







小马之所以想写这篇文章是得益于前段时间在0元薅人工智能证书的时候,印象最深的课程达摩院的智能客服系列。小马自己消化总结整理了下分享给大家一起探讨。
之所以在智能客服系统的前面加一个“语音”是为了和之前小马整理过的一些类似RAG之类的智能问答系统区分开,因为这块还包含了人机交互中语音处理的部分。这能解决电商、医疗、咨询等等各个行业大部分的电话客服工作,乃至匹配目前主流智能音箱产品如小爱同学、天猫精灵、Siri等的解决方案。

本文部分内容资料参考自这里《人工智能训练师(高级)》,在此同时感谢原作者分享。
一、语音智能客服的整体架构组成
先来看系统的整体架构图。
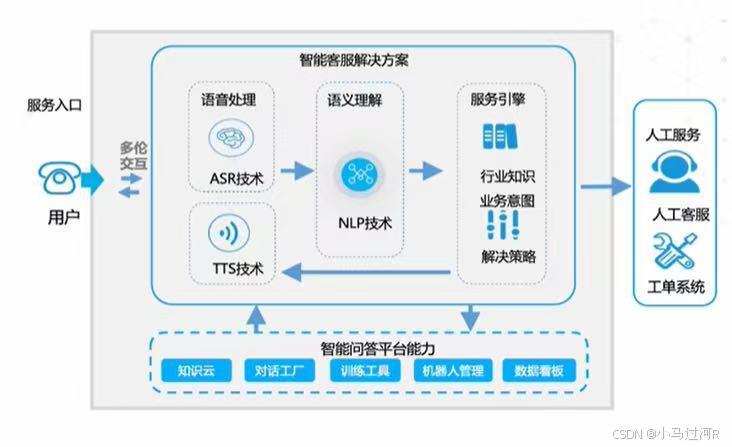
我们可以看到,整个系统由三大部分组成:ASR + TTS。
整体处理流程如下:
ASR接收语音输入,并使用AM声学模型将语音识别成文字;
LLM模型负责文本生生成,两者模型之间使用词典建立联系;
TTS负责将文本转为语音输出,遵循SSML规范。
架构总结为:
🐱🏍ASR (语音转文字) = AM声学模型(语音识别成文字,深度神经网络算法对各种声学现象的训练) + LM语言模型(文本生成) + 词典(两模型建立联系)
🤳TTS (文本转语音)= 文本转语音模型 + SSML规范
当然这里只列出了大体的组成部分,还存在着诸多细节,比如RAG,NLP等等的处理,待我们一步一步去补充。
二、自动语音识别ASR
1、ASR是什么
自动语音识别(Automatic Speech Recognition, ASR) 是一种将人类语音实时或离线转换为计算机可读文本的技术,属于人工智能和自然语言处理(NLP)的核心领域。 其核心目标是实现人机交互的无缝衔接,通过算法模型解析语音信号,生成准确的文字输出。
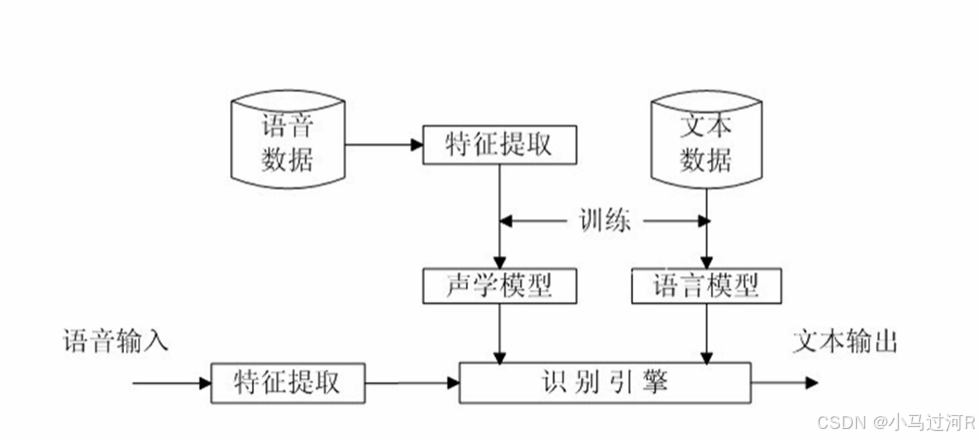
2、ASR核心功能与技术原理
功能定义
输入:语音/音频信号;输出:结构化文本。
支持场景:实时字幕生成、语音输入法、智能助手交互(如 Siri、Alexa)。
技术实现
ASR 系统通常依赖以下模块协同工作:
声学模型:分析语音信号与音素(语音单位)的关联,将音频转化为音素序列。
语言模型:结合上下文预测可能的词汇组合,解决同音词、口语化表达等问题。
深度学习框架:基于 RNN、Transformer 等模型提升识别精度,尤其在噪声环境或复杂语境下。


