







一、DeepSeek发生了什么事

2025年1月20日,DeepSeek正式发布DeepSeek-R1,并同步开源模型权重。继1月20日下午DeepSeek的创始人梁文锋参加总理座谈会之后,DeepSeek在全球爆火。
智东西1月27日报道,当日“国产AI之光”DeepSeek把美股“打爆”了。DeepSeek这些天俨然一副“杀疯了”的架势,当日再创历史时刻:力压ChatGPT,登顶美区App Store免费榜,在国内App Store免费榜同样位居第一。
在用V3和R1模型横扫硅谷、引爆全球科技圈后,DeepSeek在除夕这天继续放大招。1月28日凌晨,人工智能社区Hugging Face显示,DeepSeek发布了开源多模态模型Janus-Pro,拥有10亿和70亿参数规模,相比此前的语言和推理模型,本次发布的新模型重点在于文生图能力方面。
根据DeepSeek的技术文档,这个模型既能让AI读图,又能让AI生图。在文生图GenEval和DPG-Bench基准测试中,Janus-Pro-7B的准确率较前代Janus大幅提高,准确率测试结果分别为80%和84.2%,高于包括OpenAI DALL-E 3、Stable Diffusion在内的其他对比模型。
DeepSeek推出性能媲美OpenAI o1模型的推理模型R1,成本仅用了o1的一小部分,而且开源,API付费价格远低于o1,App和网页版均支持免费使用,还支持联网搜索。
开源意味着只要你的电脑配置充足,你就可以用Ollama等应用把最大版本的R1模型下载到电脑本地,充分保护隐私和数据安全。
你也可以把DeepSeek R1 1.5B版本部署到手机,让它在手机本地的Web浏览器上流畅运行。
