被截断。
#define MAXLEN 255 // 串最大长度
typedef struct {
char ch[MAXLEN]; // 连续存储单元
int length; // 串实际长度
}2.2 块链存储
类似于线性表的链式存储结构。每个结点可以存放一个或多个字符,每个结点称为块。
存储一个字符:
typedef struct StringNode {
char ch; // 每个字符
struct StringNode* next;
} StringNode, *String; 存储多个字符:最后一个结点占不满时可以使用其它符号补上。
typedef struct StringNode {
char ch[4]; // 每个结点存储4个字符
struct StringNode* next;
} StringNode, *String;2.3 堆分配存储
堆分配存储也是一组地址连续的存储单元存放字符序列。但是该存储空间是动态分配的。(文章采用该存储方式)
typedef struct {
char* ch; // 串的首指针
int length; // 串实际的长度
int maxLen; // 串支持最长的长度
} SString, *String;3 串的模式匹配
子串的定位操作称为串的模式匹配,是求子串(模式串)在主串中的位置。位置是子串在主串中第一次出现的位置,如果找不到返回0。
3.1 简单的模式匹配算法
从主串S 与 子串T第一个字符开始比较。相等:s和t指针往右移动,继续比较下一位。不相等:子串T指针又从头开始,主串S指针从下一个字符开始。直到t与子串的长度相等就匹配成功。
简单模式匹配算法的最坏时间复杂度为O(nm),n:主串长度,m:子串长度。
第一趟:;i = 0; j = 0时不匹配;。将j致为0,i = 0 - 0 + 1。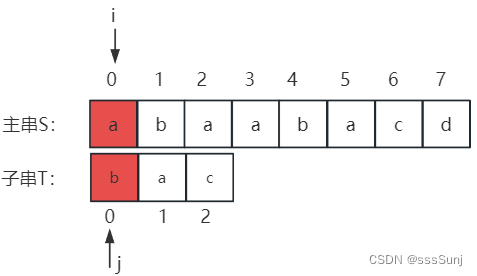
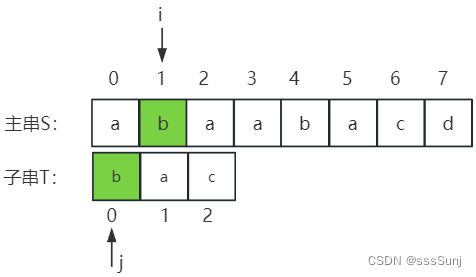
第二趟:相等,i,j继续++。
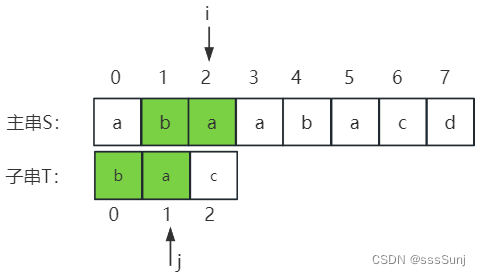
第三趟:相等,i,j继续++。
第四趟:i=3,j=2时不相等,将j致为0,i=3 - 2 + 1。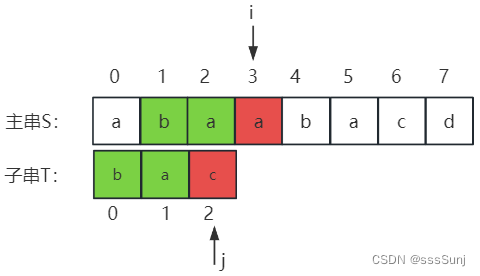
第五、六、七趟:i,j继续++。
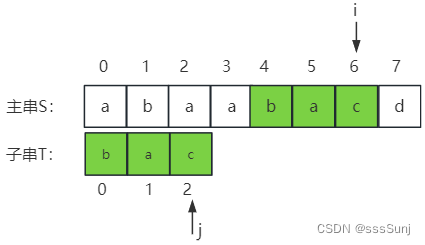
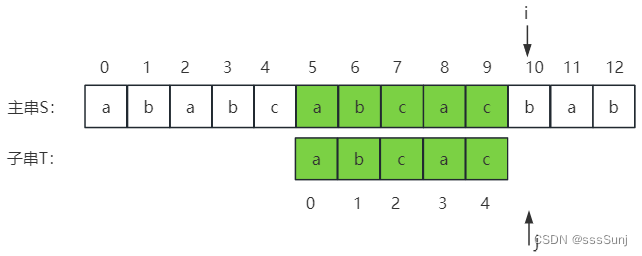
第八趟:当j => T->length后就会退出while循环,判断 j == T->legth满足时就会返回子串在主串中第一次出现的位置:i - j; (7 - 3 = 4)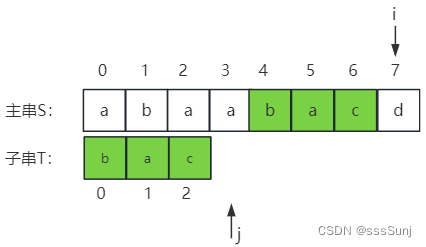
int Index(String S, String T) {
// 两个串初始下标 串 i:主串 j:子串
int i = 0, j = 0;
while (i < S->length && j < T->length) {
if (S->ch[i] == T->ch[j]) {
j++;
i++;
}
else {
// 主串指针往前移动一位
i = i - j + 1;
// 子串指针从头开始
j = 0;
}
}
// 子串指针如果走到和子串长度一致就表示有子串
if (j == T->length) {
return i - j;
}
return 0;
}3.2 KPM算法
在上面的简单匹配算法中,每次匹配失败,主串指针都要后移,频繁的重复比较已经相等的前缀。如果已匹配相等的前缀序列中,有某个后缀正好是模式串的前缀,那么就可以将模式串向后滑动到这些相等字符位置对齐。主串指针无需回溯。最坏时间复杂度为O(m + n), m:主串,n:构建子串的next数组。
