






本文全部代码均已上传github,源码地址为:
https://github.com/xixingya/dubbo-demo
第一章 spi 基础
SPI 全称为 Service Provider Interface,是一种服务发现机制。SPI 的本质是将接口实现类的全限定名配置在文件中,并由服务加载器读取配置文件,加载实现类。这样可以在运行时,动态为接口替换实现类。正因此特性,我们可以很容易的通过 SPI 机制为我们的程序提供拓展功能。SPI 机制在第三方框架中也有所应用,比如 Dubbo 就是通过 SPI 机制加载所有的组件。不过,Dubbo 并未使用 Java 原生的 SPI 机制,而是对其进行了增强,使其能够更好的满足需求。在 Dubbo 中,SPI 是一个非常重要的模块。基于 SPI,我们可以很容易的对 Dubbo 进行拓展。如果大家想要学习 Dubbo 的源码,SPI 机制务必弄懂。接下来,我们先来了解一下 Java SPI 与 Dubbo SPI 的用法,然后再来分析 Dubbo SPI 的源码。
1.1 java spi
一句话来概括我们的java spi,Java SPI 实际上是“基于接口的编程+策略模式+配置文件”组合实现的动态加载机制。
1.1.1 概念
Java SPI 实际上是“基于接口的编程+策略模式+配置文件”组合实现的动态加载机制。
系统设计的各个抽象,往往有很多不同的实现方案,在面向的对象的设计里,一般推荐模块之间基于接口编程,模块之间不对实现类进行硬编码。一旦代码里涉及具体的实现类,就违反了可拔插的原则,如果需要替换一种实现,就需要修改代码。为了实现在模块装配的时候能不在程序里动态指明,这就需要一种服务发现机制。
Java SPI就是提供这样的一个机制:为某个接口寻找服务实现的机制。有点类似IOC的思想,就是将装配的控制权移到程序之外,在模块化设计中这个机制尤其重要。所以SPI的核心思想就是解耦。
1.1.2 使用场景
概括地说,适用于:调用者根据实际使用需要,启用、扩展、或者替换框架的实现策略
比较常见的例子:
- 数据库驱动加载接口实现类的加载
JDBC加载不同类型数据库的驱动
- 日志门面接口实现类加载
SLF4J加载不同提供商的日志实现类
- Spring
Spring中大量使用了SPI,比如:对servlet3.0规范对ServletContainerInitializer的实现、自动类型转换Type Conversion SPI(Converter SPI、Formatter SPI)等
- Dubbo
Dubbo中也大量使用SPI的方式实现框架的扩展, 不过它对Java提供的原生SPI做了封装,允许用户扩展实现Filter接口
1.1.3 show code
首先我们来看java spi的机制:话不多说,我们直接看代码
public interface Log {
void log(String log);
void logAdaptive(URL url,String log);
}
public class Log4j implements Log {
@Override
public void log(String log) {
System.out.println("log4j print " + log + " this is " + this);
}
@Override
public void logAdaptive(URL url, String log) {
System.out.println("logAdaptive log4j print " + log + " this is " + this);
}
}
public class Logback implements Log {
@Override
public void log(String log) {
System.out.println("Logback print " + log +" this is "+ this);
}
@Override
public void logAdaptive(URL url,String log) {
System.out.println("logAdaptive Logback print " + log +" this is "+ this);
}
}
我们运行TestSpi,得到以下结果:
public class TestSpi {
public static void main(String[] args) {
// ServiceLoader<Log> serviceLoader = ServiceLoader.load(Log.class);
for (int i = 0; i < 3; i++) {
ServiceLoader<Log> serviceLoader = ServiceLoader.load(Log.class);
for (Log next : serviceLoader) {
next.log("hello world");
}
}
}
}
/**
log4j print hello world this is tech.xixing.dubbo.demo.spi.java.Log4j@4c873330
Logback print hello world this is tech.xixing.dubbo.demo.spi.java.Logback@119d7047
log4j print hello world this is tech.xixing.dubbo.demo.spi.java.Log4j@776ec8df
Logback print hello world this is tech.xixing.dubbo.demo.spi.java.Logback@4eec7777
log4j print hello world this is tech.xixing.dubbo.demo.spi.java.Log4j@3b07d329
Logback print hello world this is tech.xixing.dubbo.demo.spi.java.Logback@41629346
**/
我们对比最后的数字,可以发现每次获取到的对象都是新的。说明java spi每次获取都是重新去new出来的对象。没有缓存。
1.1.4 深入源码
下面我们看源码,看是否是这样子的:
可以看到ServiceLoader中有个这个类,java.util.ServiceLoader.LazyIterator,我们在初始化的时候,会初始化这个类,这个类实现了Iterator接口。
在每次for调用的时候,会调用next(),而next,会先判断hasNextService,在hasNextService中,就会去判断config,这个config就是从resource中获取的。
即:for (Log next : serviceLoader) 这个代码,next变量是从next()方法获取的。
所以我们获取到了这个实例的代码是在
private class LazyIterator
implements Iterator<S>
{
Class<S> service;
ClassLoader loader;
Enumeration<URL> configs = null;
// 等待被加载的类名。
Iterator<String> pending = null;
// 下一个被加载的类名。
String nextName = null;
private LazyIterator(Class<S> service, ClassLoader loader) {
this.service = service;
this.loader = loader;
}
private boolean hasNextService() {
if (nextName != null) {
return true;
}
if (configs == null) {
try {
String fullName = PREFIX + service.getName();
if (loader == null)
configs = ClassLoader.getSystemResources(fullName);
else
configs = loader.getResources(fullName);
} catch (IOException x) {
fail(service, "Error locating configuration files", x);
}
}
while ((pending == null) || !pending.hasNext()) {
if (!configs.hasMoreElements()) {
return false;
}
// 这里读取文件获取的
pending = parse(service, configs.nextElement());
}
nextName = pending.next();
return true;
}
private S nextService() {
if (!hasNextService())
throw new NoSuchElementException();
String cn = nextName;
nextName = null;
Class<?> c = null;
try {
c = Class.forName(cn, false, loader);
} catch (ClassNotFoundException x) {
fail(service,
"Provider " + cn + " not found");
}
if (!service.isAssignableFrom(c)) {
fail(service,
"Provider " + cn + " not a subtype");
}
try {
S p = service.cast(c.newInstance());
providers.put(cn, p);
return p;
} catch (Throwable x) {
fail(service,
"Provider " + cn + " could not be instantiated",
x);
}
throw new Error(); // This cannot happen
}
public boolean hasNext() {
if (acc == null) {
return hasNextService();
} else {
PrivilegedAction<Boolean> action = new PrivilegedAction<Boolean>() {
public Boolean run() { return hasNextService(); }
};
return AccessController.doPrivileged(action, acc);
}
}
public S next() {
if (acc == null) {
return nextService();
} else {
