






 本文深入探讨Postgres数据库中的锁机制,包括行级锁、会话锁、自旋锁、轻量级锁和重量级锁的实现原理。分析了锁的数据结构、管理机制、fast-path机制、死锁检测算法及锁获取流程。
本文深入探讨Postgres数据库中的锁机制,包括行级锁、会话锁、自旋锁、轻量级锁和重量级锁的实现原理。分析了锁的数据结构、管理机制、fast-path机制、死锁检测算法及锁获取流程。
这是我数据库系统机构课的结课作业,研究Postgres的行级锁/表级锁。如有不准确,望指正。
Postgres行级锁/会话锁分析报告
Postgress使用4种进程间的锁,分别是自旋锁、轻量级锁、重量级锁、谓词锁。.自旋锁(Spinlock)专为短期锁设计的,根据编译环境由硬件实现。轻量级锁(Lightweight Lock, LWlock)一般用作共享内存中数据结构的访问,支持独占和共享锁模式,没有死锁检测。常规锁(a/k/a 重量级锁),支持多种有表驱动语义的锁模式并且在事务端具有完全的死锁检测和自动释放功能。我们这次分析的行级锁/会话锁属于这种锁。SIReadLock(谓词锁),用于Serializable Snapshot Isolation(可序列化快照隔离,SSI)。
我们分析的行级锁/会话锁都属于常规锁,所以这里只对常规锁进行分析,常规锁管理中会用到自旋锁(以下使用Spinlock)和轻量级锁(以下使用LWlock),所以可能也会简单的介绍一下用处。
1.常规锁的数据结构
每一个可被加锁的对象都可以拥有锁,这个锁的信息存储在数据结构LOCK中,LOCK定义如下:
typedef struct LOCK
{
/* hash key */
LOCKTAG tag; /* 用作共享内存LOCK哈希表中的项进行哈希运算的key */
/* data */
LOCKMASK grantMask; /* 给定可加锁对象上已加锁的锁种类的位掩码 */
LOCKMASK waitMask; /* 给定可加锁对象上等待加锁的锁种类的位掩码 */
SHM_QUEUE procLocks; /* 所有关联了这个LOCK对象的PROCLOCK对象 */
/* 的共享内存队列 */
PROC_QUEUE waitProcs; /* PGPROC对象的共享内存队列,这些PGPROC */
/* 对象对应的后端正在等待其他后端释放这个锁 */
int requested[MAX_LOCKMODES]; /* Keeps a count of how many locks of */
/* each type have been attempted */
int nRequested; /* Keeps a count of how many times this lock */
/* has been attempted to be acquired */
int granted[MAX_LOCKMODES]; /* Keeps count of how many locks of each */
/* type are currently held. */
int nGranted; /* Keeps count of how many times this lock */
/* has been successfully acquired. */
} LOCK;
注:上面部分注释为英文,因为原文更好表达意思,或者字段部分不是特别重要,以下同理。
LOCK字段中关键的LOCKTAG唯一标识了一个LOCK,结构定义如下:
typedef struct LOCKTAG
{
uint32 locktag_field1; /* a 32-bit ID field */
uint32 locktag_field2; /* a 32-bit ID field */
uint32 locktag_field3; /* a 32-bit ID field */
uint16 locktag_field4; /* a 16-bit ID field */
uint8 locktag_type; /* see enum LockTagType */
uint8 locktag_lockmethodid; /* lockmethod indicator */
} LOCKTAG;
/* 把LOCKTAG定义为一个结构体,防止编译器在结构体内有为了对齐的随机填充,导致求哈希值错误 */
注:lock.h中定义了许多宏,对每种locktag_type定义了不同的宏,从这些宏中可以了解LOCKTAG前4个字段存储数值的含义,这里我们只需要了解,一般情况下field1存储的是数据库oid(dboid),field2存储的是关系oid(reloid)。
和锁有直接关系的数据结构,除了上面的LOCK,还有一个LockMethod:
/*
* 这个结构定义一种锁的语义
* 用户可以自定义一个这个结构来做到自定义锁
*/
typedef struct LockMethodData
{
int numLockModes; /* 锁有的模式数量 */
const LOCKMASK *conflictTab; /* 冲突表,mode i和mode j冲突则tab[i]的第j位 = 1 */
const char *const *lockModeNames; /* ID strings for debug printouts. */
const bool *trace_flag;
} LockMethodData;
typedef const LockMethodData *LockMethod;
typedef uint16 LOCKMETHODID; /* id for LockMethod,由于LOCKTAG对应字段为8位,
所以最多指定256个 */
/* 两个已经定义好的LockMethod的id */
#define DEFAULT_LOCKMETHOD 1
#define USER_LOCKMETHOD 2
/* 定义好的LockMethod在lock.c中 */
此数据结构定义与"锁方法"关联的锁语义。语义指定每个锁模式(也叫所类型)的含义,比如冲突表等。Postgres定义了两个LockMethod(DEFAULT_LOCKMETHOD和USER_LOCKMETHOD),所有这些锁方法存储在静态全局变量LockMethods(lock.c)中,并可用全局函数GetLocksMethodTable获取。用户也可以自己定义锁方法,只要存储到这个LockMethods数组中。关于Postgres自带的这两个锁方法,将在后面讲。
锁的数据结构就讲到这里,接下来讲持有锁的对象和锁有关的数据结构。
因为可能有多个后端进程在同一个共享可锁对象上拥有或者等待锁,所以需要为每个拥有或者等待这些锁的后端进程定义一个结构来存储这些信息,这个结构是PROCLOCK,定义如下:
typedef struct PROCLOCK
{
/* tag */
PROCLOCKTAG tag; /* 用作共享内存PROCLOCK哈希表中的项进行哈希运算的key */
/* data */
PGPROC *groupLeader; /* 关联进程在共享内存中所在的PGPROC组的leader */
LOCKMASK holdMask; /* 关联进程当前在关联锁上获得的所有锁类型的位掩码 */
LOCKMASK releaseMask; /* 在调用LockReleaseAll时释放了的所有锁类型的位掩码 */
SHM_QUEUE lockLink; /* 关联了同一个锁(tag.myLock)的PROCLOCK共享内存中的队列 */
SHM_QUEUE procLink; /* 关联了同一个后端进程(tag.myProc)的PROCLOCK共享内存中的队列 */
} PROCLOCK;
同LOCK,PROCLOCK中也有个tag来唯一标识PROCLOCK:
/* PROCLOCKTAG定义一个对象,关联了一个锁和拥有或等待这个锁的后端进程 */
typedef struct PROCLOCKTAG
{
/* NB: we assume this struct contains no padding! */
LOCK *myLock; /* 指针指向这个PROCLOCK关联的(共享的)可加锁对象 */
PGPROC *myProc; /* 指针指向这个PROCLOCK关联的后端进程 */
} PROCLOCKTAG; /* 同LOCKTAG,定义为一个结构体 */
通过PROCLOCK结构就将锁和进程双向关联起来了。
接下来的数据结构涉及Postgres锁管理的两个非常重要的机制,fast-path机制和分区机制,理解了fast-path机制会更加理解定义这些数据结构的目的。fast-path机制在后面章节有讲。
/*
* 共享的锁结构只允许为每个可加锁对象/锁模式(类型)/后端授予一个锁,但是在
* 后端内部同一个锁可以被请求释放多次。
*
* 每一个后端维护了一个本地哈希表,其中包括了当前这个后端被分配的锁的信息。
* 这使得后端可以自主的对拥有的锁进行分配或者回收,这个本地哈希表中的数据
* 统计了获取锁的次数,这允许对同一个锁执行多个请求,而无需访问共享内存。
*
* 当是通过一般途径获取的锁,lock和proclock字段指向共享内存中的关联对象,
* 但是如果我们通过fast-path机制获得了锁,则这两个字段为NULL,共享内存中
* 可能没有这个对象。
*/
typedef struct LOCALLOCK
{
/* tag */
LOCALLOCKTAG tag; /* 用来标识LOCALLOCK的唯一标识符 */
/* data */
uint32 hashcode; /* 关联LOCK的LOCKTAG的哈希值 */
LOCK *lock; /* 关联的LOCK */
PROCLOCK *proclock; /* 关联的PROCLOCK */
int64 nLocks; /* 获取锁的总次数 */
int numLockOwners; /* lockOwners的有效数据大小,*/
/* 含义为这个LOCK关联的ResourceOwner数 */
int maxLockOwners; /* lockOwners数组分配的长度 */
LOCALLOCKOWNER *lockOwners; /* 一个动态大小数组,用来存储这个LOCK关联的ResourceOwner */
bool holdsStrongLockCount; /* bumped FastPathStrongRelationLocks */
bool lockCleared; /* we read all sinval msgs for lock */
} LOCALLOCK;
typedef struct LOCALLOCKTAG
{
LOCKTAG lock; /* identifies the lockable object */
LOCKMODE mode; /* lock mode for this table entry */
} LOCALLOCKTAG;
typedef struct LOCALLOCKOWNER
{
/*
* Note: if owner is NULL then the lock is held on behalf of the session;
* otherwise it is held on behalf of my current transaction.