免费使用意味着在联网状态下,你不用花钱,就能享受ChatGPT付费用户每月花20美元、200美元才能使用的高端模型。
在去年7月接受《暗涌》采访时,DeepSeek创始人梁文锋提到,DeepSeek聚焦于三个核心方向:数学和代码、多模态技术以及自然语言本身。他指出,过去三十多年的IT浪潮中,中国并未深度参与真正的技术创新,但随着经济的持续发展,中国应逐步从“搭便车”的角色转变为技术创新的贡献者。
尽管股市的波动可能是短暂的,且通往通用人工智能(AGI)的路径仍不明确,但DeepSeek R1的出现无疑正在重新定义AI领域的游戏规则。作为中国AI开源力量的代表,DeepSeek的影响力已如蝴蝶效应般在全球科技产业中掀起了一场深远变革的飓风。
二、DeepSeek它是什么
2023年7月,幻方量化宣布成立大模型公司DeepSeek,正式进军通用人工智能领域。背靠国内对冲基金巨头,因开源和低价而闻名,素有“AI界拼多多”、“国产AI价格屠夫”之称。据报道,DeepSeek包括创始人梁文锋在内,仅有139名工程师和研究人员。与之对比,OpenAI有1200名研究人员,Anthropic则有500多名研究人员。DeepSeek模型训练成本仅为560万美元,远低于美国的头部AI公司如openai的数亿美元乃至数十亿美元的成本。
总结关键字:开源、低成本、媲美OpenAI o1模型。
我们先到DeepSeek官网看看。

官网也是毫不谦虚,直接摊牌,可直接对标OpenAI o1正式版,可谓相当霸气。
体验了下,效果还是可以的,甚至能看到清晰的思考过程。
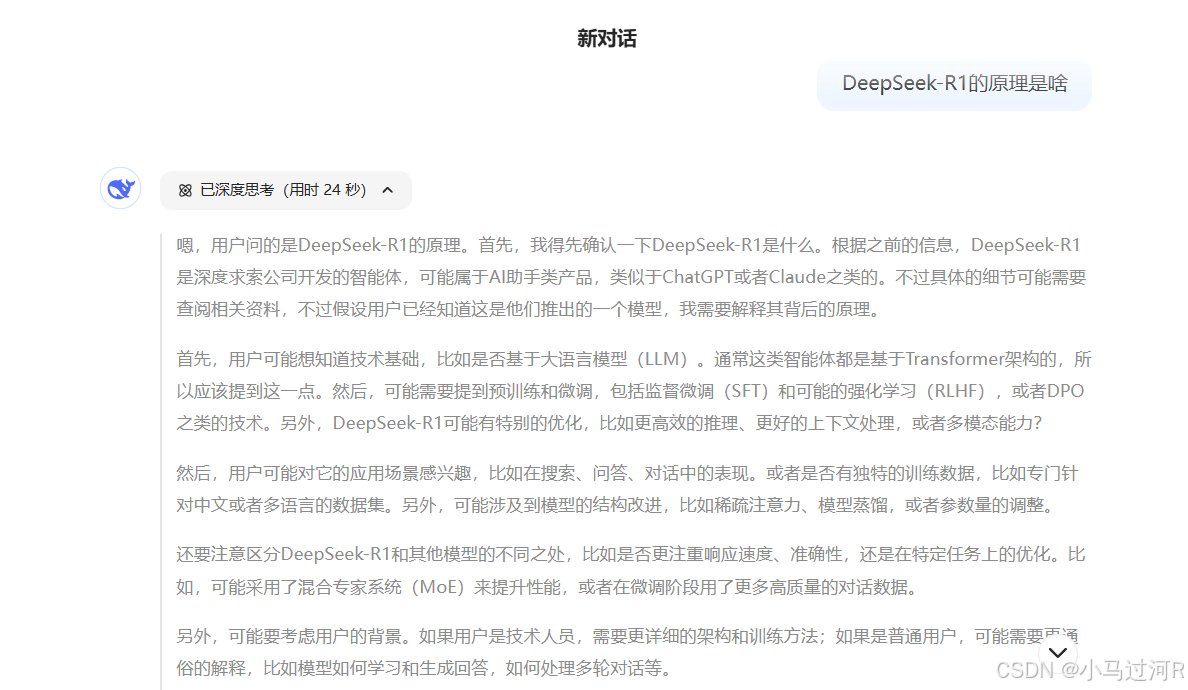
