







前言
第一章
1.大数据的四个特点(4V)
(1)数据量大(Volume):数据量十分巨大,已经从TB级别跃升到PB级别
(2)数据类型繁多(Variety):分为结构化数据(10%),非结构化数据(90%),非结构化数据包含半结构化数据;结构化数据指存储在关系数据库种的数据,后者种类繁多,包括邮件、音频、视频、微信、微博、位置信息、链接信息、手机呼叫信息,网络日志等
(3)处理速度快(Velocity):实时分析结果、秒级响应
(4)价值密度低(Value):价值密度远低于传统关系数据库种已有的那些数据
2.大数据计算模式
(1)批处理计算:
A:MapReduce:大数据批处理技术,可以并行执行大规模数据处理任务,用于大规模数据集的并行计算。
B:Spark:一个针对大数据集合的低延迟的集群分布式计算系统,比MapReduce快许多
(2)流计算:
流数据是指在时间分布和数量上误先的一系列动态数据集合体,书记的价值随时间的流失而降低,因此必须采用实时计算的方式给出秒级响应。
流计算:可以实时处理来自不同数据源的、连续到达的流数据,经过实时分析处理、给出有价值的分析结果。
3.云计算
1.云计算的概念
1.云计算实现了通过网络提供可伸缩的、廉价的分布式计算能力
2.云计算3种服务模式:
a:IaaS(基础设施即服务):将基础设施(计算资源(cpu、内存)和存储(磁盘))作为服务出租
b:PaaS(平台即服务):把平台作为服务出租
c:SaaS(软件即服务):把软件作为服务出租
3.元计算的三种类型:
a:公有云:面向所有用户提供服务
b:私有云:只为特定用户提供服务
c:混合云:综合了公有云和私有云的特点(因为对一些企业而言,一方面出于安全考虑需要把数据放在私有云中,另一方面又希望可以获得公有云的计算资源,就可以把公有云和私有云进行混合搭配使用)
2.云计算的关键技术