*
* Must use a forward struct reference to avoid circularity.
*/
struct ResourceOwnerData *owner;
int64 nLocks; /* # of times held by this owner */
} LOCALLOCKOWNER;
我们关注点主要在lock和proclock这两个字段上,后端获取到某个关系的锁后,就可以自由地处理这个锁了(这里的自由指的是不受主锁管理器的约束),即这个后端也有自己的锁管理,而实现这个”锁管理”的数据结构就是LOCALLOCK,它记住了后端已得到的锁,一对一记住。而实现同一个锁多次分配就用到了numLockOwners,lockOwners字段。至于holdsStrongLockCount字段,它是用在fast-path机制中的,详细见后面。
下面这个数据结构用于fast-path。
#define FAST_PATH_STRONG_LOCK_HASH_BITS 10
#define FAST_PATH_STRONG_LOCK_HASH_PARTITIONS \ /* 1024 */
(1 << FAST_PATH_STRONG_LOCK_HASH_BITS)
#define FastPathStrongLockHashPartition(hashcode) \
((hashcode) % FAST_PATH_STRONG_LOCK_HASH_PARTITIONS)
typedef struct
{
slock_t mutex; /* 用于自旋锁 */
uint32 count[FAST_PATH_STRONG_LOCK_HASH_PARTITIONS];
} FastPathStrongRelationLockData;
/* 保存了每个分区中strong锁授予的数量 */
static volatile FastPathStrongRelationLockData *FastPathStrongRelationLocks;
还有一些全局变量:
static HTAB *LockMethodLockHash;
static HTAB *LockMethodProcLockHash;
static HTAB *LockMethodLocalHash;
分区机制和fast-path机制紧密相关,即将就讲到它。
然后是需要提一下的进程的数据结构,里面有些字段和锁有关:
/*
* 每一个后端有一个PGPROC在共享内存中,存储一个(工作)进程的信息
* 下面只分析和锁有关的字段
*/
struct PGPROC
{
...
/* Info about LWLock the process is currently waiting for, if any. */
bool lwWaiting; /* true if waiting for an LW lock */
uint8 lwWaitMode; /* lwlock mode being waited for */
proclist_node lwWaitLink; /* position in LW lock wait list */
...
/* Info about lock the process is currently waiting for, if any. */
/* waitLock and waitProcLock are NULL if not currently waiting. */
LOCK *waitLock; /* Lock object we're sleeping on ... */
PROCLOCK *waitProcLock; /* Per-holder info for awaited lock */
LOCKMODE waitLockMode; /* type of lock we're waiting for */
LOCKMASK heldLocks; /* bitmask for lock types already held on this
* lock object by this backend */
...
/*
* All PROCLOCK objects for locks held or awaited by this backend are
* linked into one of these lists, according to the partition number of
* their lock.
*/
SHM_QUEUE myProcLocks[NUM_LOCK_PARTITIONS];
...
/* 每个后端都有的LWLock。保护下列字段数据 */
LWLock backendLock;
/* 锁管理器数据,记录这个后端拥有的fast-path锁 */
uint64 fpLockBits; /* 每个fast-path块拥有的锁类型合在一起的位掩码 */
Oid fpRelId[FP_LOCK_SLOTS_PER_BACKEND]; /* 每个块对应的relation oid */
bool fpVXIDLock; /* ignore */
LocalTransactionId fpLocalTransactionId; /* ignore */
/* 为支持锁组
* Support for lock groups. Use LockHashPartitionLockByProc on the group
* leader to get the LWLock protecting these fields.