PrivilegedAction<S> action = new PrivilegedAction<S>() {
public S run() { return nextService(); }
};
return AccessController.doPrivileged(action, acc);
}
}
public void remove() {
throw new UnsupportedOperationException();
}
}
1.2 dubbo spi
我们借用官网的话语来解答dubbo spi是什么
什么是可扩展性
可扩展性是一种设计理念,代表了我们对未来的一种预想,我们希望在现有的架构或设计基础上,当未来某些方面发生变化的时候,我们能够以最小的改动来适应这种变化。
可扩展性的优点
可扩展性的优点主要表现模块之间解耦,它符合开闭原则,对扩展开放,对修改关闭。当系统增加新功能时,不需要对现有系统的结构和代码进行修改,仅仅新增一个扩展即可。
扩展实现方式
一般来说,系统会采用 Factory、IoC、OSGI 等方式管理扩展(插件)生命周期。考虑到 Dubbo 的适用面,不想强依赖 Spring 等 IoC 容器。 而自己造一个小的 IoC 容器,也觉得有点过度设计,所以选择最简单的 Factory 方式管理扩展(插件)。在 Dubbo 中,所有内部实现和第三方实现都是平等的。
Dubbo 中的可扩展性
- 平等对待第三方的实现。在 Dubbo 中,所有内部实现和第三方实现都是平等的,用户可以基于自身业务需求,替换 Dubbo 提供的原生实现。
- 每个扩展点只封装一个变化因子,最大化复用。每个扩展点的实现者,往往都只是关心一件事。如果用户有需求需要进行扩展,那么只需要对其关注的扩展点进行扩展就好,极大的减少用户的工作量。
Dubbo 中的扩展能力是从 JDK 标准的 SPI 扩展点发现机制加强而来,它改进了 JDK 标准的 SPI 以下问题:
- JDK 标准的 SPI 会一次性实例化扩展点所有实现,如果有扩展实现初始化很耗时,但如果没用上也加载,会很浪费资源。
- 如果扩展点加载失败,连扩展点的名称都拿不到了。比如:JDK 标准的 ScriptEngine,通过 getName() 获取脚本类型的名称,但如果 RubyScriptEngine 因为所依赖的 jruby.jar 不存在,导致 RubyScriptEngine 类加载失败,这个失败原因被吃掉了,和 ruby 对应不起来,当用户执行 ruby 脚本时,会报不支持 ruby,而不是真正失败的原因。
下面带大家实现一个简单的dubbo spi的demo
@SPI("logback")
public interface Log {
void log(String log);
@Adaptive(value = "log")
void logAdaptive(URL url,String log);
}
public class Logback implements Log {
@Override
public void log(String log) {
System.out.println("Logback print " + log +" this is "+ this);
}
@Override
public void logAdaptive(URL url,String log) {
System.out.println("logAdaptive Logback print " + log +" this is "+ this);
}
}
public class Log4j implements Log {
@Override
public void log(String log) {
System.out.println("log4j print " + log + " this is " + this);
}
@Override
public void logAdaptive(URL url, String log) {
System.out.println("logAdaptive log4j print " + log + " this is " + this);
}
}
public class TestSpiDubbo {
public static void main(String[] args) {
for (int i = 0; i < 3; i++) {
ExtensionLoader<Log> extensionLoader = ExtensionLoader.getExtensionLoader(Log.class);
extensionLoader.getExtension("logback").log("hello world");
//extensionLoader.getExtension("log4j").log("hello world");
extensionLoader.getExtension("log4j").log("hello world");
//extensionLoader.getExtension("mylog").log("hello world");
}
}
}
在resource目录下建立接口全类名的文件:
第二章 dubbo spi全功能解析
在dubbo spi中存在以下功能点:
用户能够基于 Dubbo 提供的扩展能力,很方便基于自身需求扩展其他协议、过滤器、路由等。下面介绍下 Dubbo 扩展能力的特性。
- 按需加载。Dubbo 的扩展能力不会一次性实例化所有实现,而是用扩展类实例化,减少资源浪费。
- 增加扩展类的 IOC 能力。Dubbo 的扩展能力并不仅仅只是发现扩展服务实现类,而是在此基础上更进一步,如果该扩展类的属性依赖其他对象,则 Dubbo 会自动的完成该依赖对象的注入功能。
- 增加扩展类的 AOP 能力。Dubbo 扩展能力会自动的发现扩展类的包装类,完成包装类的构造,增强扩展类的功能。
- 具备动态选择扩展实现的能力。Dubbo 扩展会基于参数,在运行时动态选择对应的扩展类,提高了 Dubbo 的扩展能力。
- 可以对扩展实现进行排序。能够基于用户需求,指定扩展实现的执行顺序。
- 提供扩展点的 Adaptive 能力。该能力可以使的一些扩展类在 consumer 端生效,一些扩展类在 provider 端生效。也可以调整拓展的生效顺序等等。
从 Dubbo 扩展的设计目标可以看出,Dubbo 实现的一些例如动态选择扩展实现、IOC、AOP 等特性,能够为用户提供非常灵活的扩展能力。
2.1 defaultExtension @SPI
下面我们来进行探讨,dubbo spi获取默认的ext的时候,进行了哪些步骤。
我们写入以下代码:
@Test
void testDefaultExt(){
for (int i = 0; i < 3; i++) {
ExtensionLoader<Log> extensionLoader = ExtensionLoader.getExtensionLoader(Log.class);
extensionLoader.getDefaultExtension().log("hello world");
}
}
我们发现,获取到的loader会去加载默认写到@SPI的注解上的value值。
我们简单看下是如何从@SPI中获取默认的ext的。
private void cacheDefaultExtensionName() {
final SPI defaultAnnotation = type.getAnnotation(SPI.class);
if (defaultAnnotation == null) {
return;
}
String value = defaultAnnotation.value();
if ((value = value.trim()).length() > 0) {
String[] names = NAME_SEPARATOR.split(value);
if (names.length > 1) {
throw new IllegalStateException(
"More than 1 default extension name on extension " + type.getName() + ": " + Arrays.toString(
names));
}
if (names.length == 1) {
cachedDefaultName = names[0];
}
}
}
上述代码cachedDefaultName,会在获取默认的loader的时候使用。
ok,如果想要具体看代码分析,可以看第三章的代码分析章节对应的代码分析。
2.2 Adaptive
接下来我们来介绍一下我们的重头戏,也是我们dubbo中最广泛使用的Adaptive。
看名字我们也能大概猜出一部分它的含义,Adaptive,即为自适应。那么什么叫自适应呢。dubbo是如何使用的呢。
下面我们先来看看一个例子,结合例子来看如何实现的:
在方法上
@Adaptive标注一般标注在接口的方法上,也可以标注在类,枚举类,方法上,但是比较少见,@Adaptive标注在接口方法上时,要求接口方法入参中有一个URL,这个URL类是org.apache.dubbo.common.URL**,**注解的功能是可以根据方法中URL的入参,来选择对哪一个实现进行调用,使用如下:
- 首先给interface加上入参,然后给接口方法加上@adaptive注解,设置value的默认值是“log”
@SPI("logback")
public interface Log {
void log(String log);
@Adaptive(value = "log")
void logAdaptive(URL url,String log);
}
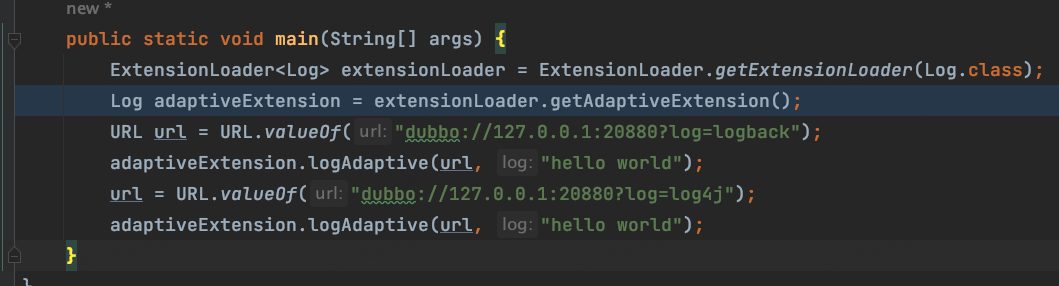
然后我们看main函数
public static void main(String[] args) {
ExtensionLoader<Log> extensionLoader = ExtensionLoader.getExtensionLoader(Log.class);
Log adaptiveExtension = extensionLoader.getAdaptiveExtension();
URL url = URL.valueOf("dubbo://127.0.0.1:20880?log=logback");
adaptiveExtension.logAdaptive(url,"hello world");
url = URL.valueOf("dubbo://127.0.0.1:20880?log=log4j");
adaptiveExtension.logAdaptive(url,"hello world");
}
跑完结果如下:

那我们明白了它的第一种用法。adaptive,即通过字段名称来调用不同的实现类的方法。
在类上
事实上,如果作用在类上,那么其实就没有什么特殊的逻辑了,即作用在类上代表着,这个接口获取的Adaptive类都会是你标注的那个类。即,你自己会在标注Adaptive的类上去实现自己的转发策略。