(1)虚拟化
虚拟化技术是云计算架构的基石,是指将一台计算机虚拟为多台逻辑计算机,在一台计算上同时运行多个逻辑计算机,每个逻辑计算机可运行不同的操作系统,并且应用程序都可以在相互独立的空间内运行而互不影响,从而显著提高计算机的工作效率
(2)分布式存储
HDFS(分布式文件系统),采用了简单的“一次写入,多次读取”文件模型,文件一旦创建、写入并关闭了,之后就只能对它执行读取操作,而不能执行修改操作。HDFS基于Java实现。
(3)分布式计算
MapReduce(并行编程模型),它允许开发者在不具备开发经验的前提下也能够开发出分布式的并行程序,并让其运行在数百台机器上,在短时间完成海量数据的计算。
MapReduce把复杂的、运行于大规模集群上的并行计算过程抽象为两个函数—Map和Reduce,并把一个大数据切分成多个小的数据集,分部到不同的机器上进行并行处理,极大的提高了数据处理速度。
3.云计算数据中心的概念:
云计算数据中心是一整套复杂的设施、包括刀片服务器、宽带网络连接、环境控制设备、监控设备以及各种安全装置等。
数据中心是云计算的重要载体,为云计算提供计算、存储、带宽等各种硬件资源,为各种平台和应用提供运行支撑环境
第二章(hadoop)
1.Hadoop
(1)概念:
Hadoop是Apache软件基金会旗下的一个分布式计算平台,为用户提供了系统底层细节透明的开源分部式基础架构。Hadoop被公认为行业大数据标准开源软件
Hadoop是基于Java语言开发的,具有很好的跨平台性。
(2)Hadoop的核心是分布式文件系统HDFS和MapReduce
(3)Hadoop的特点
高可靠性、高效性、高可扩展性、成本低、运行在Linux平台上、支持多种编程语言
(4)Hadoop的三大核心技术
a:HDFS(分布式文件系统、可以运行在廉价商用服务器集群上、低成本高可靠性、很高的吞吐率)
b:Hbase(提供高可靠性、高性能、可伸缩、实时读写、分布式的列式数据库)
c:MapReduce(分布式、并行程序)
对应的google三大技术是:GFS Bigtable MapReduce
2.SSH登录
对于Hadoop的伪分布式和全分布而言,Hadop名称节点(NameNode)需要启动集群中所有机器的Hadoop守护程序,这个过程可以通过SSH登录来实现。(Hadoop没有提供SSH输入密码登录的形式,为了顺利登录每台机器,需要将所有机器配置为名称节点可以无密码登录它们)
3.Hadoop安装方式
(1)单机模式:Hadoop默认模式为非分布式模式(本地模式),无需进行其他配置即可运行。非分布式即单Java进程,方便进行调试
(2)伪分布式模式:Hadoop可以在单节点以上为分布式的方式运行,hadoop进程以分离的Java进程来运行,节点既作为NameNode也作为DataNode,同时,读取的式HDFS中的文件
(3)分布式模式:使用多个节点构成集群环境来运行Hadoop
第三章(HDFS)
1.HDFS的相关概念
HDFS基本存储单元—Block(数据块)默认为64MB。每个块作为独立存储单元。
HDFS主要组件的功能
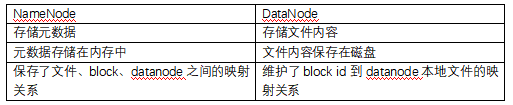
HDFS的命名空间包含目录、文件、块
2.HDFS数据复制
NameNode全权管理数据块的复制,它周期性的从集群中的每个Datanode接收心跳信号和块状态报告。接收到心跳信号意味着该Datanode节点工作正常。块状态报告包含了一个该Datanode上所有数据块的列表
数据块(block)复制:
(1)NameNode发现部分文件的Block数不符合最小复制数或者部分DataNode失效
(2)通知DataNode相互复制Block
(3)DataNode开始相互复制
3.HDFS常用命令
1.列出HDFS文件
Hadoop fs -ls
2.创建
Hadoop fs -mkdir
3.上传文件到HDFS
Hadoop dfs -put test1 test /
hadoop目录下的test1文件上传到HDFS上并重命名为test/
4.将HDFS中的文件复制到本地系统中
hadoop dfs -get test0 test00 /
将HDFS中的test0复制到本地系统并命名为test00/
5.删除HDFS下的文档
hadoop dfs -rmr test00 /
删除HDFS下名为test00的文档/
6.查看HDFS下的某个文件
hadoop dfs -cat ttt /
查看HDFS下ttt文件中的内容/
7.报告HDFS的基本统计信息
hadoop dfsadmin -report
8.退出安全模式
hadoop dfsadmin -safemode leave
9.进入安全模式
hadoop dfsadmin -safemode enter
第四章(HBase)
1.概念
Hbase是一个高可靠、高性能、面向列、可伸缩的分布式数据库,主要用来存储非结构化和半结构化的松散数据
2.HBase和传统关系数据的区别

第七章(MapReduce)
1.MapReduce设计的一个理念
MapReduce设计的一个理念就是“计算向数据靠拢”,而不是“数据向计算靠拢”,因为引动数据需要大量的网络传输开销,尤其是在大规模数据环境下,这种开销尤为惊人,所以,移动计算要比移动数据更加经济
2.MapReduce在三个层面上的构思
(1)如何对付大数据:分而治之
(2)上升到抽象模型:Mapper和Reducer
(3)上升到架构:统一架构,为程序员隐藏系统细节
第九章
1.概念
Spark是基于内存计算的大数据并行计算框架,可用于构建大型的、低延迟的数据分析应用程序
2.应用场景
(1)复杂的批量数据处理
(2)基于历史数据的交互式查询
(3)基于实时数据流的数据处理
3.Spark理念
Spark的设计遵循“一个软件栈满足不同应用场景“的理念,逐渐形成了一套完整的生态系统,即能够提供内存计算架构、也可以支持SQL即席查询、机器学习和图计算等。
4.Spark两类操作
转换:map filter join union sample
动作:first top count collect
第十章(老师说必须会的实验)
Hive部分代码:


Spark常用的方法:
file.filter(line => line.length>10).first().union(file).count()
file.sample(true,0.5).count /随机抽选50%的样本/
















 1047
1047











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