*/
PGPROC *lockGroupLeader; /* lock group leader, if I'm a member */
dlist_head lockGroupMembers; /* list of members, if I'm a leader */
dlist_node lockGroupLink; /* my member link, if I'm a member */
};
最后需要提下的这个数据结构是用作行级锁中来标识被加锁的元组位置的。
typedef struct ItemPointerData
{
BlockIdData ip_blkid; /* 磁盘块 */
OffsetNumber ip_posid; /* 偏移 */
}
/* If compiler understands packed and aligned pragmas, use those */
#if defined(pg_attribute_packed) && defined(pg_attribute_aligned)
pg_attribute_packed()
pg_attribute_aligned(2)
#endif
ItemPointerData;
typedef ItemPointerData *ItemPointer;
现在所有和锁有关的重要的数据结构就介绍完了,接下来讲Postgres重要的锁机制。
2.锁管理各种机制(翻译自README)
锁管理器的内部加锁(分区加锁):
在PostgreSQL 8.2之前,锁管理器使用的所有共享内存的数据都分别受到一个LWLock的保护,涉及这些数据的操作都必须独占(LW_EXCLUSIVE)的获取到对应的LWLock。所以,这成为了竞争的瓶颈,为了减少竞争,锁管理器的数据结构被分割成多个"分区",每个分区由一个LWLock保护。大多数操作只需要锁定它所在的分区就行了,如下:
每一个LOCK根据其LOCKTAG值的散列值分配到不同的分区。分区的LWLock被用作保护该分区的所有LOCK对象,及其子进程。
保存LOCK和PROCLOCK的共享内存哈希表使用不同的哈希链(hash chain)被组织成不同的分区,因此使用不同分区的对象时不会有冲突。LOCK表(的哈希链)由dynahash.c的partitioned table机制直接支持,我们只需要确保分区数取自LOCKTAG的dynahash哈希值的低位。为了让分区能更有效(我们期望LOCK和关联它的PROCLOCK在同一个分区中),我们还需确保PROCLOCK的哈希值的低位和它关联的LOCK相同,为了达到这里目的,PROCLOCK表使用了一个特殊的哈希函数(proclock_hash)。
以前,每一个PGPROC都有一个属于它的PROCLOCK列表,现在被分成了每个分区列表,这样对特定的PROCLOCK访问就可以由相关分区的LWLock保护。(此规则允许一个后端的操作访问另一个后端的PROCLOCK,这在以前不是必须的,但是现在与fast-path锁相关成了必须的了)。
PGPROC的其他锁相关的字段只有当PGPROC等待锁时才让"人"(代码)感兴趣,因此可以认为它们也受到等待的锁的分区LWLock的保护。
Fast Path机制:
目的为了减少获取和释放某些类型的锁的开销,这些类型的锁获取和释放非常频繁,但很少发生冲突,包括两类锁:(1)弱关系锁(Week relation locks),包括SELECT, INSERT, UPDATE, DELETE。(2)VXID锁(Virtual transaction ID)
我们使用一个含有1024个整数计数器的数组(FastPathStrongRelationLockData中的count数组),对应了1024个锁空间的分区。每一个计数器记录对应分区的非共享关系上strong锁(ShareLock, ShareRowExclusiveLock,ExclusiveLock, AccessExclusiveLock)的个数。当计数器非0时,不会使用fast-path机制在对应分区获取新的关系锁。一个strong锁的操作会增加计数器的值(同时会设置对应LOCALLOCK的holdsStrongLockCount字段为true),然后扫描每个后端的fast-path数组以查找匹配的使用了fast-path的锁,找到的锁都必须在尝试获取strong锁之前传输到主锁表,以确保正确的锁冲突和死锁检测。
死锁检测不需要检查各个后端的fast-path数据结构,因为可能造成死锁的锁都传输到了共享内存中的主哈希表。
元组锁(行级锁通过这个实现):
对元组加锁不像对表加锁或者对其他数据库对象加锁那样简单,这里存在一个问题:事务可能同时向大量的元组加锁,所以不太可能把这些锁全部存在共享内存中。为了解决这个问题,我们使用了一个两级锁机制。第一级通过在元组的开始(头部header)存储锁的信息来实现:一个元组被标记为上锁的,通过设置它的XMAX值为当前事务的XID,然后设置infomask(这个额外信息应该属于在元组存储在磁盘的一个额外信息)中的位来将此情况与删除元组的更正常的情况区分开来。当多个事务同时锁定一个元组时,MultiXact被使用。这种机制可以同时容纳任意数量的元组被锁定。
当需要等一个元组级锁被释放时,基本延迟由元组的XMAX对应的XactLockTableWait或MultiXactIdWait提供。然而,这种机制会同时释放所有的等待者,所以等待者得到元组的时候会有一个竞争条件,可能会导致一些等待者无限期的饥饿。共享锁产生的各种可能性使问题变得更糟——源源不断的共享锁请求很容易永远阻塞一个独占锁请求。为了提供关于谁先获得元组锁的更可靠语义,我们使用标准锁管理器,它实现了上面提到的第二个级别。等待一个元组锁的协议事实上为:
LockTuple()
XactLockTableWait()
mark tuple as locked by me
UnlockTuple()
当有多个等待者时,LockTuple()提供了谁获取下一个元组锁的仲裁。但是,在任何时候,每个后端最多会持有或等待一个元组锁,因此我们不会冒锁表溢出的风险。请注意,如果已经有任何冲突存在,新的共享锁请求也需要执行LockTuple,以确保它们不会使正在等待独占锁的请求饥饿。但是,如果一个元组没有任何已有的冲突,我们就不会产生额外的开销。
对于那些已经在元组上持有一些锁并试图在元组上获得一个更强的锁的锁请求者,我们对上述规则做了一个例外。在这种情况下,即使存在冲突,我们也会跳过LockTuple()调用,前提是目标元组同时正在被多个会话锁定、更新或删除。如果不跳过这个lock,则可能会出现死锁,例如下面这种情景,一个会话首先在元组头部记录一个较弱的锁,然后等待LockTuple()的调用来升级到更强的锁级别,同时有另一个已经完成LockTuple()的会话正在等待第一个会话事务释放这个元组头部的锁。
我们提供了四个不同级别的元组锁强度:SELECT FOR UPDATE获得一个防止对元组进行任何修改的独占锁。DELETE或者UPDATE操作如果修改了元组的任何键字段,则会隐式地获取这个锁。SELECT FOR NO KEY UPDATE同样获得一个排他锁,但只会防止元组的删除和修改改变元组的键。这是由保持所有元组的键不变的UPDATE操作隐式获取的锁。SELECT FOR SHARE获得一个防止任何类型的元组修改的共享锁。最后,SELECT FOR KEY SHARE获得一个共享锁,该锁只防止元组删除和键字段修改。
当一个元组只有一个锁请求时,我们可以将锁信息存储在元组本身中。我们通过将锁请求者的Xid存储在XMAX中,并设置指定锁强度的infomask位来实现这一点。这里有一个例外:由于infomask空间有限,我们没有为SELECT FOR SHARE提供单独的位,因此在这种情况下,我们必须在MultiXact中使用扩展信息。(其他的情况,SELECT FOR UPDATE和SELECT FOR KEY SHARE,由于是标准强制的锁定机制,或者被RI代码大量使用,可能更常用,因此我们希望为它们提供快速路径。)
MultiXacts:
元组头部为存储有关元组锁和更新的信息提供了非常有限的空间:只能容乃一个Xid和一个很小的infomask。每当我们需要存储多个锁时,我们就用一个新的MultiXactId替换第一个锁的Xid。每个MultiXact都提供扩展的锁数据;它包含一个Xid数组和每个Xid的一些标志位。这些标志当前用于存储每个成员事务的元组锁强度。(这些标志还区分了这是元组锁还是元组更新信息。)
Infomask Bits(Infomask中位对应的含义):
- HEAP_XMAX_INVALID
Any tuple with this bit set does not have a valid value stored in XMAX.
设置此位表示XMAX无效
- HEAP_XMAX_IS_MULTI
This bit is set if the tuple's Xmax is a MultiXactId (as opposed to a
regular TransactionId).
设置此位表示XMAX中存储的是MultiXactId,否则是TransactionId
- HEAP_XMAX_LOCK_ONLY
This bit is set when the XMAX is a locker only; that is, if it's a
multixact, it does not contain an update among its members. It's set when
the XMAX is a plain Xid that locked the tuple, as well.
