






提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
DAY3 深度学习之李沐大神笔记(1)
数据操作与数据预处理
一、数据操作
访问元素:一个元素: [1,2] 一行:[1,:] 一列: [:,1] 子区域:[1:3,1:] 子区域: [::3,::2]。

二、数据操作的实现
a = torch.arange(3).reshape((3,1))
b = torch.arange(2).reshape((1,2))
a,b
a+b

首先维度相同,但是行列不相同,如果相加,则运用了广播机制,即(3,1)复制列数复制[0],[1],[2]。变为[[0,0],[1,1],[2,2]]。(1,2)复制3行行数[0,1],变为[[0,1],[0,1],[0,1]]。求和即为[[0,1],[1,2],[2,3]]。
数据预处理的实现
import os
os.makedirs(os.path.join('..','data'),exist_ok=True)
data_file = os.path.join('..','data','house_tiny.csv')
with open(data_file,'w') as f:
f.write('NumRooms,Alley,Price\n')
f.write('NA,Pave,1275000\n')
f.write('2,NA,106000\n')
f.write('4,NA,178100\n')
f.write('NA,NA,140000\n')
创建文件夹,将数据写入文件。
import pandas as pd
data = pd.read_csv(data_file)
data
Pandas 是 Python 语言的一个扩展程序库,用于数据分析。Pandas 是一个开放源码、BSD 许可的库,提供高性能、易于使用的数据结构和数据分析工具。
inputs,outputs = data.iloc[:,0:2],data.iloc[:,2]
inputs = inputs.fillna(inputs.mean())
print(inputs)
将第零列、第一列写入输入数据(因为是开区间),将第二列写入输出数据。
为了处理缺失的数据,典型的方法包括插值和删除。
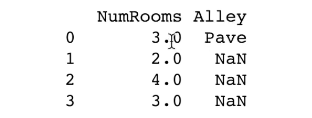
对于inputs中的类别值或离散值,我们将“NaN”视为一个类别。
inputs = pd.get_dummies(inputs,dummy_na=True)
print(inputs)

import torch
X,y=torch.tensor(inputs.values),torch.tensor(outputs.values)
X,y
将inputs和outputs中的所有条目转为数值类型后,便可以转换为张量格式。
总结
提示:这里对文章进行总结:
今天了解了张量的使用,并且掌握了数据处理的相关方法,对于pandas有了新的理解。















 2086
2086











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