请看例子:
@SPI
public interface Service {
void sayHello(URL url);
}
@Adaptive
public class CommonService implements Service {
@Override
public void sayHello(URL url) {
ExtensionLoader<Service> extensionLoader = ExtensionLoader.getExtensionLoader(Service.class);
if (url.getParameter("service").equals("common2")) {
Service common2 = extensionLoader.getExtension("common2");
common2.sayHello(url);
} else {
Service common3 = extensionLoader.getExtension("common3");
common3.sayHello(url);
}
System.out.println("hello CommonService");
}
}
public class Common2Service implements Service {
@Override
public void sayHello(URL url) {
System.out.println("hello Common2Service");
}
}
public class Common3Service implements Service{
@Override
public void sayHello(URL url) {
System.out.println("hello Common3Service");
}
}
@Test
public void test2() {
ExtensionLoader<Service> extensionLoader = ExtensionLoader.getExtensionLoader(Service.class);
Service adaptiveExtension = extensionLoader.getAdaptiveExtension();
URL url = URL.valueOf("dubbo://127.0.0.1:20880?service=common3");
adaptiveExtension.sayHello(url);
}
通过上述例子,你应该可以理解,Adaptive在类上注解是什么意思了吧。这里commonService代理了Common2和Common3,通过写自己的逻辑,去手动调用common2或者common3的逻辑。
2.3 自动注入
自动注入,相信大家搞java的都用过spring的自动注入,一个注解,或者通过构造器、set方法自动注入。
OK,下面我们来讲dubbo spi的这一个特性,dubbo spi同样支持对Adaptive的类进行自动注入。下面我们看一个例子:
@Activate(group = "my",order = 1)
public class MyLog implements Log {
private Service service;
public void setService(Service service) {
this.service = service;
}
@Override
public void log(String log) {
System.out.println("my log:"+log);
URL url = URL.valueOf("test://localhost/test?service=common");
service.sayHello(url);
}
@Override
public void logAdaptive(URL url, String log) {
System.out.println("my log logAdaptive:"+log);
}
}
// 测试用例
public static void main(String[] args) {
URL url = URL.valueOf("dubbo://127.0.0.1:20880");
ExtensionLoader<Log> extensionLoader = ExtensionLoader.getExtensionLoader(Log.class);
List<Log> activateExtensions = extensionLoader.getActivateExtension(url, new String[]{}, "my");
for (Log activateExtension : activateExtensions) {
activateExtension.log("hello world");
}
}
之前我们把这个Service类的Adaptive给了CommonService,所以,我们这里加上set方法,我们可以在另外一个被SPI托管的类中直接使用这个类。这有点类似于我们spring中的set方法注入。
我们也可以通过debug看下是不是这样子的。
可以看到确实是这样子的。大家也可以去尝试一下,相关代码都会放在github上。
ok。这里我们给大家一个思考,如果dubbo中,Service接口只有CommonService这一个实现类,那这个注入还能成功吗?为什么?
2.3 Wrapper
ok,接下来我们来讲一下dubbo spi的另一个重头戏,wrapper机制。听到wrapper机制,想必大家都知道一种设计模型是装饰器模式吧。
同样的,如果我们需要对某个spi接口进行增强,我们就可以通过wrapper机制对其进行一个包装,比如说做一些日志啊。打点啊等等。
ok, show code:
public class LogWrapper implements Log {
private Log logger;
public LogWrapper(Log log) {
this.logger = log;
}
@Override
public void log(String log) {
System.out.println("fdsfsdfdsfs");
logger.log(log+"wrapper");
System.out.println("aaa");
}
@Override
public void logAdaptive(URL url, String log) {
logger.log(log+"wrapper");
}
}
public class WrapperTest {
public static void main(String[] args) {
ExtensionLoader<Log> extensionLoader = ExtensionLoader.getExtensionLoader(Log.class);
Log logback = extensionLoader.getExtension("logback");
logback.log("hello world");
Log log4j = extensionLoader.getExtension("log4j");
log4j.log("hello world");
}
}
2.5 Activate
第一个字段 group
在dubbo中,这个注解用的最多的地方就是在各种filter中,使用该注解,定义该注解的作用范围是consumer还是provider
下面我们来看一个例子:
public static void main(String[] args) {
URL url = URL.valueOf("dubbo://127.0.0.1:20880");
ExtensionLoader<Log> extensionLoader = ExtensionLoader.getExtensionLoader(Log.class);
List<Log> activateExtensions = extensionLoader.getActivateExtension(url, new String[]{}, "my");
for (Log activateExtension : activateExtensions) {
activateExtension.log("hello world");
}
}



第二个字段 order
order用来在获取到的类中,进行排序。大家可以修改一下order,再启动一个main方法,可以看出不一样的顺序来。下面我们看一个例子。我把mylog、logback、log4j的order分别改成了1,3,6。
下面我们看main函数执行后他们的顺序:
public static void main(String[] args) {
URL url = URL.valueOf("dubbo://127.0.0.1:20880");
ExtensionLoader<Log> extensionLoader = ExtensionLoader.getExtensionLoader(Log.class);
List<Log> activateExtensions = extensionLoader.getActivateExtension(url, new String[]{},"my");
for (Log activateExtension : activateExtensions) {
activateExtension.log("hello world");
}
}

可以看出,order越小,其越先执行。读者们也可自行实验。
第三章 dubbo spi全代码解析(未完待续)
3.1 @SPI
下面我们来进行探讨,dubbo spi获取默认的ext的时候,进行了哪些步骤。
我们写入以下代码:
@Test
void testDefaultExt(){
for (int i = 0; i < 3; i++) {
ExtensionLoader<Log> extensionLoader = ExtensionLoader.getExtensionLoader(Log.class);
extensionLoader.getDefaultExtension().log("hello world");
}
}
首先入口:
public T getDefaultExtension() {
getExtensionClasses();
if (StringUtils.isBlank(cachedDefaultName) || "true".equals(cachedDefaultName)) {
return null;
}
return getExtension(cachedDefaultName);
}
可以看到,是获取cachedDefaultName,然后就调用通用的getExtension了。
那么cachedDefaultName是怎么赋值的呢?