- HEAP_XMAX_KEYSHR_LOCK
- HEAP_XMAX_SHR_LOCK
- HEAP_XMAX_EXCL_LOCK
These bits indicate the strength of the lock acquired; they are useful when
the XMAX is not a MultiXactId. If it's a multi, the info is to be found in
the member flags. If HEAP_XMAX_IS_MULTI is not set and HEAP_XMAX_LOCK_ONLY
is set, then one of these *must* be set as well.
这三位就是表示元组上有的元组锁强度对应的位了,注意这里没有SELECT FOR SHARE,原因见上
Note that HEAP_XMAX_EXCL_LOCK does not distinguish FOR NO KEY UPDATE from
FOR UPDATE; this is implemented by the HEAP_KEYS_UPDATED bit.
- HEAP_KEYS_UPDATED
This bit lives in t_infomask2. If set, indicates that the XMAX updated
this tuple and changed the key values, or it deleted the tuple.
It's set regardless of whether the XMAX is a TransactionId or a MultiXactId.
如果设置,表示更新了元组的值和键值,或者是元组被删除了
We currently never set the HEAP_XMAX_COMMITTED when the HEAP_XMAX_IS_MULTI bit
is set.
死锁检测算法:
我们希望在没有死锁的情况下,常规操作能够快速运行,尽可能避免死锁检测开销。所以我们使用乐观等待(optimistic waiting)来执行操作:如果进程无法立即获得需要的锁,则它在没有任何死锁检测的情况下进入睡眠状态,同时设置一个延迟计时器,延迟为死锁超时时间(毫秒计,通常设置为1秒)。如果在达到延迟时间后仍然没有获得锁,则进入死锁检测/中断代码。一般情况,检测没有死锁,这时进程返回睡眠状态,并永久等待直到获得锁。否则,检测到死锁,则处理死锁。通常情况下是通过中止掉检测死锁的进程的事务。这样,当锁的等待时间少于等待超时时间,就节约下了死锁检测的开销。
锁的获取(例程LockAcquire和ProcSleep)遵循以下规则:
1.如果锁请求不与任何已有的或者等待的锁请求冲突,或者这个进程已经拥有同一锁类型的实例,则立即同意锁请求。进程不会和自己冲突(如,已获取独占锁时,可以再获取读锁)。
2.否则,进程将加入锁的等待队列。通常它会被添加到队列的末尾,但有一个例外:如果进程在同一个可锁对象已经上持有与某些挂起的等待进程的请求冲突的锁,那么该进程插入队列时将被插入到第一个这样的等待进程的前面(如果我们不做这个检查,死锁检测代码会调整队列顺序来解决冲突,但是在ProcSleep中进行检查是相对便宜的,并且在这种情况下可以避免死锁超时延迟)。在队列末尾插入的特殊情况:如果进程的请求不与任何现有的锁冲突,也不与在其插入点之前任何等待请求冲突,这时不等待地授予锁。
释放锁时,锁释放例程(ProcLockWakeup)扫描锁对象的等待队列。每个符合条件的等待进程会被唤醒,当(a)其请求与已授予的锁不冲突,并且(b)其请求与前面未被唤醒的等待进程的请求不冲突。规则(b)确保按照到达顺序授予冲突请求。在某些情况下,为了避免死锁,必须允许后面的等待进程走到前面的等待进程的前面,但ProcLockWakeup不负责识别这些情况;相反,死锁检测代码将在必要时重新排序等待队列。
为了执行死锁检查,我们使用标准方法,将各个进程视为有向图(waits-for graph或WFG)中的节点。如果进程A等待进程B,即A正在等待某个锁,而B持有与这个锁冲突的锁,则WFG有一个从进程A指向进程B的有向边。当且仅当WFG中有回路时,才有死锁。我们通过沿着有向图的传出边搜索来检测回路的存在。有三种可能的结果:
1.所有传出的路径都终止于正在运行的进程(这个进程没有传出边)。
2.死锁是通过循环回起点被检测出的。我们通过取消起点的锁请求同时向事务抛出错误来解决死锁。这通常导致事务取消并释放事务拥有的所有锁。
3.某些路径在起点之外的点循环。这也是一个死锁,但它不涉及起点进程。我们忽略这个死锁条件,因为解决这个死锁是有关进程的责任,和起点进程无关,结束起点进程也不解决死锁。因此,情况1和情况3都没有死锁。
Postgres的情况稍有不同且更加复杂,因为:
1.一个进程可以同时等待多个其他进程,因为存在多种(不冲突的)锁类型的PROCLOCK,它们都和等待请求冲突。但这不是很复杂,只需要准备好跟踪多个传出路径罢了。
2.如果在某个锁的等待队列中,进程A在进程B后,且它们的请求冲突,这时我们也要看作A等待B,因为ProcLockWakeup不会在唤醒B之前唤醒A。这导致了WFG中额外的边。我们成它为soft边,相对应的,hard边是由已经授予的锁产生的。注意:在上例中,如果B已经持有和A冲突锁,则它们之间的边是hard边而不是soft边。
一个soft块,或者叫等待优先(wait-priority)块,具有和hard边一样的产生死锁的可能。但是,soft边的消除不需要中止有关的事务:通过重新排序等待队列。重新排序会反转两个冲突请求之间的soft边的方向。如果能找到一个新的排列,不会产生新的回路,那就可以避免事务的取消了。这很困难。
死锁检测器的主力是例程FindLockCycle(),它被赋予给了一个起点进程(这个进程必须是等待进程)。它递归地沿着有向图的等待边向外扫描,如上所述。如果未找到涉及起点的回路,返回false。如果找到,返回true,且当它回溯时,还会生成一个回路中包含的所有soft边的列表。如果这列表为空,则表示出现hard死锁,重新排序不能消除死锁。然而,如果这个列表非空,通过等待队列的重新排序反转任意一个列表中的soft边可以消除回路。由于这种反转可能在其他地方产生新的回路,我们需要作多次尝试。因此,我们需要能够像在当前的真正等待队列上使用FindLockCycle()一般,也要能在拟议重新排序后的等待队列上使用FindLockCycle()。
处理此问题的最简单方法似乎是使用一个lookaside表,该表记录我们正在考虑重新排序的每个等待队列的拟议新队列顺序。用FindLockCycle测试这个表的表项,选择能够解决死锁且不产生死锁的排序。
我们通过对已存在的队列进行拓扑排序(topological sort)来获得这么一个拟议新队列。每一个我们考虑反转的soft边都产生一个拓扑排序必须满足的偏序属性。我们必须使用一个尽可能多的保存输入顺序的排序方法,以免无端中断不涉及死锁的进程的到达顺序。拓扑排序的失败说明有冲突的排序约束条件,因此,最后添加的soft边的反转和之前的边的反转冲突。我们需要检测出这种情况,避免在重新排序不可能生效的情况下无限循环:我们尝试反转,发现导致另一个回路,然后尝试反转这个反转来避免回路,一直下去。。。。拓扑排序失败就告诉我们这种情况下,取消这个反转是个不合适的操作。
所以,我们重新排序的基本步骤是获取一个回路中的soft边列表(由FindLockCycle()获取),然后依次尝试将每个边的反转作为拓扑排序的约束,加入到我们已有的约束中。我们递归地查询这些约束集,看是否有一个约束集可以同时消除所有死锁回路。虽然这看起来效率不高,但事实上这不是个大问题,因为通常死锁回路很少,也不是很大--如果有的话。
每个边反转的约束都可被看作为,在等待进程A和等待进程B所在的同一个等待队列中,A被移动到了B之前。这个操作将反转AB之间的soft边,和所有A和A超过的进程之间的soft边。其他边不会被影响(实际上这是我们拓扑排序的一个约束:不要超过必要次数的重新排序)。因此,如果FindLockCycle(A)和FindLockCycle(B)都没有发现回路,我们可以肯定没有创建新的死锁回路。鉴于FindLockCycle的上述定义行为,这些搜索中的每一个都是充要的,因为从原开始点开始的FindLockCycle不会关心包含A或B,但不包含原开始点的回路。
简言之,一个等待队列拟议的重新排序是由一个或多个断开的soft边A->B确定,完全由每一个所涉及的等待队列的拓扑排序的结果指定,然后由原开始点和每一个相关进程(A,B)调用FindLockCycle()测试。如果没有测试检测到回路,那么我们就拥有了一个有效的解决方案,可以通过按照每个拓扑排序结果重新排序来实现它(然后对每个重新排序的队列调用ProcLockWakeup,可能此时有等待进程可被唤醒了)。如果所有测试都检测到了soft回路,我们可以尝试通过依次添加回路中的soft边到拟定重新排序列表来解决。这会一直递归下去,知道找到一个有效的重新排序或者确定不存在。在后一种可能下,外层通过中止事务来解决死锁。
