






该系列主要是听李宏毅老师的《深度强化学习》过程中记下的一些听课心得,除了李宏毅老师的强化学习课程之外,为保证内容的完整性,我还参考了一些其他的课程,包括周博磊老师的《强化学习纲要》、李科浇老师的《百度强化学习》以及多个强化学习的经典资料作为补充。
笔记【4】到笔记【11】为李宏毅《深度强化学习》的部分;
笔记 【1】和笔记 【2】根据《强化学习纲要》整理而来;
笔记 【3】 和笔记 【12】根据《百度强化学习》 整理而来。
一、相关术语
(1)on-policy:要学习的agent跟与环境互动的agent是同一个agent时的策略;
(2) off-policy:要学习的agent跟与环境互动的agent不是同一个agent时的策略。
二、重要性采样
根据我们第四章中的策略梯度方法,可以通过多次采样的方式进行强化学习。但是每学习一次,策略就发生了变化,根据梯度上升的公式:
![]()
所以每学习过一个样本,参数θ就会发生变化,变成θ’。因此原来的数据样本就不能再用,需要重新采集样本,这样很麻烦而且效率低下。
由此引出了重要性采样:

也就是说,x服从p分布,那么f(x)的期望等于f(x)p(x)/q(x)的期望,也即:

其中p(x)/q(x)称为重要性权重。
根据重要性采样,也就是说,可以利用其他分布采样得来的数据,来求另一种分布的期望。当然,这两种分布相差不能太远,越相似越好,因为除了考虑期望,两个分布的方差也要考虑:如果两个分布的方差差别太大,那么在采样的情况下由于数据不均匀不全面,计算得到的期望可能会有很大差距。这种情况可以用下图来形象说明:

三、PPO
PPO就是利用了重要性采样的方法来做强化学习,从而避免了策略梯度采样时间长的问题。那么,PPO是如何利用重要性采样的呢?前面说了,重要性采样可以利用其他分布的采样数据来计算另一种分布的期望,前提是两种分布差别不能太大,因此,PPO的主要工作就是避免两种分布差别较大,让两种分布越相似越好。
为避免两种分布差别较大,可以在原始目标函数的基础上增加一个约束,叫做KL散度,用于衡量两种分布的差异。KL散度是行为距离,也就是两个动作的相似度,本质上是一个函数。它类似于参数距离,但是参数距离是指两个参数之间的差异,而行为距离是指两个动作之间的差异。
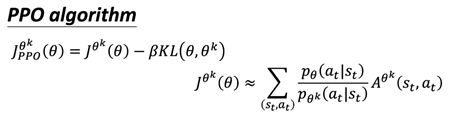
PPO 算法有两个主要的变种:PPO-Penalty 和 PPO-Clip。
(1)PPO-Penalty
![]()

(2)PPO-Clip

如果觉得散度计算困难,那么可以采用这种方法,这里没有散度。虽然这个式子看上去麻烦,但是实际上非常简单,它就是采用截断的方式,来防止分布差异过大。
- Min 这个操作符(operator)做的事情是第一项跟第二项里面选比较小的那个。
- 第二项前面有个 clip 函数,clip 函数的意思是说,
- 在括号里面有三项,如果第一项小于第二项的话,那就输出1−ε 。
- 第一项如果大于第三项的话,那就输出 1+ε。
- ε 是一个超参数,你要 tune 的,你可以设成 0.1 或 设 0.2 。
我们先来看看![]() 这一项是什么:
这一项是什么:

当第一项小于1-ε,clip这一项就取1-ε,当大于1+ε,就取1+ε,中间取自身值。

由此可以得到优势函数A大于0以及小于0时![]() 的取值情况,其中红线是
的取值情况,其中红线是![]() 最终取值。A大于0时J要取最小值,应该取下面小的部分;A小于0时J要取最小值,应该取上面大的部分。
最终取值。A大于0时J要取最小值,应该取下面小的部分;A小于0时J要取最小值,应该取上面大的部分。
这样的话,就可以保证两种分布的差别不会太大,为什么呢?
当A大于0,说明该状态-动作好,需要增加这个状态-动作出现的概率,也就是让![]() 的取值增大,但是
的取值增大,但是![]() 与
与![]() 的比值又不能太大,因此设置
的比值又不能太大,因此设置![]() 要小于1+ε,否则差别太大就会出错。因此训练到
要小于1+ε,否则差别太大就会出错。因此训练到![]() 大于1+ε时,就停止训练。
大于1+ε时,就停止训练。
如果A小于0,那么说明该状态-动作不好,需要减少概率,也就是![]() 应该变小,但是无论
应该变小,但是无论![]() 变得多小,
变得多小,![]() 也不能小于1-ε,这样两者的比值始终在1±ε之间,两者的差距就不会太大。
也不能小于1-ε,这样两者的比值始终在1±ε之间,两者的差距就不会太大。
此外,值得一提的是,由于PPO算法的θk采用的是θ,所以该算法是on-policy,也就是说,该算法中与环境交互的policy,跟要学习的policy是同一个policy,只不过有两个agent,一个只负责示范,一个只负责学习。














 6003
6003











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