我们接下来看代码:
首先我们进getExtensionClasses,也就是刚刚代码的第二行。
然后getExtensionClasses里面有调用loadExtensionClasses,
再进入loadExtensionClasses里面,则可以看到,cacheDefaultExtensionName这个方法中,通过spi的注解获取到了默认的名称。
下面我们看它是怎么实现的:
private void cacheDefaultExtensionName() {
// 从interface中获取SPI这个注解。
final SPI defaultAnnotation = type.getAnnotation(SPI.class);
if (defaultAnnotation == null) {
return;
}
String value = defaultAnnotation.value();
if ((value = value.trim()).length() > 0) {
String[] names = NAME_SEPARATOR.split(value);
// 不支持多个default name
if (names.length > 1) {
throw new IllegalStateException("More than 1 default extension name on extension " + type.getName()
+ ": " + Arrays.toString(names));
}
if (names.length == 1) {
cachedDefaultName = names[0];
}
}
}
接下来我们继续我们的代码之旅,我们现在cachedDefaultName已经变成了SPI中的value。
我们回到上一层: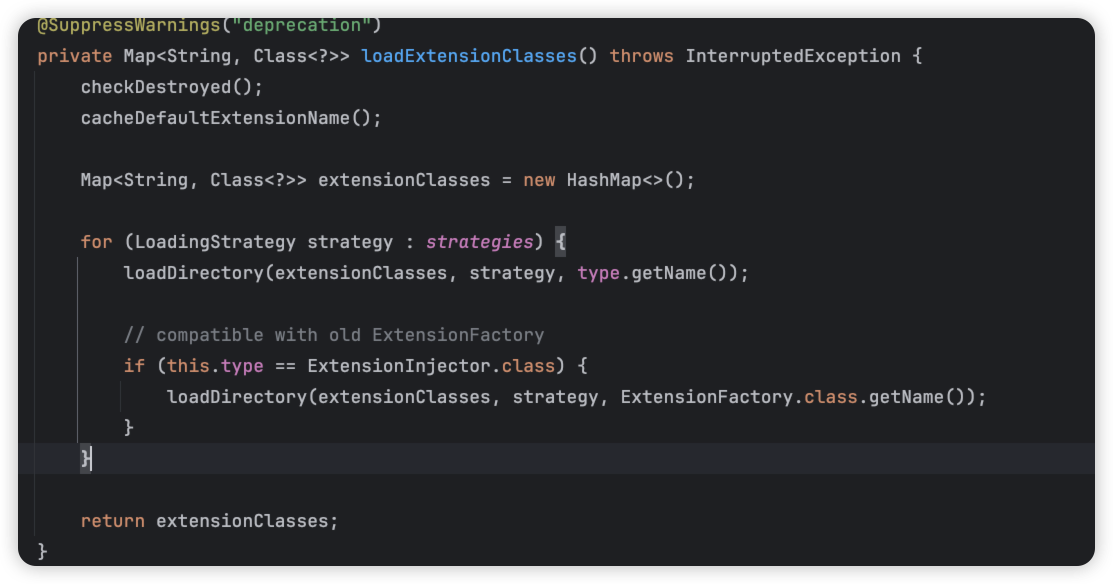
ok,我们直接看这个strategies,这个是dubbo的spi的加载策略
strategies
我们首先看,strategies是在哪里加载的呢,仔细一看,可以发现:

进入方法看:

该方法有两个值得注意的地方,一个是load方法,一个是sorted。
首先我们看load方法,该方法实际上是通过java spi的机制去加载所有的策略。
那么,所有加载的类我们可以在resource下面找到,即以下三个类。
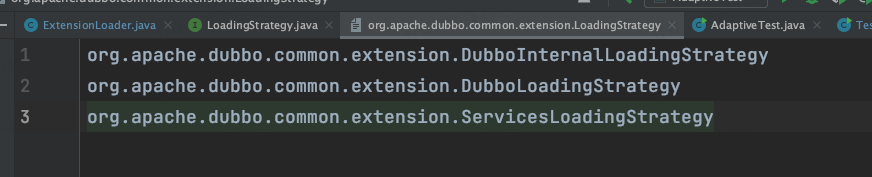
那么我们首先看下接口

发现接口继承了这个Prioritized,而Prioritized这个接口继承了Comparable,并且实现了compareTo方法,那么我们知道了sorted的方法的作用,是在load完之后排序。
通过compareTo方法我们可以看出是通过getPriority方法来的,getPriority越大则排在前面,即先加载,我们看各个实现类的getPriority方法,可以得出以下加载顺序:
| 目录 | 是否可以被后面覆盖 | 加载顺序 |
|---|---|---|
| META-INF/dubbo/internal/ | 不能被覆盖 | 最先加载 |
| META-INF/dubbo/ | 可以被覆盖 | 第二加载 |
| META-INF/services/ | 可以被覆盖 | 最后加载 |
ok,我们回到之前的代码,我们遍历调用strategies里面,
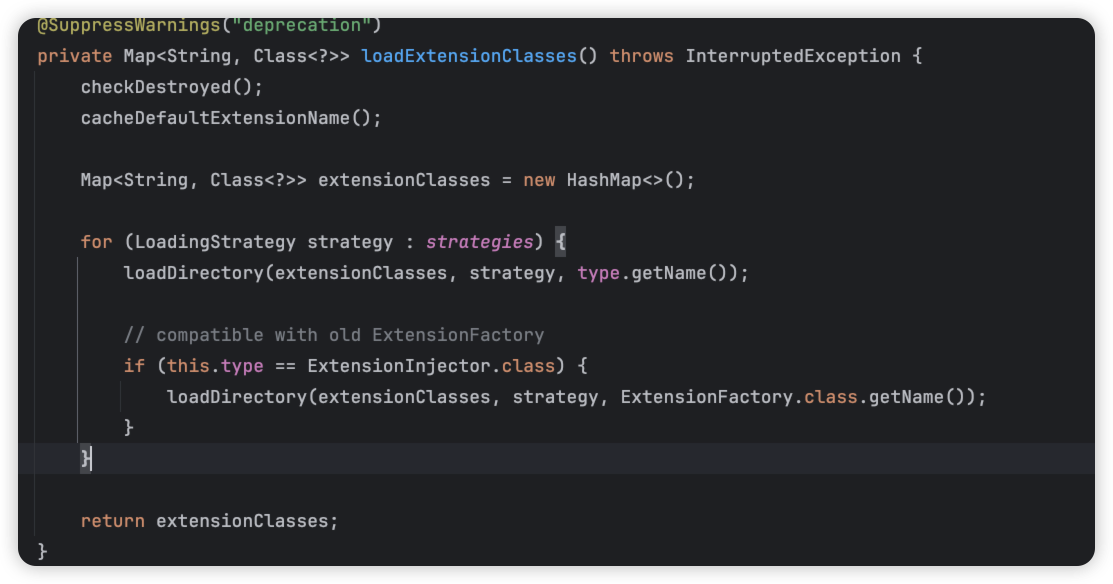
这里,有loadDirectory方法,这里是真正去获取文件然后加载解析的逻辑。
ok,进去loadDirectory后,我们直捣黄龙,看loadDirectoryInternal方法。
跳过获取文件解析文件的繁琐逻辑,我们看核心代码:
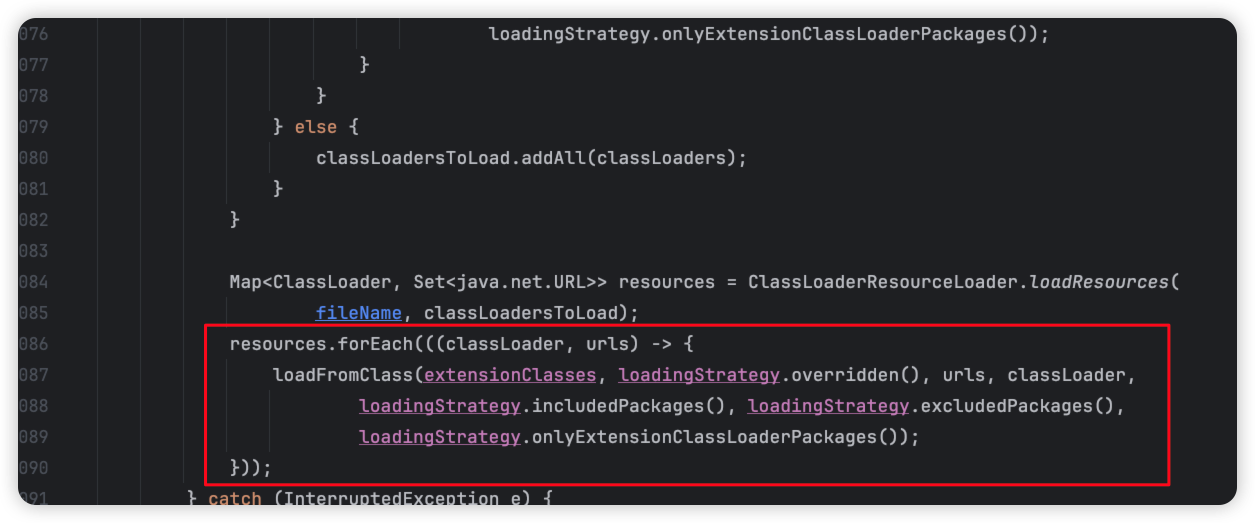
可以看到调用了loadFromClass
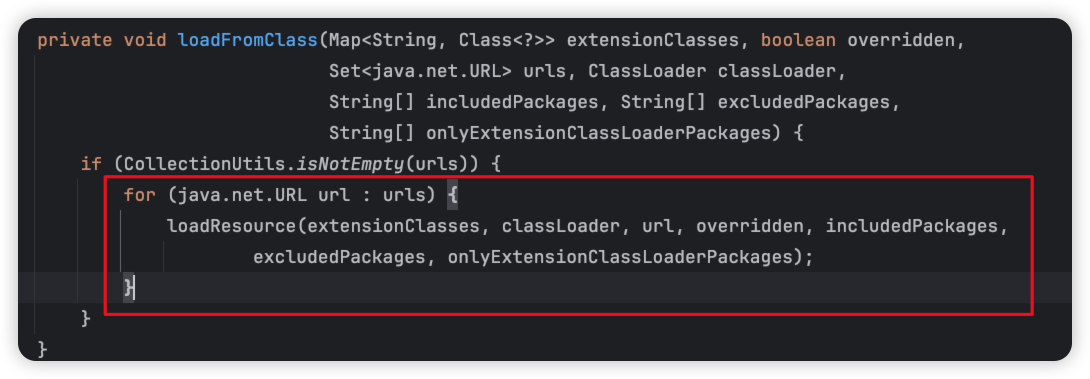
我们接着看loadResource:
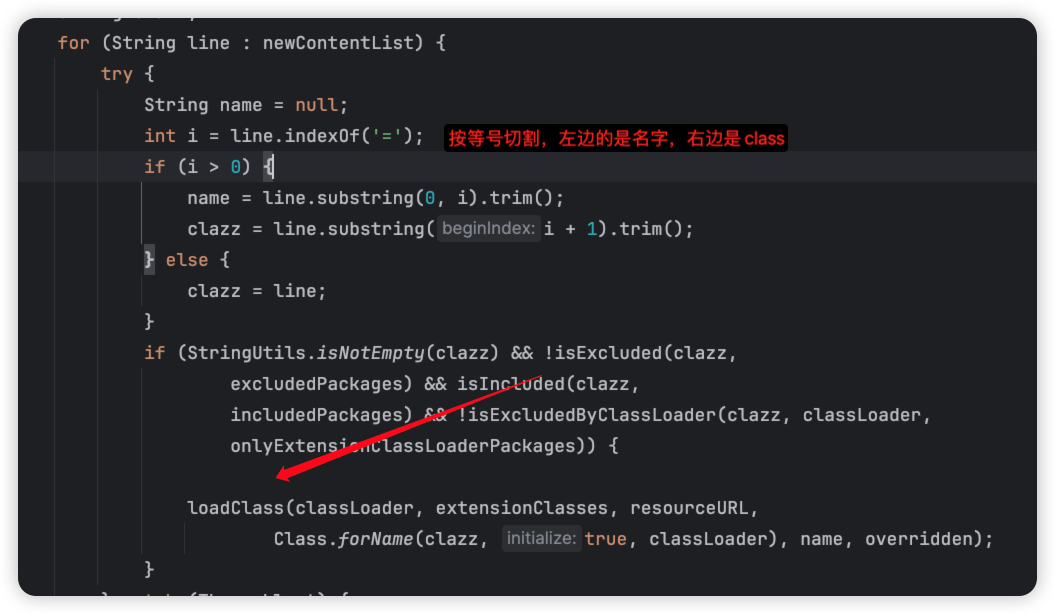
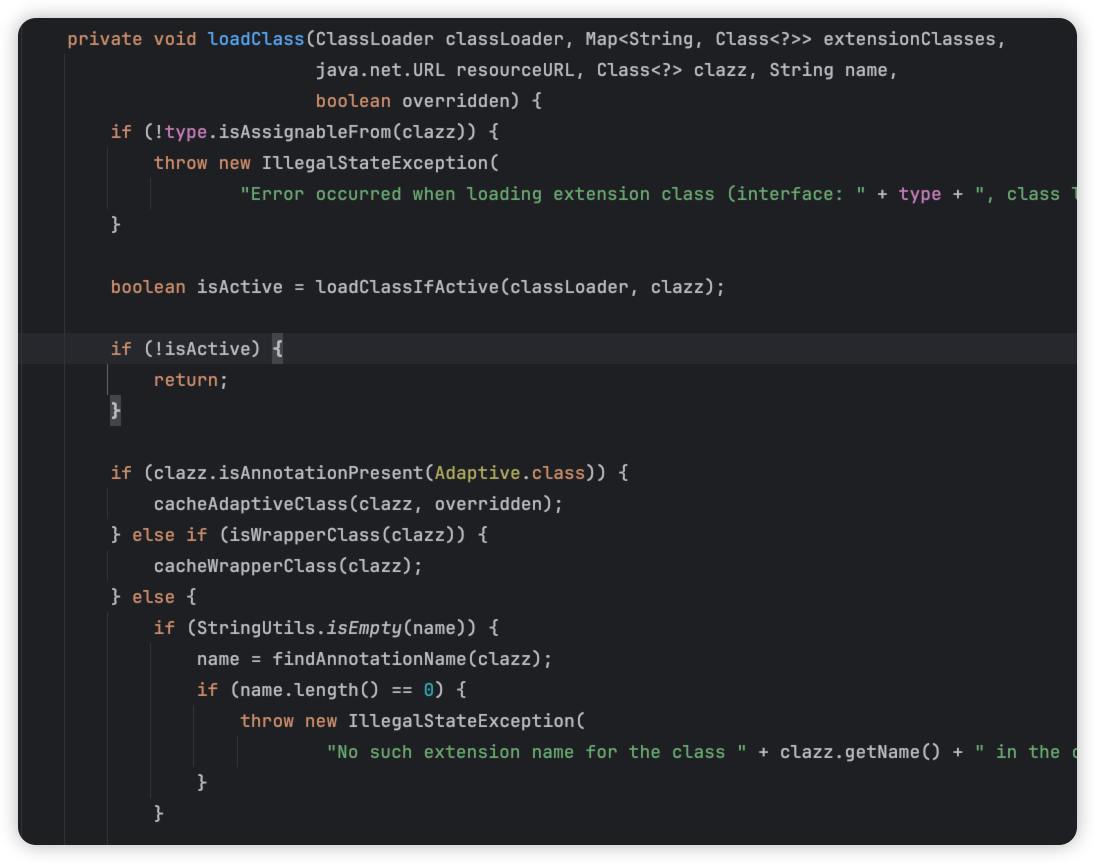
接着进入loadClass加载class。ok,loadClass就是具体对代码进行加载了,比如说有没有被@Adaptive注解啊,是不是Wrapper类啊,或者是其他的等等。
Adaptive 源码
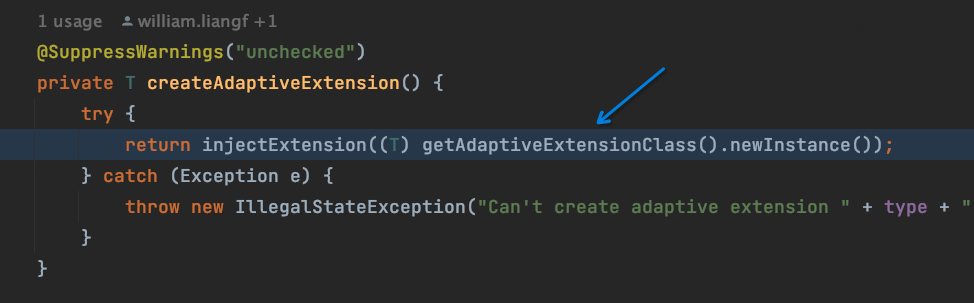
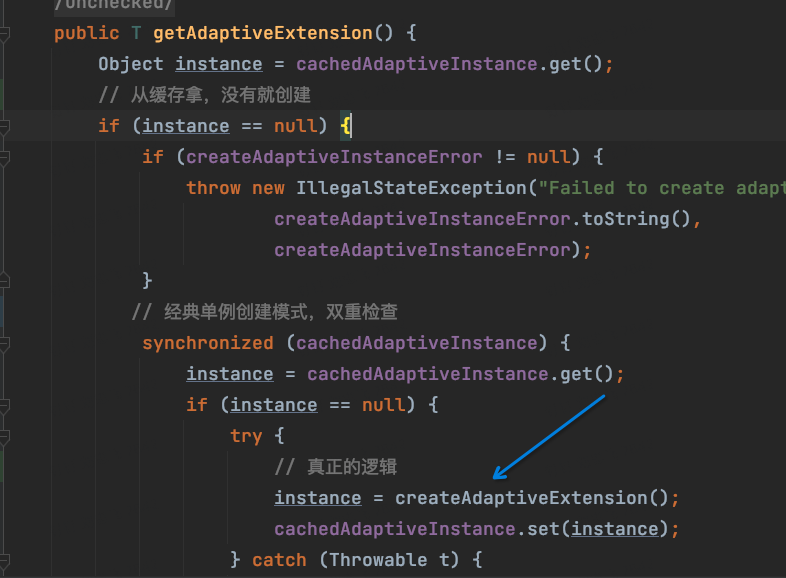
下面我们具体来看源码,实际上,这个源码并不是很复杂:我们把断点打到org.apache.dubbo.common.extension.ExtensionLoader#createAdaptiveExtensionClass
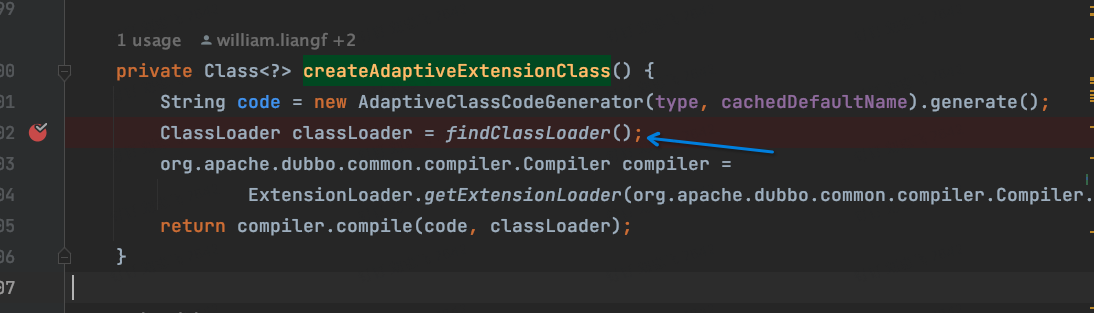
下面是完整的调用链路:

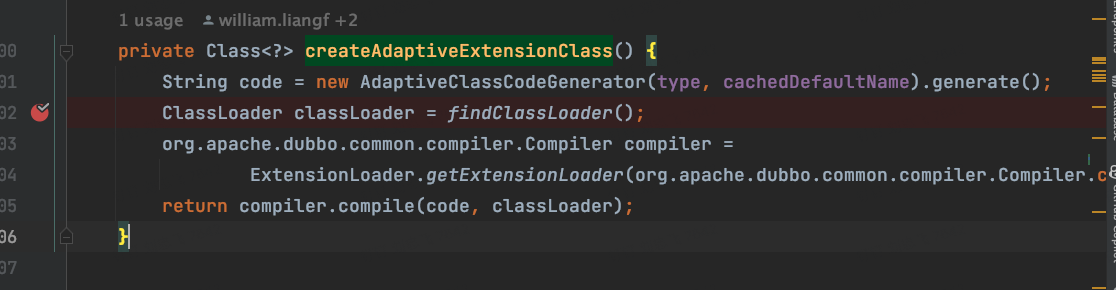
这时候,我们把code拿出来一看,就明白了它的生成逻辑。
package com.yupaopao.dubbo.demo.spi.java;
import org.apache.dubbo.common.extension.ExtensionLoader;
public class Log$Adaptive implements com.yupaopao.dubbo.demo.spi.java.Log {
public void log(java.lang.String arg0) {