尝试的重新排序中特定的顺序取决于FindLockCycle()扫描的顺序,所以如果等待队列有多个有效的重新排序,没有指定哪一个会被选择。更重要的是我们保证尝试每一个可能成功的队列的重新排序。(例如,如果我们有排序A, B, C,我们需要的排序的约束是C在A前和B在C前,我们可能先发现A在C前有冲突,从而尝试重新排序为C, A, B(C提到A前面),这最终可能导致额外约束B在C前的产生)。
3.锁检测流程
Postgres中用锁保护了数据,所以对数据的访问,不管是读还是写,都需要获得数据关系上的锁。这里来讲下Postgres已经设置好的锁方法(LockMethod)。
Postgres的default_method和user_method是同样的内容,我们就来看下default_method的定义:
static const LockMethodData default_lockmethod = {
AccessExclusiveLock, /* highest valid lock mode number */
LockConflicts,
lock_mode_names,
#ifdef LOCK_DEBUG
&Trace_locks
#else
&Dummy_trace
#endif
};
第一个值是锁类型种类总数,这里为8,Postgres提供的锁一共有8种,分别是:
AccessShareLock(访问共享锁)、RowShareLock(行共享锁)、RowExclusiveLock(行排他锁)
ShareUpdateExclusiveLock(共享更新排他锁)、ShareLock(共享锁)
ShareRowExclusiveLock(行共享排他锁)、ExclusiveLock(排它锁)、AccessExclusiveLock(访问排他锁)
/* NoLock is not a lock mode, but a flag value meaning "don't get a lock" */
#define NoLock 0
#define AccessShareLock 1 /* SELECT */
#define RowShareLock 2 /* SELECT FOR UPDATE/FOR SHARE */
#define RowExclusiveLock 3 /* INSERT, UPDATE, DELETE */
#define ShareUpdateExclusiveLock 4 /* VACUUM (non-FULL),ANALYZE, CREATE INDEX
* CONCURRENTLY */
#define ShareLock 5 /* CREATE INDEX (WITHOUT CONCURRENTLY) */
#define ShareRowExclusiveLock 6 /* like EXCLUSIVE MODE, but allows ROW
* SHARE */
#define ExclusiveLock 7 /* blocks ROW SHARE/SELECT...FOR UPDATE */
#define AccessExclusiveLock 8 /* ALTER TABLE, DROP TABLE, VACUUM FULL,
* and unqualified LOCK TABLE */
#define MaxLockMode 8
第二个值是锁冲突表,定义为下:
#define LOCKBIT_ON(lockmode) (1 << (lockmode))
static const LOCKMASK LockConflicts[] = {
0,
/* AccessShareLock */
LOCKBIT_ON(AccessExclusiveLock),
/* RowShareLock */
LOCKBIT_ON(ExclusiveLock) | LOCKBIT_ON(AccessExclusiveLock),
/* RowExclusiveLock */
LOCKBIT_ON(ShareLock) | LOCKBIT_ON(ShareRowExclusiveLock) |
LOCKBIT_ON(ExclusiveLock) | LOCKBIT_ON(AccessExclusiveLock),
/* ShareUpdateExclusiveLock */
LOCKBIT_ON(ShareUpdateExclusiveLock) |
LOCKBIT_ON(ShareLock) | LOCKBIT_ON(ShareRowExclusiveLock) |
LOCKBIT_ON(ExclusiveLock) | LOCKBIT_ON(AccessExclusiveLock),
/* ShareLock */
LOCKBIT_ON(RowExclusiveLock) | LOCKBIT_ON(ShareUpdateExclusiveLock) |
LOCKBIT_ON(ShareRowExclusiveLock) |
LOCKBIT_ON(ExclusiveLock) | LOCKBIT_ON(AccessExclusiveLock),
/* ShareRowExclusiveLock */
LOCKBIT_ON(RowExclusiveLock) | LOCKBIT_ON(ShareUpdateExclusiveLock) |
LOCKBIT_ON(ShareLock) | LOCKBIT_ON(ShareRowExclusiveLock) |
LOCKBIT_ON(ExclusiveLock) | LOCKBIT_ON(AccessExclusiveLock),
/* ExclusiveLock */
LOCKBIT_ON(RowShareLock) |
LOCKBIT_ON(RowExclusiveLock) | LOCKBIT_ON(ShareUpdateExclusiveLock) |
LOCKBIT_ON(ShareLock) | LOCKBIT_ON(ShareRowExclusiveLock) |
LOCKBIT_ON(ExclusiveLock) | LOCKBIT_ON(AccessExclusiveLock),
/* AccessExclusiveLock */
LOCKBIT_ON(AccessShareLock) | LOCKBIT_ON(RowShareLock) |
LOCKBIT_ON(RowExclusiveLock) | LOCKBIT_ON(ShareUpdateExclusiveLock) |
LOCKBIT_ON(ShareLock) | LOCKBIT_ON(ShareRowExclusiveLock) |
LOCKBIT_ON(ExclusiveLock) | LOCKBIT_ON(AccessExclusiveLock)
};
整理成表格形式就是这样。
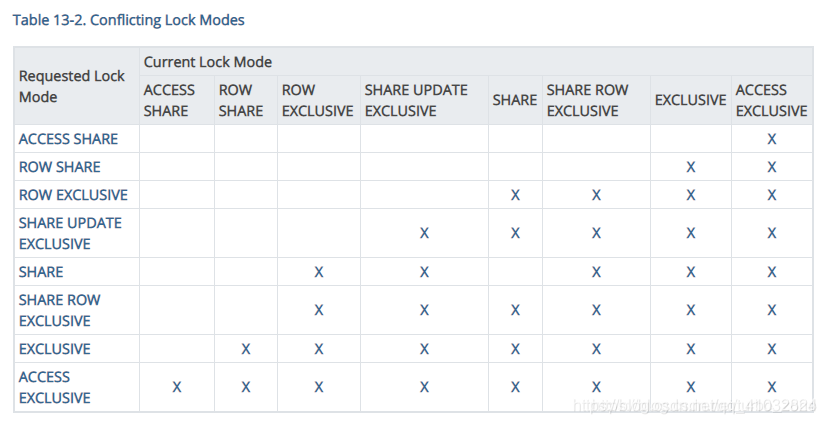
可以见到,前三个锁互不冲突(包括自己),所以可以用于fast-path机制。后面的锁就都属于strong锁了。
第三个值是各个锁的名字,用于输出错误信息的,第四个值和GUC有关。
以上的锁模式使全部的锁模式,表级锁使用所有的所模式,但是Postgres还使用部分锁关系来定义新的锁关系,Postgres还有一类行级锁,行级锁的加锁对象是某个表上的元组,我们可以只获取元组上的锁而不是整个表的锁。行级锁有4类,分别是:
typedef enum LockTupleMode
{
/* SELECT FOR KEY SHARE */
LockTupleKeyShare,
/* SELECT FOR SHARE */
LockTupleShare,
/* SELECT FOR NO KEY UPDATE, and UPDATEs that don't modify key columns */
LockTupleNoKeyExclusive,
/* SELECT FOR UPDATE, UPDATEs that modify key columns, and DELETE */
LockTupleExclusive
} LockTupleMode;
行级锁的获取也是和表级锁一样的,这四类锁分别被映射到最基本的八类锁的其中四个上,如下:
static const struct
{
LOCKMODE hwlock;
int lockstatus;
int updstatus;
}
tupleLockExtraInfo[MaxLockTupleMode + 1] =
{
{ /* LockTupleKeyShare */