既然ASR系统是基于算法和概率的,声音转文字就不可能达到100%正确。字准率成为了业界ASR唯一评价指标。

3、ASR的核心流程
自动语音识别(ASR)通过多阶段算法将语音信号转化为文本,以下是其典型流程及关键技术模块:
- 输入与预处理阶段
语音信号接收:通过麦克风等设备采集模拟语音信号,并转换为数字信号(采样率通常为16kHz)。
降噪与滤波:消除环境噪声(如风声、设备底噪)和干扰频率,增强语音清晰度。
端点检测:定位有效语音段的起始与结束点,剔除静音段以提升处理效率。
分帧与加窗:将连续语音切分为20-40ms的短帧(每帧间隔10ms),并通过汉明窗等函数减少截断效应。 - 特征提取
声学特征提取:
MFCC(梅尔频率倒谱系数):模拟人耳听觉特性,通过傅里叶变换、梅尔滤波器组和对数能量计算生成13-40维特征向量。
FBank(滤波器组特征):简化MFCC的计算流程,保留语音频谱的局部特性。
特征补偿:对特征进行归一化处理(如CMVN),减少说话人差异和设备影响。 - 声学模型处理
概率映射:通过深度神经网络(DNN、RNN、Transformer)或混合模型(HMM-DNN)计算语音帧与音素/字符的对应概率。
时序建模:使用WaveNet等模型捕捉长时语音依赖关系,通过因果空洞卷积扩大感受野。 - 语言模型解码
上下文预测:基于统计语言模型(如N-gram)或神经网络语言模型(如BERT),结合语法规则和语义信息,修正同音词错误并优化文本连贯性。
解码器协同:联合声学模型输出与语言模型概率,通过加权有限状态转换器(WFST)或集束搜索(Beam Search)生成最优文本序列。 - 输出优化
CTC(连接时序分类):处理语音与文本长度不一致问题,通过动态规划对齐序列并输出最终文本。
后处理:对识别结果进行标点插入、大小写修正及领域术语校准(如医疗、法律场景)。
技术演进与优化方向
端到端模型:基于Transformer的模型(如Conformer)直接映射语音到文本,简化传统多模块流程。
多模态融合:结合唇动、表情等视觉信息提升噪声环境下的识别鲁棒性。
以上流程通过声学与语言模型的联合优化,实现高精度语音转文本,支撑智能助手、实时翻译等广泛应用。
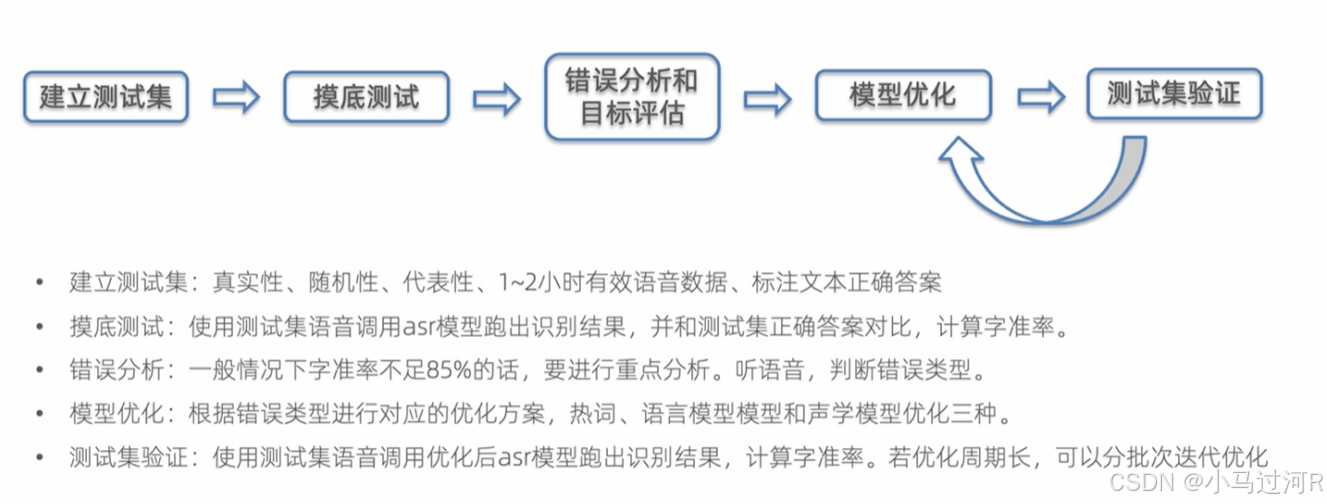
模型优化中,特别针对垂直领域的术语转换(同音多词)需要特别处理,语言模型定制后才能拥有更高的准确率。
那么问题来了,中国的方言很多,假设要实现一个针对方言的智能语音识别系统,模型应该如何处理呢?
先到这了,下马要吃中饭去了,下一篇我们来继续讲TTS和NLP。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