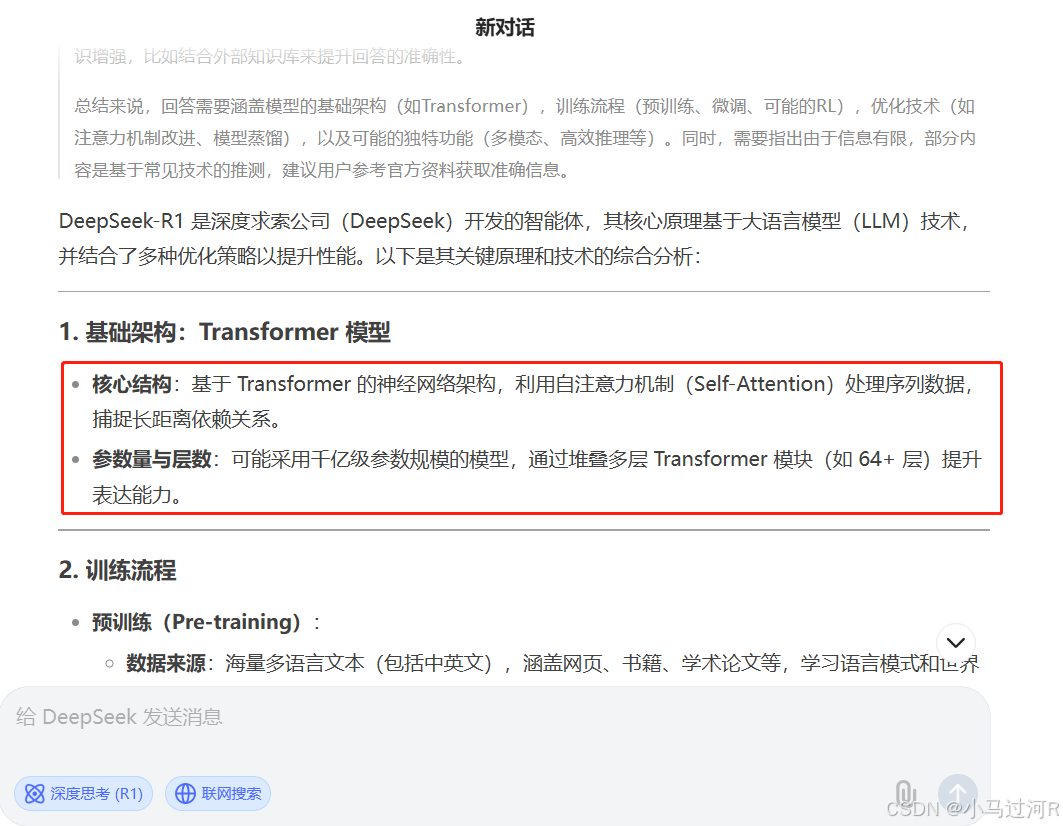
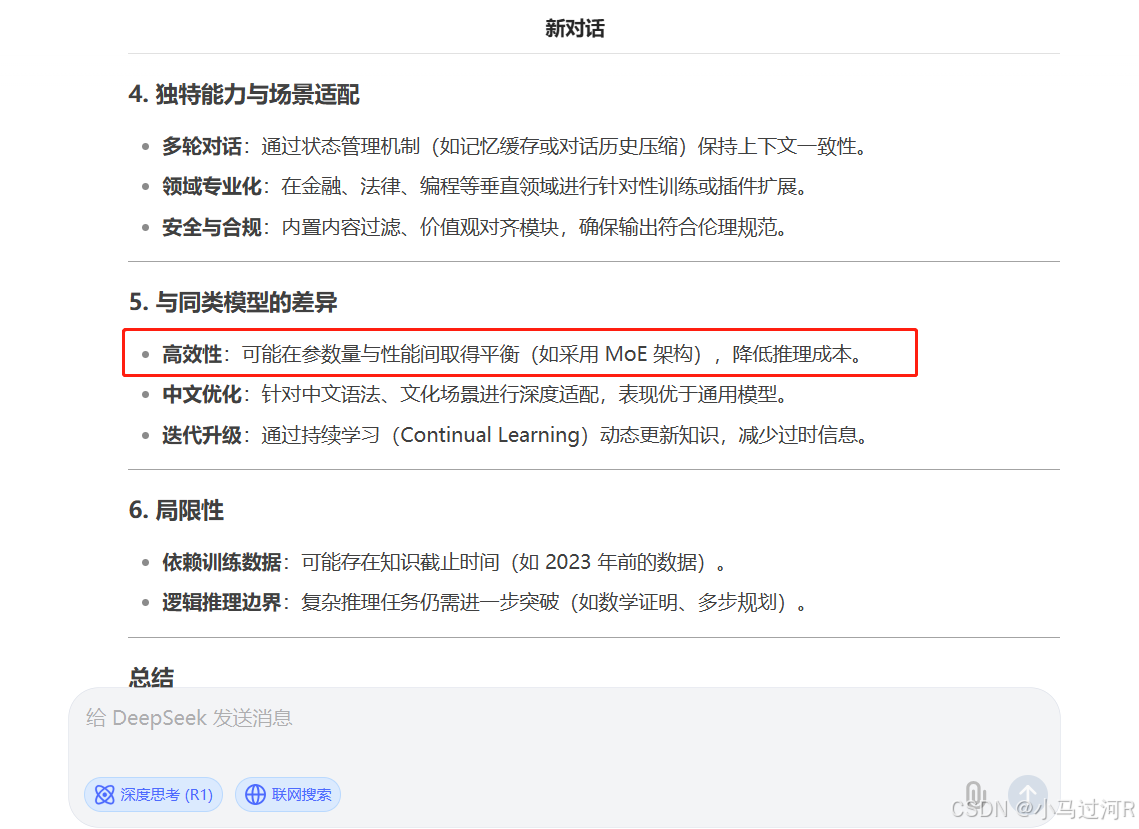
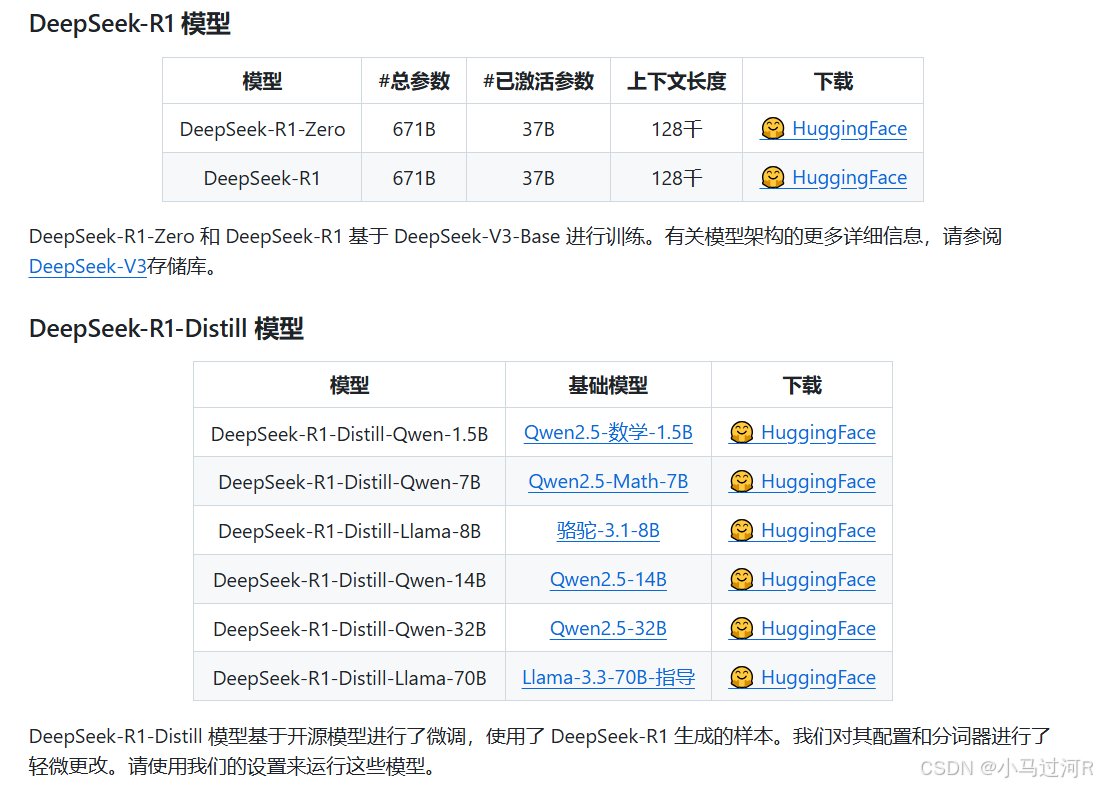
我们还看到多模态模型Janus:统一的多模态理解和生成模型。据说也很能打,可以只能去huggingface体验,性能体验一般。
三、DeepSeek原理
DeepSeek的框架原理与主流大模型技术(如 GPT、LLaMA)相似,但在数据质量、训练策略、工程优化(如长上下文支持)等方面可能有独特设计。
我们直接来看git DeepSeek-R1 readme的介绍。

再看看DeepSeek-V3的介绍。

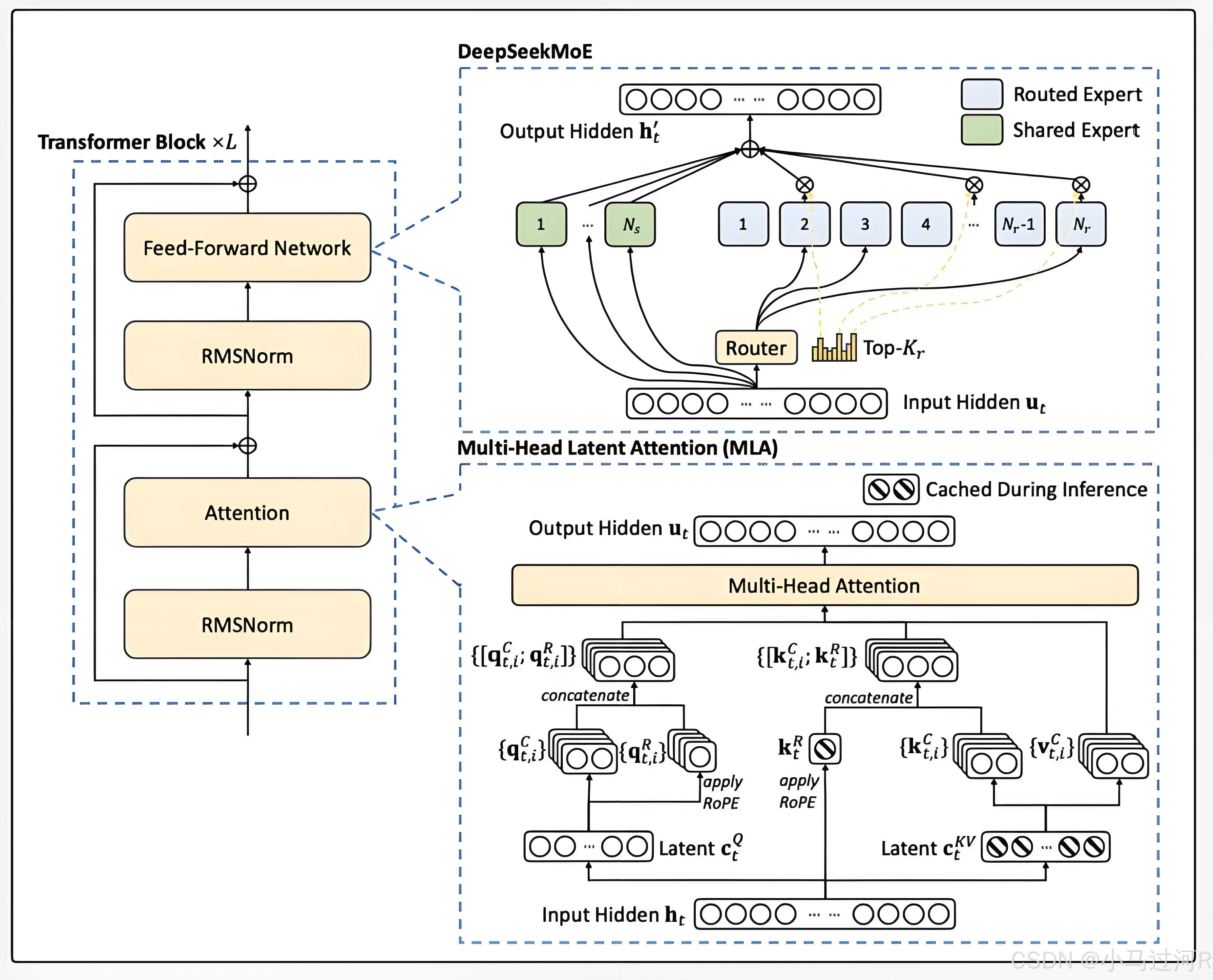