如下图,已经匹配的主串:ebeb,已已匹配相等的前缀:ebe,某个后缀:e、be。正好是模式串的前缀:e、eb、ebe。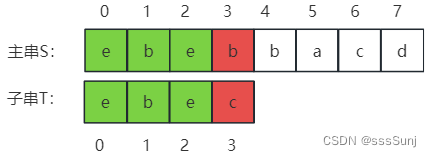
那么就将模式串滑动到相等字符位置对齐。继续从主串第3个位子和子串第1个位子继续比较。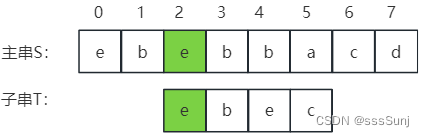
3.2.1 next数组和的前、后缀和部分匹配值
- 前缀
除最后一个字符以外,字符串的所有头部子串。 - 后缀
除第一个字符串外,字符串的所有尾部子串。 - 部分匹配值
字符串的前缀和后缀的最长相等前后缀的长度。
以ababa为例:
- 'a'的前缀和后缀都为空集,最长相等前后缀长度为0。
- 'ab'的前缀为
,后缀为
。
所以相等前后缀为0。
- 'aba'的前缀为
,后缀为
。
所以最长相等前后缀为1。
- 'abab'的前缀为
后缀为
=
所以最长相等前后缀为2。
- 'ababa'的前缀为
=
所以最长相等前后缀为3。
故字符串'ababa'的部分匹配值为00123,将部分匹配值写成数组形式,得到部分匹配值表:
| 编号 | 0 | 1 | 2 | 3 | 4 |
| 主串(S) | a | b | c | a | c |
| PM(Partial match,部分匹配值) | 0 | 0 | 0 | 1 | 0 |
为方便操作,将PM表右移右移一位,低位补-1,高位舍去:
| 编号 | 0 | 1 | 2 | 3 | 4 |
| 主串(S) | a | b | c | a | c |
| next | -1 | 0 | 0 | 0 | 1 |
// 构建部分匹配值表 T:模式串
int* GetNext(String T) {
int* next = (int*)malloc((T->length) * sizeof(int));
if (next == NULL) {
return NULL;
}
// 第一个不匹配时指针到模式串前面
next[0] = -1;
int i = 0;
int j = -1;
while (i < T->length) {
// j在模式串前一个位置或者模式串和部分模式串的字符相等时候
if (j == -1 || T->ch[i] == T->ch[j]) {
i++;
j++;
next[i] = j;
}
// 如果不相等, 在部分next数组中,找到部分模式串下一个位置
// 把这个过程也看成一个KPM匹配的过程, i就是指向主串, j也就是指向模式串
else {
j = next[j];
}
}
return next;
}3.2.2 next运用
主串:ababcabcacbab
子串:abcac
使用上面构建好next数组
| 编号 | 0 | 1 | 2 | 3 | 4 |
| 主串(S) | a | b | c | a | c |
| next | -1 | 0 | 0 | 0 | 1 |
1、i=2,j=2时,不匹配。j = next[j],j从0位置开始。
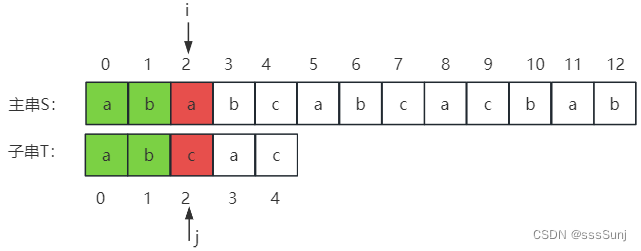
2、通过第1步调整j位置后:
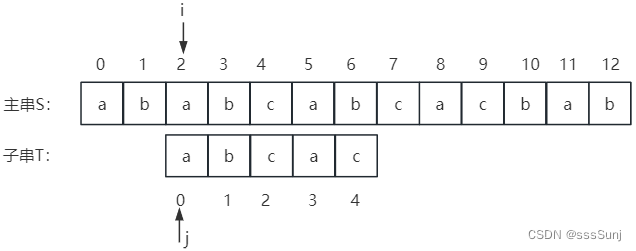
3、i=6,j=4时,不匹配。j = next[j],j从1开始。
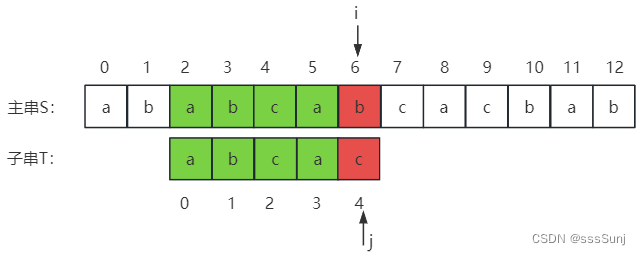
4、通过第3步,调整j位置后:
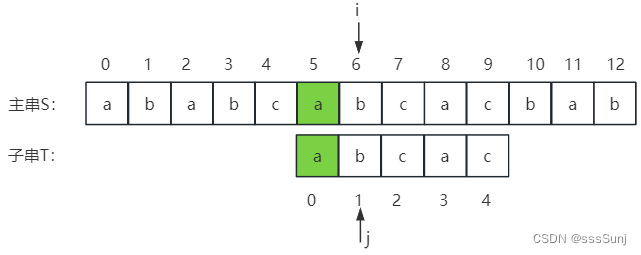
5、j == T.length, 匹配完成
int Index_KPM(String S, String T) {
int* next = GetNextVal(T);
int i = 0; // 主串指针
int j = 0; // 模式串指针