AccessShareLock,
MultiXactStatusForKeyShare,
-1 /* KeyShare does not allow updating tuples */
},
{ /* LockTupleShare */
RowShareLock,
MultiXactStatusForShare,
-1 /* Share does not allow updating tuples */
},
{ /* LockTupleNoKeyExclusive */
ExclusiveLock,
MultiXactStatusForNoKeyUpdate,
MultiXactStatusNoKeyUpdate
},
{ /* LockTupleExclusive */
AccessExclusiveLock,
MultiXactStatusForUpdate,
MultiXactStatusUpdate
}
};
所以我们可以得出这四类锁的冲突表:

现在,我们了解了Postgres的锁方法,接下来就讲获取锁的流程:
直接讲解代码,获取锁的函数是LockAcquireExtended(lock.c),不是特别重要的地方不会着重加注释和高亮。
/*
* Input:
* locktag: 指定需要加锁的对象
* lockmode: 请求的锁类型
* sessionLock: if true, acquire lock for session not current transaction
* dontWait: 如果为true,不会一直等待到成功获取锁
* reportMemoryError: 指定填充lock表时是否生成错误,传递false允许调用方尝试从lock表
* 已满的情况下恢复,也许是通过强制取消其他lock持有者,然后重试。注意,此时返回的值为
* LOCKACQUIRE_NOT_AVAIL,所以不要和dontWait=true一起使用,因为此时无法区分错误原因
*
* Output:
* *locallockp: 如果传入不为NULL,获取成功后指向LOCALLOCK表对应的表项
*/
LockAcquireResult
LockAcquireExtended(const LOCKTAG *locktag,
LOCKMODE lockmode,
bool sessionLock,
bool dontWait,
bool reportMemoryError,
LOCALLOCK **locallockp)
{
LOCKMETHODID lockmethodid = locktag->locktag_lockmethodid;
LockMethod lockMethodTable;
LOCALLOCKTAG localtag;
LOCALLOCK *locallock;
LOCK *lock;
PROCLOCK *proclock;
bool found;
ResourceOwner owner;
uint32 hashcode;
LWLock *partitionLock;
int status;
bool log_lock = false;
/* 防止无效调用 */
if (lockmethodid <= 0 || lockmethodid >= lengthof(LockMethods))
elog(ERROR, "unrecognized lock method: %d", lockmethodid);
lockMethodTable = LockMethods[lockmethodid];
if (lockmode <= 0 || lockmode > lockMethodTable->numLockModes)
elog(ERROR, "unrecognized lock mode: %d", lockmode);
/* 数据库恢复期间不能加strong锁 */
if (RecoveryInProgress() && !InRecovery &&
(locktag->locktag_type == LOCKTAG_OBJECT ||
locktag->locktag_type == LOCKTAG_RELATION) &&
lockmode > RowExclusiveLock)
ereport(ERROR,
(errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
errmsg("cannot acquire lock mode %s on database objects while recovery is in progress",
lockMethodTable->lockModeNames[lockmode]),
errhint("Only RowExclusiveLock or less can be acquired on database objects during recovery.")));
#ifdef LOCK_DEBUG
if (LOCK_DEBUG_ENABLED(locktag))
elog(LOG, "LockAcquire: lock [%u,%u] %s",
locktag->locktag_field1, locktag->locktag_field2,
lockMethodTable->lockModeNames[lockmode]);
#endif
/* 标识获取锁的用户 */
if (sessionLock)
owner = NULL;
else
owner = CurrentResourceOwner;
/*
* 查找或者新建一个关联请求lock和lockmode的LOCALLOCK
* 最先应该查看的就是本后端(爸爸)是否已经获取了我想要的锁了
*/
MemSet(&localtag, 0, sizeof(localtag)); /* must clear padding */
localtag.lock = *locktag;
localtag.mode = lockmode;
/* 在本后端的LOCALLOCK哈希表中查找是否已经有这个LOCALLOCK */
locallock = (LOCALLOCK *) hash_search(LockMethodLocalHash,
(void *) &localtag,
HASH_ENTER, &found);
/*
* 如果LOCALLOCK表中没有,就先创建一个,到时候再找总表管理要
*/
if (!found)
{
locallock->lock = NULL;
locallock->proclock = NULL;
locallock->hashcode = LockTagHashCode(&(localtag.lock));
locallock->nLocks = 0;
locallock->holdsStrongLockCount = false;
locallock->lockCleared = false;
locallock->numLockOwners = 0;
locallock->maxLockOwners = 8;
locallock->lockOwners = NULL; /* in case next line fails */
locallock->lockOwners = (LOCALLOCKOWNER *)
MemoryContextAlloc(TopMemoryContext,
locallock->maxLockOwners * sizeof(LOCALLOCKOWNER));
}
else /* 如果找到了,就需要向后端表管理(爸爸)要求分我一份,这里只确定空间足够 */
{
/* Make sure there will be room to remember the lock */
if (locallock->numLockOwners >= locallock->maxLockOwners)
{
int newsize = locallock->maxLockOwners * 2;
locallock->lockOwners = (LOCALLOCKOWNER *)
repalloc(locallock->lockOwners,
newsize * sizeof(LOCALLOCKOWNER));
locallock->maxLockOwners = newsize;
}
}
hashcode = locallock->hashcode;
/* 如果locallockp!=NULL,就可以让它指向这个找到或者创建的LOCALLOCK了 */
if (locallockp)
*locallockp = locallock;
/*
* 如果后端已有这个lock,那就让后端记住我们要了一份这个lock,增加分配计数和记上我
* 暂不明白为什么这一步不放在上面的else里,是为了代码好看?