throw new UnsupportedOperationException("The method public abstract void com.yupaopao.dubbo.demo.spi.java.Log.log(java.lang.String) of interface com.yupaopao.dubbo.demo.spi.java.Log is not adaptive method!");
}
public void logAdaptive(org.apache.dubbo.common.URL arg0, java.lang.String arg1) {
if (arg0 == null) throw new IllegalArgumentException("url == null");
org.apache.dubbo.common.URL url = arg0;
String extName = url.getParameter("log", "logback");
if (extName == null)
throw new IllegalStateException("Failed to get extension (com.yupaopao.dubbo.demo.spi.java.Log) name from url (" + url.toString() + ") use keys([log])");
com.yupaopao.dubbo.demo.spi.java.Log extension = (com.yupaopao.dubbo.demo.spi.java.Log) ExtensionLoader.getExtensionLoader(com.yupaopao.dubbo.demo.spi.java.Log.class).getExtension(extName);
extension.logAdaptive(arg0, arg1);
}
}
这时候我们接着讲下面的逻辑:
我们看到上面有个编译类,org.apache.dubbo.common.compiler.Compiler,这个Compiler也是通过getAdaptiveExtension来获取的,那么,正好,它是通过在类上使用@Adaptive 来使用的,接下来我们把断点打点loadClass下,根据调用堆栈,可以很清楚的看出,在类上面使用@Adaptive那么,在getAdaptiveExtension不会生成类,而是直接返回这个被Adaptive注解的类实例。
在类上面使用注解

ok, Compiler 这个类我们就不去追究咋实现的了,@Adaptive这个讲得差不多了,接下来我们看:
Wrapper机制实现源码
ok,我们在resources下面的对应文件中加上这一行
wrapper=tech.xixing.dubbo.demo.spi.wrapper.LogWrapper
接着我们把断点卡在这里:
ok,debug 启动!