while (i < S->length && j < T->length) {
if (j == -1 || S->ch[i] == T->ch[j]) {
i++;
j++;
}
else {
j = next[j];
}
}
if (j == T->length) {
return i - j;
}
else {
return 0;
}
}3.2.3 next数组优化
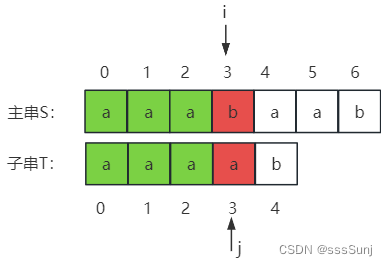
主串:aaabaab
子串:aaaab
next数组:
| 下标 | 0 | 1 | 2 | 3 | 4 |
| 主串(S) | a | a | a | a | b |
| next | -1 | 0 | 1 | 2 | 3 |
i=3,j=3是,不匹配。j = next[j],j移动到2位置,发现也是a,因为此时子串a已经不能与主串匹配,那么移动到2号位置也是a,就会进行一次无效的匹配。
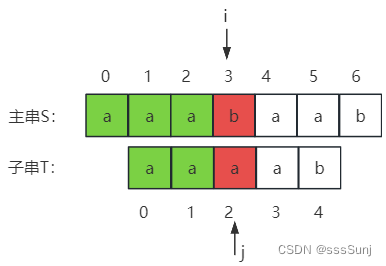
在构建next数组的时候,如果发现要移动过去的位置,字符与当前不匹配的字符相等,将next[j] = next[next[j]]。
int* GetNextVal(String T) {
int* nextval = (int*)malloc((T->length) * sizeof(int));
if (nextval == NULL) {
return NULL;
}
nextval[0] = -1;
int i = 0;
int j = -1;
while (i < T->length) {
if (j == -1 || T->ch[i] == T->ch[j]) {
i++; j++;
// 如果不匹配的字符与要移动位置的字符一样,直接记录要移动位置的下标
if (T->ch[i] == T->ch[j]) {
nextval[i] = nextval[j];
}
else {
nextval[i] = j;
}
}
else {
j = nextval[j];
}
}
return nextval;
}代码
#include <iostream>
#include <algorithm>
using namespace std;
typedef struct {
char* ch; // 串的首指针
int length; // 串实际的长度
int maxLen; // 串支持最长的长度
} SString, *String;
// 初始串长度为5
String createSrt() {
String string = (String)malloc(sizeof(SString));
if (string != NULL) {
string->ch = (char*)malloc(5 * sizeof(char));
string->length = 0; // 这个是从0开始
string->maxLen = 5; // 这个是从1~5
}
return string;
}
// 把串c赋值到string
void StrAssign(String string, char* c) {
while (*c != '\0') {
// 容量够, 正常插入
if (string->length < string->maxLen) {
string->ch[string->length] = *c;
}
// 扩容
else {
// 扩大5个字符
int newCapacity = string->maxLen + 5;
// 重新设置串最大支持长度
string->maxLen = newCapacity;
char* newStr = (char*)realloc(string->ch, newCapacity * sizeof(char));