*
* If lockCleared is already set, caller need not worry about absorbing
* sinval messages related to the lock's object.
*/
if (locallock->nLocks > 0)
{
GrantLockLocal(locallock, owner); //这个函数没必要看,了解它是让locallock
//增加一个分配计数,并记住“我”
if (locallock->lockCleared)
return LOCKACQUIRE_ALREADY_CLEAR;
else
return LOCKACQUIRE_ALREADY_HELD; //成功获取锁,返回
}
/* WAL日志相关,可以不用管
* Prepare to emit a WAL record if acquisition of this lock needs to be
* replayed in a standby server.
*
* Here we prepare to log; after lock is acquired we'll issue log record.
* This arrangement simplifies error recovery in case the preparation step
* fails.
*
* Only AccessExclusiveLocks can conflict with lock types that read-only
* transactions can acquire in a standby server. Make sure this definition
* matches the one in GetRunningTransactionLocks().
*/
if (lockmode >= AccessExclusiveLock &&
locktag->locktag_type == LOCKTAG_RELATION &&
!RecoveryInProgress() &&
XLogStandbyInfoActive())
{
LogAccessExclusiveLockPrepare();
log_lock = true;
}
/*
* Attempt to take lock via fast path, if eligible. But if we remember
* having filled up the fast path array, we don't attempt to make any
* further use of it until we release some locks. It's possible that some
* other backend has transferred some of those locks to the shared hash
* table, leaving space free, but it's not worth acquiring the LWLock just
* to check. It's also possible that we're acquiring a second or third
* lock type on a relation we have already locked using the fast-path, but
* for now we don't worry about that case either.
* 从后端获取锁失败后,尝试使用fast path机制来获取锁
*/
//如果是可通过fast path机制获取的锁(前面说过的,之间不会冲突的锁)
//且这个后端通过fast path获取的锁没达到上限
if (EligibleForRelationFastPath(locktag, lockmode) &&
FastPathLocalUseCount < FP_LOCK_SLOTS_PER_BACKEND)
{
//获取fast path机制中,锁对应分区的值
uint32 fasthashcode = FastPathStrongLockHashPartition(hashcode);
bool acquired;
/*
* LWLockAcquire acts as a memory sequencing point, so it's safe to
* assume that any strong locker whose increment to
* FastPathStrongRelationLocks->counts becomes visible after we test
* it has yet to begin to transfer fast-path locks.
* 在这里利用后端对自己数据保护用的LWLock来实现同后端不同进程顺序操作,后面也经常会这么使用
* 实际上,并没有对LWLock本应该保护的数据进行操作
*/
LWLockAcquire(&MyProc->backendLock, LW_EXCLUSIVE);
//如果lock对应的分区中已经分配了strong锁,则不能直接获取锁,因为可能就是我想获得的锁上
//有了更强的锁,否则可以获取到
//其实这里就像是先斩后奏,如果不存在冲突的可能性,我就直接获取了锁用着了,这样就加快了获取锁
//的速度,fast path就是这么来的
if (FastPathStrongRelationLocks->count[fasthashcode] != 0)
acquired = false;
else
acquired = FastPathGrantRelationLock(locktag->locktag_field2,
lockmode); /* 这个函数在
后端数据信息中存储分配fast path的部分,先找有没有已经有这个关系被记录了。
如果有则加上这个localmode,如果没有,则找到一个能分配的地方,并在
那设置上这个关系id和lockmode,如果位置也没了,就返回false */
LWLockRelease(&MyProc->backendLock);
if (acquired)
{
/* 因为是通过fast path机制获取的锁,主锁表其实不知道你获得了,所以lock和
* proclock应该指向NULL
* The locallock might contain stale pointers to some old shared
* objects; we MUST reset these to null before considering the
* lock to be acquired via fast-path.
*/
locallock->lock = NULL;
locallock->proclock = NULL;
GrantLockLocal(locallock, owner);
return LOCKACQUIRE_OK;
}
}
/*
* If this lock could potentially have been taken via the fast-path by
* some other backend, we must (temporarily) disable further use of the
* fast-path for this lock tag, and migrate any locks already taken via
* this method to the main lock table.
* 接下来,因为fast path获取lock失败,所以必须向主锁管理器要lock了,首先要做的是
* 防止其他进程已经从fast path机制获取锁。不管需要的是弱(week)关系锁还是强(strong)关系锁,
* 都需要确保其他进程的fast path锁同步到主锁表中,这是为了防止冲突检测和死锁检测不能正常运作
*/
if (ConflictsWithRelationFastPath(locktag, lockmode))
{
//同样先获取锁所在分区
uint32 fasthashcode = FastPathStrongLockHashPartition(hashcode);
//这个函数将fast path对应分区的strong锁数量加1,并设置locallock->holdsStrongLockCount=true
BeginStrongLockAcquire(locallock, fasthashcode);
//这个函数扫描所有进程,查找本地fast path表中是否有对应锁,如果有,则把这个锁传到主lock表中
if (!FastPathTransferRelationLocks(lockMethodTable, locktag,
hashcode))
{ //如果操作失败,没能传到主表中,原因就是主表里存不了了,获取锁的操作就失败了
AbortStrongLockAcquire();
if (locallock->nLocks == 0)
RemoveLocalLock(locallock);
if (locallockp)
*locallockp = NULL;
if (reportMemoryError)
ereport(ERROR,
(errcode(ERRCODE_OUT_OF_MEMORY),
errmsg("out of shared memory"),
errhint("You might need to increase max_locks_per_transaction.")));
else
return LOCKACQUIRE_NOT_AVAIL;
}
}
/*
* We didn't find the lock in our LOCALLOCK table, and we didn't manage to
* take it via the fast-path, either, so we've got to mess with the shared
* lock table.
* 同步完成了,现在就该向主表要lock了
*/
// 主表在共享内存中,共享内存分区了,由LWLock保护,所以先要获得LWLock
partitionLock = LockHashPartitionLock(hashcode);
LWLockAcquire(partitionLock, LW_EXCLUSIVE);
/*
* Find or create lock and proclock entries with this tag
*
* Note: if the locallock object already existed, it might have a pointer
* to the lock already ... but we should not assume that that pointer is
* valid, since a lock object with zero hold and request counts can go
* away anytime. So we have to use SetupLockInTable() to recompute the
* lock and proclock pointers, even if they're already set.