再结合上文的体验对话截图,我们已经大概可以定位出关键词:Transformer、自注意力机制 (Sef-Attention) 、 MOE 架构、持续学习 (Continual Learning) 。
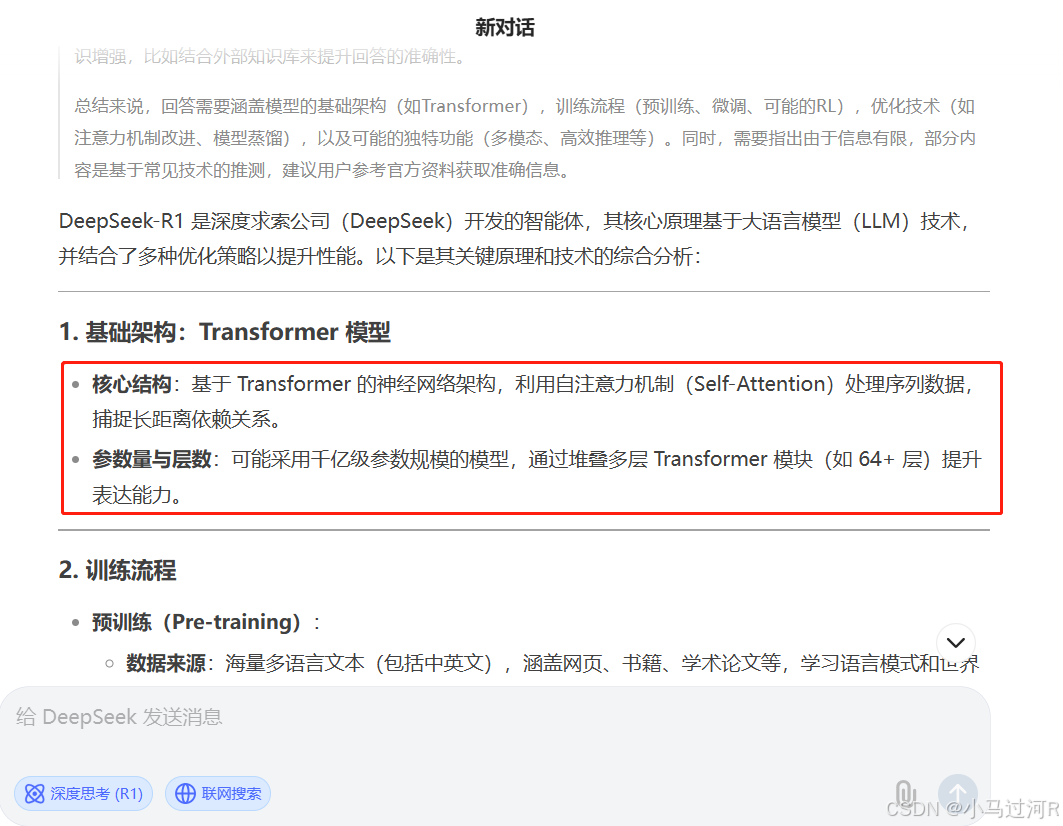
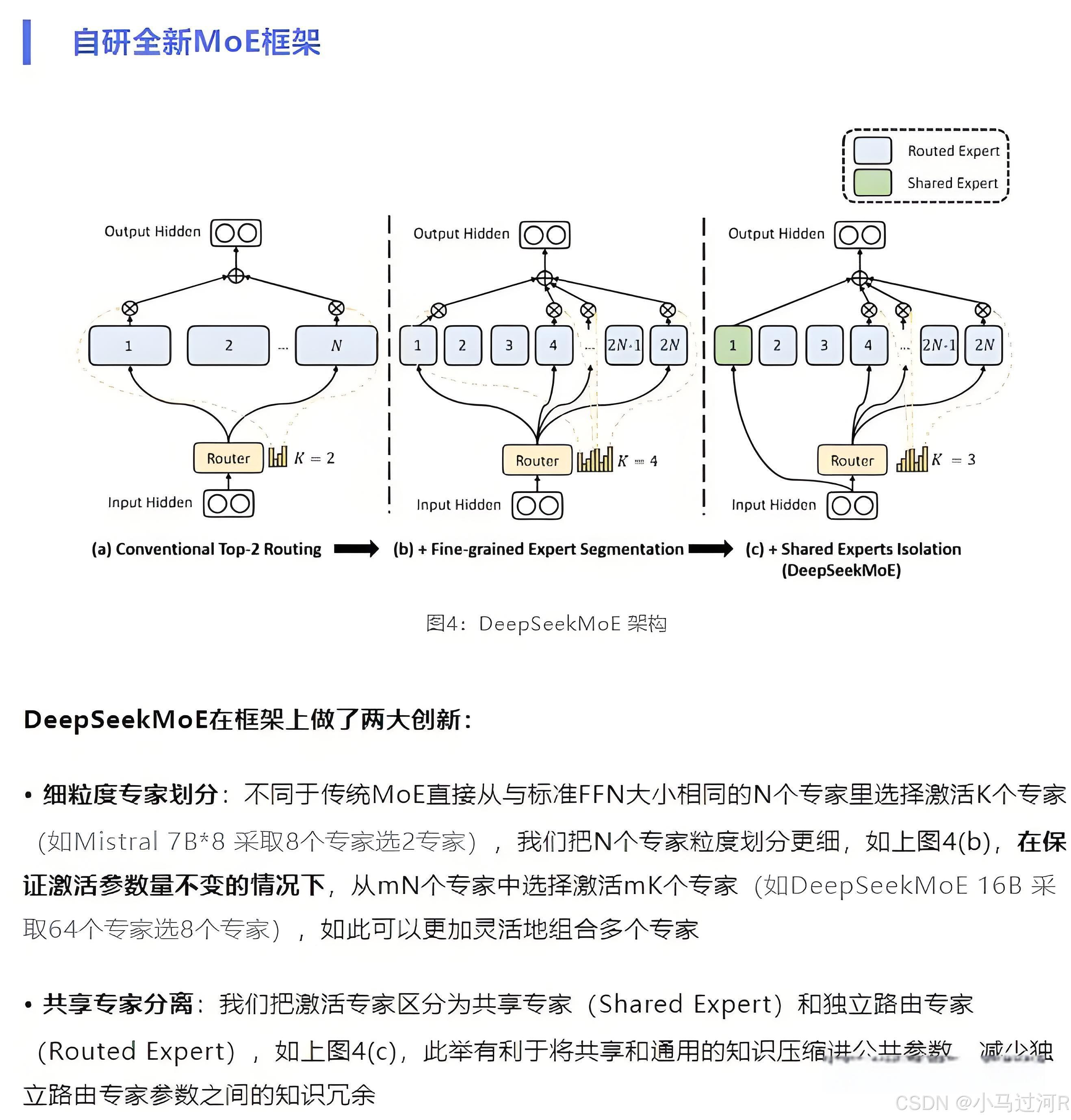
至于更深的底层原理,待小马也持续学习后再来一起和大家分享探讨。
更多AI落地资料还可以参看这里AI应用落地。还有疑问可以来公众号【贝可林】私信我,我骑共享单车到你家探讨。
其他资料:
DeepSeek在美超越ChatGPT问鼎第一,DeepSeek R1复现
- 新年彩蛋~




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