if (newStr != NULL) {
// 重新指向新的内存(realloc会free原来内容)
string->ch = newStr;
// 扩容后继续插入
string->ch[string->length] = *c;
printf("扩容后的容量 %d\n", newCapacity);
}
else {
printf("扩容失败\n");
}
}
string->length++;
c++;
}
}
// 是否为判空
int StrEmpty(String string) {
return !string->length; // 0:false, >0:取反后会变成1
}
// 串长(元素的个数)
int StrLength(String string) {
return string->length;
}
// 清空串
void ClearString(String S) {
S->length = 0; // 逻辑上清空
}
// 销毁串
void DestoryString(String S) {
if (S != NULL) {
if (S->ch != NULL) {
free(S->ch);
S->ch = NULL;
}
free(S);
S = NULL;
}
}
// 比较 S>T,则返回>0; S=T,则返回=0; S<T,则返回<0
int StrCompare(String S, String T) {
for (int i = 0; i < S->length && i < T->length; i++) {
if (S->ch[i] != T->ch[i]) {
return S->ch[i] - T->ch[i];
}
}
return S->length - T->length;
}
// 求子串 Sub返回串S的第pos个字符起长度为len的子串
void SubString(String Sub, String S, int pos, int len) {
if (len - pos < 0 || pos > S->length || len > S->length) {
return;
}
for (int i = pos; i <= len; i++) {
Sub->ch[i - pos] = S->ch[i - 1];
}
Sub->length = len - pos + 1;
}
// 串联接 T返回S1和S2联接而成的新串
void Concat(String T, String S1, String S2) {
if (S1->length + S2->length > T->maxLen) {
int newLen = S1->length + S2->length;
char* newChar = (char*)realloc(T->ch, newLen * sizeof(char));
if (newChar != NULL) {
T->ch = newChar;
T->maxLen = newLen;
cout << "扩容:" << T->maxLen << endl;
}
else {
return;
}
}
// 写入第一个串
for (int i = 0; i < S1->length; i++) {
T->ch[i] = S1->ch[i];
}
// 写入第二个串
for (int i = S1->length; i < S1->length + S2->length; i++) {
T->ch[i] = S2->ch[i - S1->length];
}
// 更新串长度
T->length = S1->length + S2->length;
}
// 定位 若主串S中存在与串T值相同的子串, 则返回它在主串S中第一次出现的位置; 否则返回0
int Index(String S, String T) {
// 两个串初始下标 串 i:主串 j:子串