*/
//在主表中先找有没有已经有这个锁了,没找到就创建一个
proclock = SetupLockInTable(lockMethodTable, MyProc, locktag,
hashcode, lockmode);
if (!proclock) //没找到也创建不了,GG
{
AbortStrongLockAcquire();
LWLockRelease(partitionLock);
if (locallock->nLocks == 0)
RemoveLocalLock(locallock);
if (locallockp)
*locallockp = NULL;
if (reportMemoryError)
ereport(ERROR,
(errcode(ERRCODE_OUT_OF_MEMORY),
errmsg("out of shared memory"),
errhint("You might need to increase max_locks_per_transaction.")));
else
return LOCKACQUIRE_NOT_AVAIL;
}
//找到了,赶快记下来
locallock->proclock = proclock;
lock = proclock->tag.myLock;
locallock->lock = lock;
/*
* If lock requested conflicts with locks requested by waiters, must join
* wait queue. Otherwise, check for conflict with already-held locks.
* (That's last because most complex check.)
* 锁是找到了(不一定是创建的),但是这也就说明别人已经提前一步获得了,那就得进行冲突检测了
*/
//如果和等待队列的请求冲突,那就只能也排队等了
if (lockMethodTable->conflictTab[lockmode] & lock->waitMask)
status = STATUS_FOUND;
else //如果不冲突,诶,对不起,我可以插队,先走一步了
status = LockCheckConflicts(lockMethodTable, lockmode,
lock, proclock); /* 为什么这里还需要一个较为复杂的
函数来检测锁请求是否与当前已授权锁冲突呢。因为有个规则是:进程不会和自己冲突,这
在第二节讲了,还有就是同一锁组(lock group)中不同进程之间也不会冲突,所以必须先
把同进程或者同锁组的兄弟们排除了,再判断是否有冲突 */
if (status == STATUS_OK)
{
/* 没冲突,成功获取锁,在lock中记下我,同时locallock也要关联上 */
GrantLock(lock, proclock, lockmode);
GrantLockLocal(locallock, owner);
}
else
{
Assert(status == STATUS_FOUND);
/*
* We can't acquire the lock immediately. If caller specified no
* blocking, remove useless table entries and return NOT_AVAIL without
* waiting.
*/
if (dontWait)
{ //不排队了,直接返回错误,下面也不用看了,就是失败了之后把已准备的,已获得的都还原
AbortStrongLockAcquire();
if (proclock->holdMask == 0)
{
uint32 proclock_hashcode;
proclock_hashcode = ProcLockHashCode(&proclock->tag, hashcode);
SHMQueueDelete(&proclock->lockLink);
SHMQueueDelete(&proclock->procLink);
if (!hash_search_with_hash_value(LockMethodProcLockHash,
(void *) &(proclock->tag),
proclock_hashcode,
HASH_REMOVE,
NULL))
elog(PANIC, "proclock table corrupted");
}
else
PROCLOCK_PRINT("LockAcquire: NOWAIT", proclock);
lock->nRequested--;
lock->requested[lockmode]--;
LOCK_PRINT("LockAcquire: conditional lock failed", lock, lockmode);
Assert((lock->nRequested > 0) && (lock->requested[lockmode] >= 0));
Assert(lock->nGranted <= lock->nRequested);
LWLockRelease(partitionLock);
if (locallock->nLocks == 0)
RemoveLocalLock(locallock);
if (locallockp)
*locallockp = NULL;
return LOCKACQUIRE_NOT_AVAIL;
}
/*
* Set bitmask of locks this process already holds on this object.
*/
MyProc->heldLocks = proclock->holdMask;
/*
* Sleep till someone wakes me up.
*/
//加入等待队列慢慢排队吧,拍到我了就会叫醒我
TRACE_POSTGRESQL_LOCK_WAIT_START(locktag->locktag_field1,
locktag->locktag_field2,
locktag->locktag_field3,
locktag->locktag_field4,
locktag->locktag_type,
lockmode);
WaitOnLock(locallock, owner);
TRACE_POSTGRESQL_LOCK_WAIT_DONE(locktag->locktag_field1,
locktag->locktag_field2,
locktag->locktag_field3,
locktag->locktag_field4,
locktag->locktag_type,
lockmode);
/*
* NOTE: do not do any material change of state between here and
* return. All required changes in locktable state must have been
* done when the lock was granted to us --- see notes in WaitOnLock.
*/
/*
* Check the proclock entry status, in case something in the ipc
* communication doesn't work correctly.
*/
if (!(proclock->holdMask & LOCKBIT_ON(lockmode)))
{
AbortStrongLockAcquire();
PROCLOCK_PRINT("LockAcquire: INCONSISTENT", proclock);
LOCK_PRINT("LockAcquire: INCONSISTENT", lock, lockmode);
/* Should we retry ? */
LWLockRelease(partitionLock);
elog(ERROR, "LockAcquire failed");
}
PROCLOCK_PRINT("LockAcquire: granted", proclock);
LOCK_PRINT("LockAcquire: granted", lock, lockmode);
}
/*
* Lock state is fully up-to-date now; if we error out after this, no
* special error cleanup is required.
*/
FinishStrongLockAcquire();
LWLockRelease(partitionLock);
/*
* Emit a WAL record if acquisition of this lock needs to be replayed in a
* standby server.
*/
if (log_lock)
{
/*
* Decode the locktag back to the original values, to avoid sending
* lots of empty bytes with every message. See lock.h to check how a
* locktag is defined for LOCKTAG_RELATION
*/
LogAccessExclusiveLock(locktag->locktag_field1,
locktag->locktag_field2);
}
//最后成功得到了lock
return LOCKACQUIRE_OK;
}
获取锁的关键步骤就都在这里了,总结起来就和第二节里说的一样:
- 最先应该查看本后端是否已经获取了想要的锁
- 从后端获取锁失败后,尝试使用fast path机制来获取锁
- fast path获取lock失败,所以必须向主锁管理器要lock了,首先要将其他进程的fast path锁同步到主锁表中
- 从主锁管理器申请一个lock
- 进行锁冲突检查,如果dontWait为false则要加入等待队列等待唤醒
释放锁就更简单了,代码的话,看了锁申请的代码应该都能看懂,这里就只讲下主要步骤吧:
- 本进程LOCALLOCK表中找到要释放的lock,如果没找到那肯定就是你没这个锁咯
- 将locallock中成员数组中找到我并将我拥有这个锁的次数减一,如果减到0了,就还要将我从成员中移除,同时成员数减一
- locallock的分配总数当然也要减一了,如果减为0了,那就要在锁表中移除这个表了
- 如果这个锁在fast path锁表中,也要移去
- 如果不在,那就是在主表中了咯,在主表中找到这个表并移去
- 最后,重中之重,看看我放弃这个锁后需不需要唤醒等待队列中的某些苦逼等待的进程,如果需要,赶快唤醒它们
4.总结
有关这次分析的行级锁/会话锁的主要内容就这些了,锁的分析我主要还是通过Postgres的README先了解整个的实现方式,再结合函数看数据结构。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