找到代码中adaptive的测试方法或者自己写一个即可。
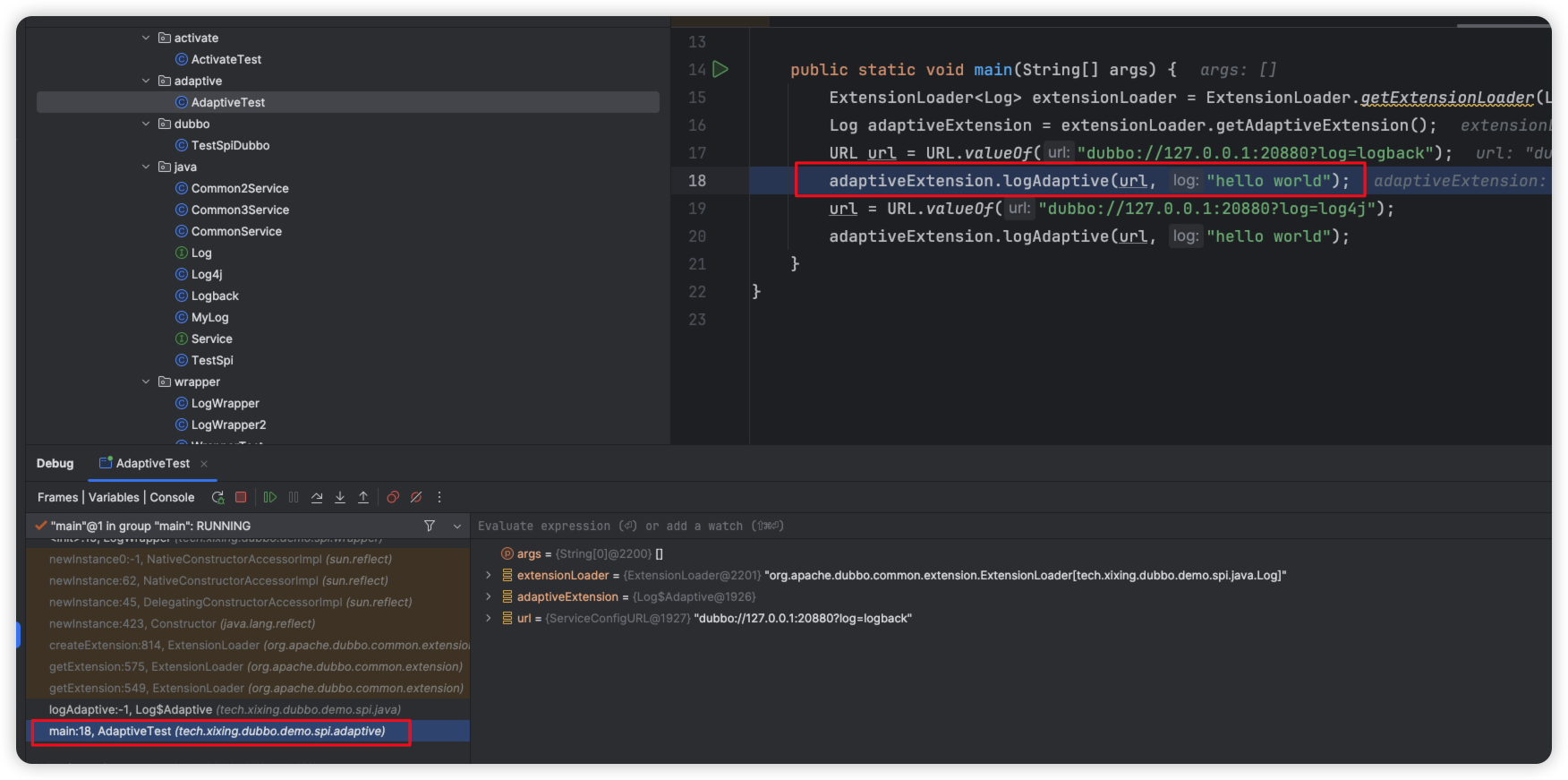
public static void main(String[] args) {
ExtensionLoader<Log> extensionLoader = ExtensionLoader.getExtensionLoader(Log.class);
Log adaptiveExtension = extensionLoader.getAdaptiveExtension();
URL url = URL.valueOf("dubbo://127.0.0.1:20880?log=logback");
adaptiveExtension.logAdaptive(url, "hello world");
url = URL.valueOf("dubbo://127.0.0.1:20880?log=log4j");
adaptiveExtension.logAdaptive(url, "hello world");
}
接下来我们看堆栈:
从最底层开始看起
第一层:可以看到,卡在了adaptiveExtension的logAdaptive方法上。
第二层:是个代理类,我们上次已经说过了,adaptive生成代理类的逻辑。
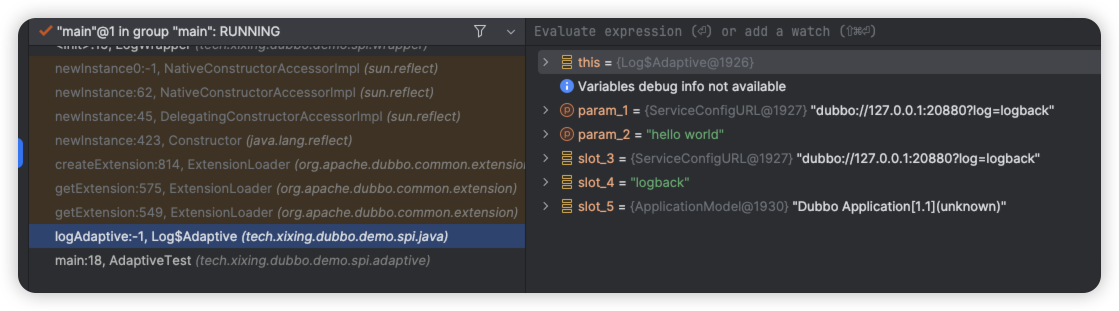
第三层:ok,这时候,到我们核心逻辑里了:

接着我们进去方法,看第四层:
这里调用了createExtension方法。我们即将进这个方法去看看里面到底咋实现的。
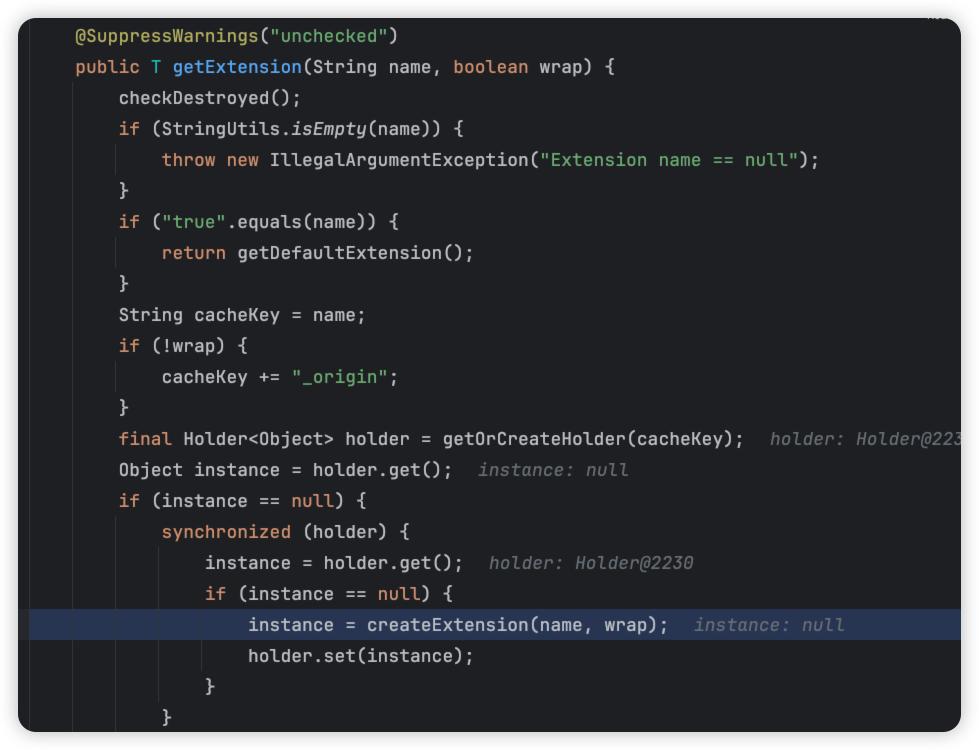
但是笔者想再问大家一个问题,上图出现了一个Holder类,这里holder这个类是用来干嘛的呢。在这里我把holder这个类给各位贴出来。各位有兴趣的可以思考一下holder类的作用好吧。
public class Holder<T> {