int i = 0, j = 0;
while (i < S->length && j < T->length) {
if (S->ch[i] == T->ch[j]) {
j++;
i++;
}
else {
// 主串指针往前移动一位
i = i - j + 1;
// 子串指针从头开始
j = 0;
}
}
// 子串指针如果走到和子串长度一致就表示有子串
if (j == T->length) {
return i - j;
}
return 0;
}
// 构建部分匹配值表 T:模式串
int* GetNext(String T) {
int* next = (int*)malloc((T->length) * sizeof(int));
if (next == NULL) {
return NULL;
}
// 第一个不匹配时指针到模式串前面
next[0] = -1;
int i = 0;
int j = -1;
while (i < T->length) {
// j在模式串前一个位置或者模式串和部分模式串的字符相等时候
if (j == -1 || T->ch[i] == T->ch[j]) {
i++;
j++;
next[i] = j;
}
// 如果不相等, 在部分next数组中,找到部分模式串下一个位置
// 把这个过程也看成一个KPM匹配的过程, i就是指向主串, j也就是指向模式串
else {
j = next[j];
}
}
return next;
}
// 优化部分匹配值表
int* GetNextVal(String T) {
int* nextval = (int*)malloc((T->length) * sizeof(int));
if (nextval == NULL) {
return NULL;
}
nextval[0] = -1;
int i = 0;
int j = -1;
while (i < T->length) {
if (j == -1 || T->ch[i] == T->ch[j]) {
i++; j++;
if (T->ch[i] == T->ch[j]) {
nextval[i] = nextval[j];
}
else {
nextval[i] = j;
}
}
else {
j = nextval[j];
}
}
return nextval;
}
// S:主串 T:模式串
int Index_KPM(String S, String T) {
// 拿到模式串部分匹配值表
//int* next = GetNext(T);
int* next = GetNextVal(T);
int i = 0; // 主串指针
int j = 0; // 模式串指针
while (i < S->length && j < T->length) {
if (j == -1 || S->ch[i] == T->ch[j]) {
i++;
j++;
}
else {
j = next[j];
}
}
if (j == T->length) {
return i - j;
}
else {
return 0;
}
}
int main() {
// 比较串
String S = createSrt();
char s1[] = "abaabcabad";
StrAssign(S, s1);
String T = createSrt();
char t1[] = "d";
StrAssign(T, t1);
cout << "简单=" << Index(S, T) << endl;
cout << "KPM=" << Index_KPM(S, T);
return 0;
}















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