private volatile T value;
public void set(T value) {
this.value = value;
}
public T get() {
return value;
}
}
ok,我们接下来往上找堆栈,第五层,可以看到,到了一个wrapperClass,
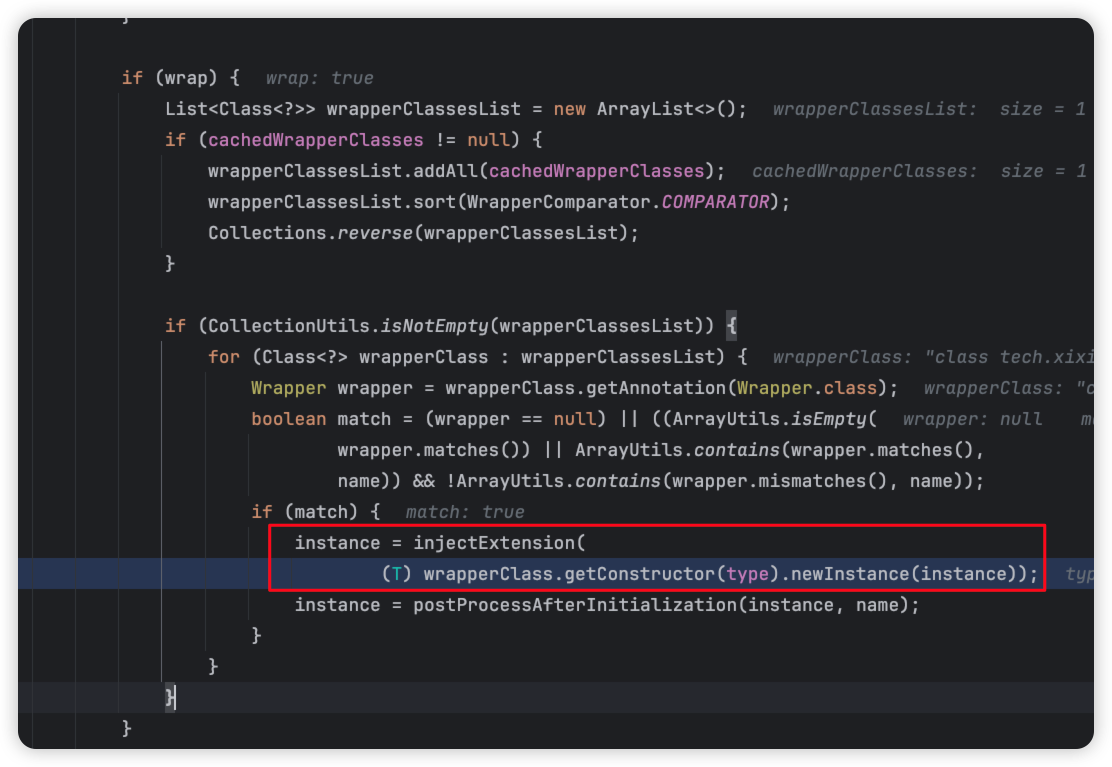
wrapperClass.getConstructor(type).newInstance(instance))。
wrapperClass值是我们刚刚写的那个class

ok,wrapperclass是怎么赋值的呢。我们往上找找:
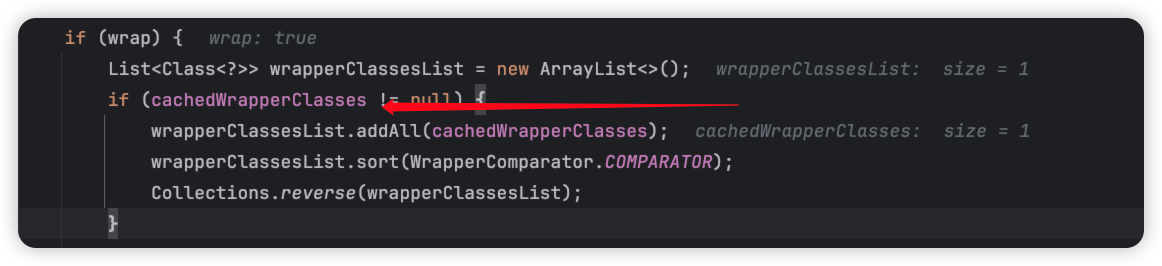
我们接下来找,cachedWrapperClasses是在哪里赋值的。

好的,我们找到了!
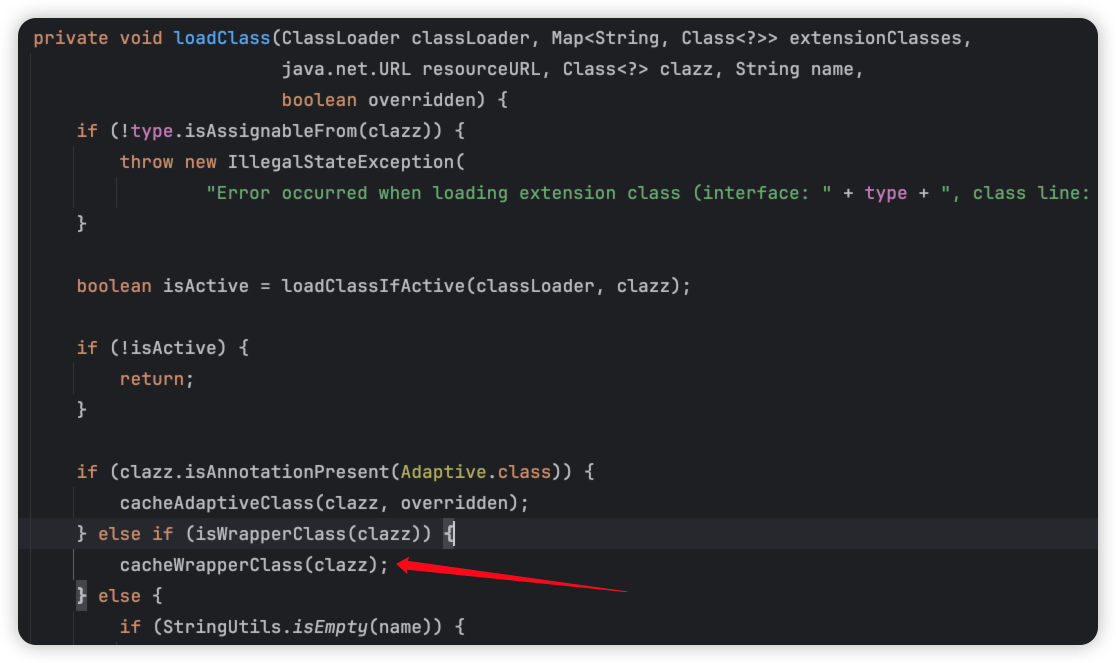
那这个loadClass是 哪里调用的呢。我们回望之前看SPI源码的那里最后,方法走到了这里。
所以初始化的时候,其实就调用了这个方法把Wrapper类当成了包装类。
那怎么判断是不是Wrapper类的呢,其实很简单:
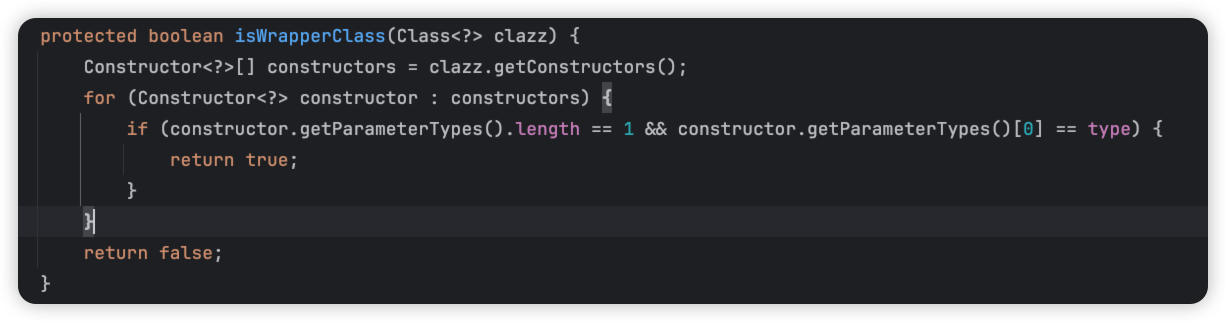
判断构造方法,是不是存在传入一个是自己接口类的构造方法。
好了,Wrapper机制我们讲完啦,大家也可以跟着文中的路径自行debug一下哦,相信你会有所收获的!
Activate全代码解析
activate的机制也是类似的,读者可以一样看loadClass里面最后else部分,这是缓存activate的逻辑。获取逻辑在getActivateExtension里面。篇幅限制。这个就留给读者自行阅读了。















 2821
2821











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









